Fully Open Meditron Corpus
收藏arXiv2026-05-16 更新2026-05-19 收录
下载链接:
https://huggingface.co/datasets/EPFLiGHT/fully-open-meditron
下载链接
链接失效反馈官方服务:
资源简介:
Fully Open Meditron Corpus是由洛桑联邦理工学院LiGHT实验室构建的首个全开放临床决策支持系统数据集,旨在通过可审计的数据管道提升医疗大语言模型的透明度和可复现性。该数据集整合了八个公开医疗问答数据集,并扩展了三个经临床医生审核的合成组件,涵盖考试风格问答、基于临床指南的问答及临床情景案例,通过系统级去污染处理确保与评估基准无重叠。数据构建过程采用临床医生参与的提示工程和GPT-OSS-120B生成技术,并辅以黄金标签拒绝采样控制幻觉。该数据集专门用于训练和评估医疗领域大语言模型,致力于解决临床决策支持系统中数据来源不透明、评估基准污染及医疗场景覆盖不足等关键问题。
The Fully Open Meditron Corpus is the first fully open clinical decision support system dataset developed by the LiGHT Lab at École Polytechnique Fédérale de Lausanne (EPFL). It aims to enhance the transparency and reproducibility of medical large language models (LLMs) through auditable data pipelines. This dataset integrates eight publicly available medical question answering (QA) datasets, and further expands three clinician-audited synthetic components covering exam-style QA, clinical guideline-based QA, and clinical scenario cases. It undergoes systematic decontamination processing to ensure no overlap with evaluation benchmarks. The dataset construction process adopts clinician-involved prompt engineering and GPT-OSS-120B generation technology, supplemented by gold-label rejection sampling to mitigate hallucinations. Specifically designed for training and evaluating medical LLMs, this dataset aims to address key issues in clinical decision support systems, including opaque data sources, evaluation benchmark contamination, and insufficient coverage of medical scenarios.
提供机构:
洛桑联邦理工学院·LiGHT实验室
创建时间:
2026-05-16
原始信息汇总
数据集概述:Fully Open Meditron Corpus
基本信息
- 数据集名称:Fully Open Meditron Corpus
- 许可协议:CC BY-NC 4.0(合成部分);原始数据集保留各自许可
- 语言:英语
- 任务类型:问答、文本生成
- 数据规模:约 601k 条样本(约 1.5 亿 tokens)
- 标签:医疗、临床、医疗保健、大型语言模型、监督微调
数据集构成
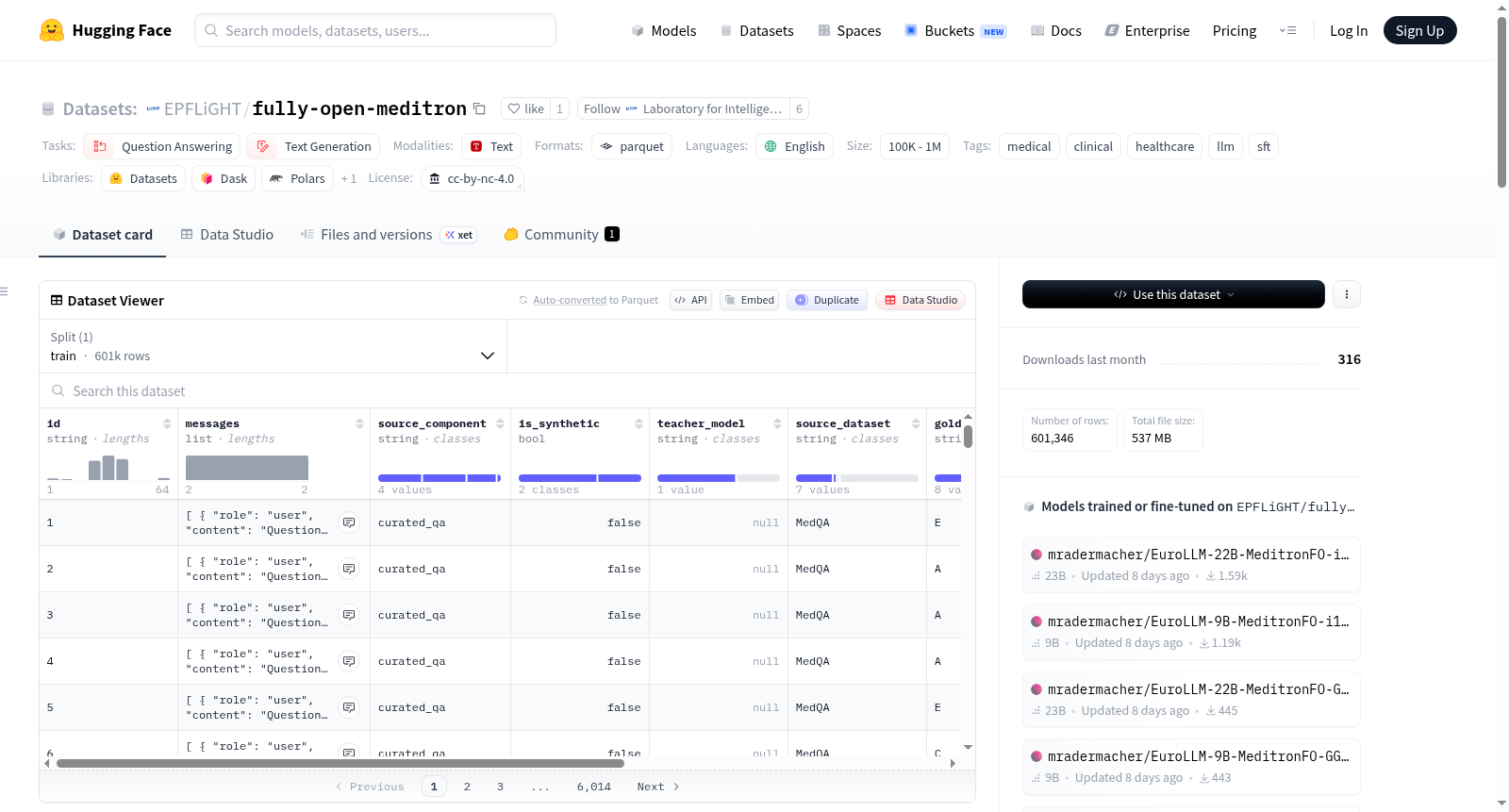
