WIT 图像-文本数据集
收藏超神经2022-10-27 更新2024-05-15 收录
下载链接:
https://hyper.ai/cn/datasets/18656
下载链接
链接失效反馈官方服务:
资源简介:
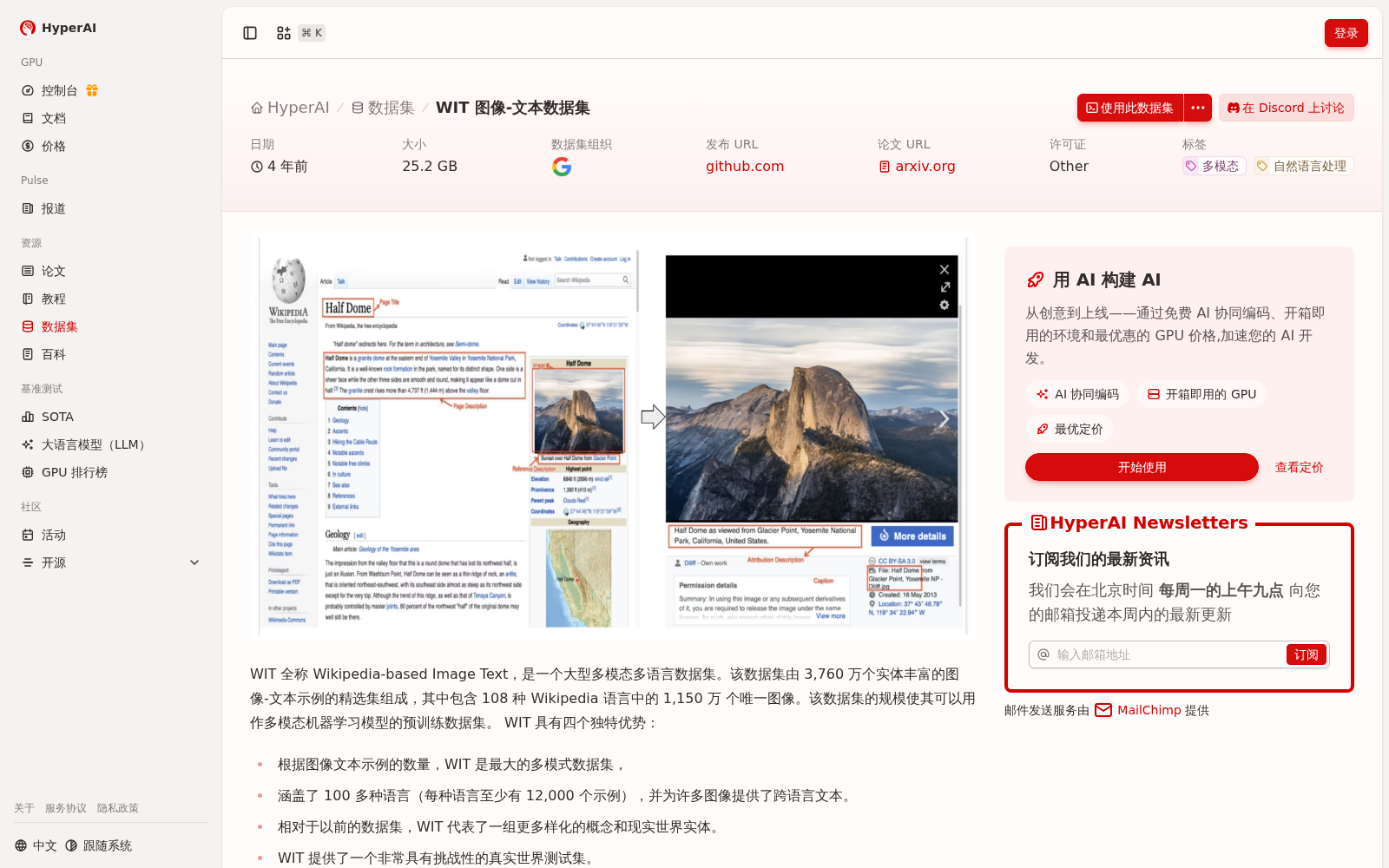
WIT 全称 Wikipedia-based Image Text,是一个大型多模态多语言数据集。该数据集由 3,760 万个实体丰富的图像-文本示例的精选集组成,其中包含 108 种 Wikipedia 语言中的 1,150 万 个唯一图像。该数据集的规模使其可以用作多模态机器学习模型的预训练数据集。
WIT, short for Wikipedia-based Image Text, is a large-scale multilingual multimodal dataset. It comprises a curated collection of 37.6 million entity-rich image-text pairs, which include 11.5 million unique images spanning 108 Wikipedia languages. The scale of this dataset allows it to serve as a pre-training dataset for multimodal machine learning models.
创建时间:
2022-10-21
搜集汇总
数据集介绍
背景与挑战
背景概述
WIT 图像-文本数据集是一个基于Wikipedia的大型多模态多语言数据集,包含约3,760万个图像-文本示例和1,150万个唯一图像,覆盖108种语言,总规模为25.2 GB。该数据集适用于多模态机器学习模型的预训练,并以其多样化的概念和实体为特点。
以上内容由遇见数据集搜集并总结生成


