OpenAI-4o_t2i_human_preference
收藏Hugging Face2025-03-28 更新2025-03-29 收录
下载链接:
https://huggingface.co/datasets/Rapidata/OpenAI-4o_t2i_human_preference
下载链接
链接失效反馈官方服务:
资源简介:
Rapidata OpenAI 4o偏好数据集,包含超过200,000个人类响应,评估OpenAI 4o在偏好、一致性和对齐性方面的表现,与12个其他模型进行对比。
创建时间:
2025-03-27
搜集汇总
数据集介绍
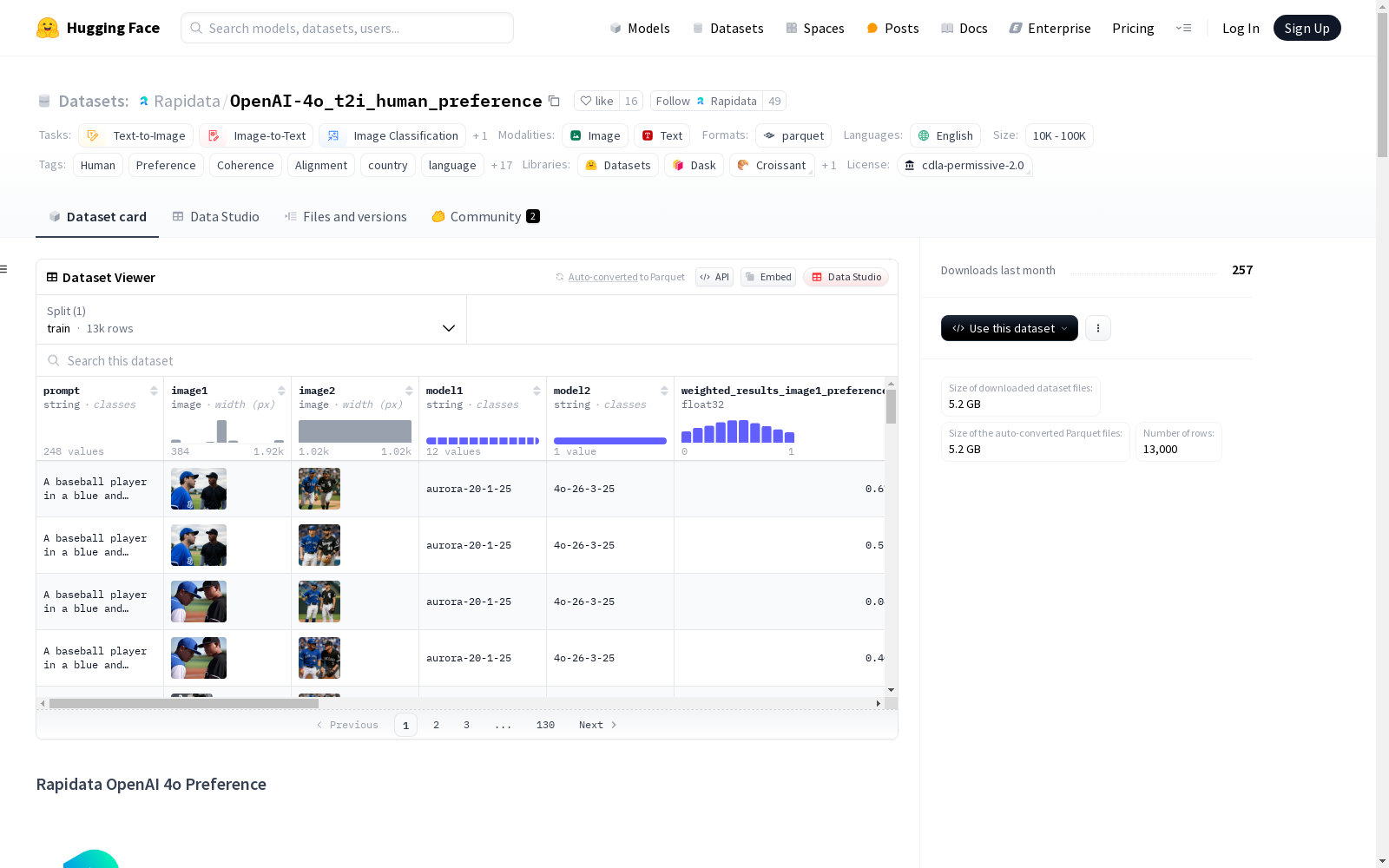
构建方式
在文本到图像生成模型的评估领域,OpenAI-4o_t2i_human_preference数据集通过创新的构建方法为模型性能评估设立了新标准。该数据集采用大规模人类偏好收集策略,借助Rapidata Python API在极短时间内收集了超过20万份人类反馈,涉及来自4.5万名独立标注者的专业评估。数据构建采用严谨的1v1对比实验设计,将OpenAI 4o与12个主流文本生成图像模型进行多维度系统比较,包括Ideogram V2、DALL-E 3等知名模型。评估框架特别设计了包含荒诞提示词的特殊测试集,如'椅子在猫身上'等非常规场景,以检验模型对训练数据外情况的处理能力。
使用方法
该数据集为文本到图像生成模型的研究提供了全面的评估基准。研究者可通过分析不同模型在偏好、连贯性和对齐度三个维度的表现,深入理解各模型的优势与局限。数据集支持多种应用场景:模型开发者可将其作为性能优化的参照标准,通过对比分析找出改进方向;学术研究者可利用其丰富的比较数据开展生成模型的能力边界研究;产业界用户则可参考评估结果选择最适合特定应用场景的模型。使用时应特别注意数据集中包含的特殊测试案例,这些案例为理解模型在极端情况下的表现提供了宝贵线索。数据集采用标准化的结构化存储格式,便于直接整合到现有机器学习流程中进行分析和模型训练。
背景与挑战
背景概述
OpenAI-4o_t2i_human_preference数据集由Rapidata团队于2025年构建,旨在评估OpenAI 4o文本生成图像模型与12种主流模型的性能差异。该数据集通过大规模人类偏好标注,聚焦于生成图像的三大核心维度:视觉偏好性、语义对齐度和逻辑连贯性。作为多模态人工智能领域的重要基准,其创新性体现在采用对抗性提示策略,系统检验模型处理非常规语义关系的能力。数据集收录了来自45,000名标注者的20万条反馈,为生成式AI的评估范式提供了新的方法论视角。
