中国近海地形数据集(渤海,黄海,东海,南海)
收藏地球大数据科学工程2024-03-04 收录
下载链接:
https://data.casearth.cn/sdo/detail/636e17eb819aec5df66b51ce
下载链接
链接失效反馈官方服务:
资源简介:
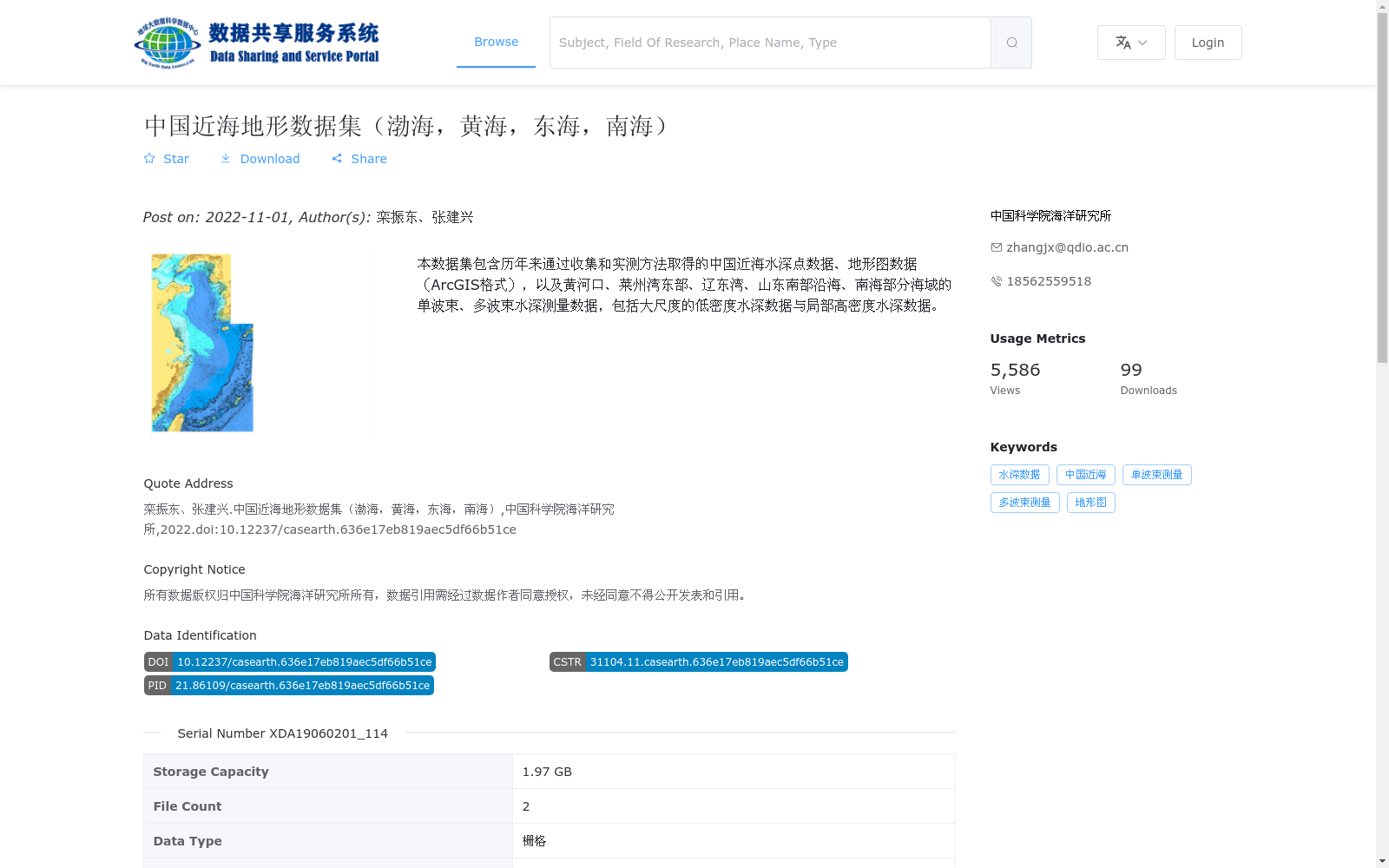
本数据集包含历年来通过收集和实测方法取得的中国近海水深点数据、地形图数据(ArcGIS格式),以及黄河口、莱州湾东部、辽东湾、山东南部沿海、南海部分海域的单波束、多波束水深测量数据,包括大尺度的低密度水深数据与局部高密度水深数据。
This dataset comprises collected and in-situ measured nearshore water depth point data and topographic map data (ArcGIS format) of China across the years, as well as single-beam and multi-beam bathymetric survey data from the Yellow River Estuary, eastern Laizhou Bay, Liaodong Bay, coastal areas of southern Shandong, and parts of the South China Sea, including both large-scale low-density water depth data and local high-density water depth data.
提供机构:
中国科学院海洋研究所
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个覆盖中国渤海、黄海、东海和南海近海区域的地形数据集,主要包含历年来收集和实测的水深点数据、ArcGIS格式地形图,以及多个重点海域的单波束和多波束水深测量数据,兼具大尺度低密度和局部高密度特点。数据以栅格格式存储,总容量1.97 GB,由中国科学院海洋研究所于2022年发布,适用于海洋勘察和地形分析。
以上内容由遇见数据集搜集并总结生成