当前挑战
该数据集主要应对文本到图像生成领域的两大挑战:模型对非常规语义的理解能力差异,以及人类审美偏好与算法输出的对齐问题。在构建过程中,研究者需要解决标注一致性控制、跨模型输出标准化比对等技术难题。特别在处理'鱼吃鹈鹕'等反常识提示时,暴露出当前模型在逻辑推理方面的共性缺陷。此外,大规模人类标注引入的主观偏差消除,以及不同文化背景对图像偏好的影响,均为数据集构建过程中的关键挑战。
常用场景
经典使用场景
在生成式人工智能领域,OpenAI-4o_t2i_human_preference数据集为研究者提供了丰富的文本到图像生成模型比较基准。该数据集通过大规模人类偏好评估,系统性地对比了OpenAI 4o与12种主流生成模型在荒诞提示处理、视觉连贯性和语义对齐等维度的表现。其核心价值在于为模型优化提供了基于人类感知的量化指标,特别是在处理非常规语义组合时展现出独特优势。
解决学术问题
该数据集有效解决了生成式AI领域三个关键研究问题:首先通过量化评估揭示了不同模型处理语义冲突提示的能力边界,其次建立了视觉连贯性的客观评价标准,最后为多模态对齐研究提供了人类中心主义的评估范式。这些贡献显著推进了生成模型可解释性研究,并为模型架构优化提供了实证依据。
实际应用
在实际应用层面,该数据集指导了商业图像生成系统的迭代优化。设计平台依据其评估结果改进提示工程策略,广告行业参考人类偏好数据优化视觉内容生成,教育领域则利用其异常提示处理能力开发创新教学工具。特别在需要高语义保真度的医疗可视化等领域,该数据集提供的对齐评估标准具有重要应用价值。
数据集最近研究
最新研究方向
在文本到图像生成领域,OpenAI-4o_t2i_human_preference数据集为研究者提供了丰富的人类偏好数据,涵盖了偏好、一致性和对齐性三个关键维度。该数据集通过大规模人类标注,比较了OpenAI 4o与12种主流文本到图像生成模型的性能,包括Ideogram V2、DALL-E 3和Stable Diffusion 3等。当前研究聚焦于如何利用这些人类反馈数据优化生成模型的对齐能力,特别是在处理荒谬或矛盾提示时的表现。前沿探索方向包括开发更精细的评估指标以量化生成图像的逻辑一致性,以及研究人类偏好与模型架构之间的关联性。这些研究不仅推动了生成模型的技术边界,也为构建更符合人类价值观的AI系统提供了重要参考依据。
以上内容由遇见数据集搜集并总结生成