数据集由四个子组件组成,总计 601,346 条样本:
| 子组件 | 样本数量 | 描述 |
|---|---|---|
| curated_qa | 216,546 | 聚合自八个公开医疗问答数据集(MedQA、MedMCQA、PubMedQA、MedExpQA、HealthSearchQA、LiveQA、AfriMed-QA v1/v2),统一转换为 (system, user, assistant) 对话格式,经系统级去污染移除 173 条 |
| synthetic_curated_qa | 214,654 | 基于 curated 池种子生成的新型考试风格问答,由 gpt-oss-120b 生成,按问题类型分层,持续监控答案位置以避免标签偏差 |
| guidelines_qa | 145,681 | 基于 46,469 份来自 16 个全球机构的临床实践指南生成的问答 |
| synthetic_moove | 24,465 | 基于专家编写的临床情景种子提示生成的开放式临床场景,旨在引发复杂诊断推理 |
数据模式
| 字段 | 类型 | 描述 |
|---|---|---|
| id | string | 唯一标识符 |
| messages | list of {role, content} | OpenAI 格式对话,角色包括 system、user、assistant |
| source_component | string | 所属子组件名称(curated_qa、synthetic_curated_qa、guidelines_qa、synthetic_moove) |
| is_synthetic | bool | 是否由 LLM 教师模型生成 |
| teacher_model | string | 教师模型名称(gpt-oss-120b)或 null |
| source_dataset | string | 原始公开数据集名称(仅 curated_qa 行) |
| gold_label | string | 多选题标准答案字母 |
| label_text | string | 多选题标准答案文本 |
| exact_match | bool | 教师模型预测是否在拒绝采样后匹配标准答案 |
| try_count | int | 重采样尝试次数(1–8) |
构建过程
数据集分为三个阶段构建:
- 聚合:将八个公开医疗问答数据集归一化为统一对话模式,无法明确映射的条目被丢弃。
- 临床医生审核的合成生成:由四位医生组成的专家组审查每个少样本生成提示模板的三个样本输出,分歧通过小组讨论解决。审核产生了四项生成流程结构性改进。
- 幻觉缓解:对于每个带标注答案的多选题,通过数据集特定的正则表达式提取预测答案,在温度 0.7 下独立重采样最多 8 次,直至提取的答案与标准答案匹配。
预期用途
- 仅限研究用途:包括可重复性研究、审计和医疗大语言模型的红队测试。
- 不可替代临床判断:基于本数据集训练的模型未经独立领域安全性评估不得部署。
版权说明
- 合成组件(synthetic_curated_qa、guidelines_qa、synthetic_moove)采用 CC BY-NC 4.0 许可。
- curated_qa 组件是对公开数据集的衍生聚合,每种数据集保留其原始许可,用户需查阅相应原始许可。
搜集汇总
数据集介绍
构建方式
在临床决策支持系统亟需高透明度与可审计性的背景下,Fully Open Meditron Corpus的构建始于对八个公开医学问答数据集的系统整合,涵盖MedQA、MedMCQA等来源,统一转化为标准化的对话格式。随后,为弥补公共数据在急诊场景、高危病症等维度的覆盖不足,研究团队借助GPT-OSS-120B模型进行三路精心设计的合成扩展:基于考试风格的问答对、源自46,469份临床实践指南的问答内容,以及启发复杂诊断推理的临床小品文。整个生成过程历经四位临床医师的严格审核与提示词优化,并通过黄金标签拒绝采样与系统性去污染流程确保数据质量与基准独立性。
使用方法
使用者可直接基于Hugging Face平台获取该语料库,并依照论文提供的完整训练框架,将其用于对任意全程开放基础模型进行监督微调。建议训练时保持各模型原生的指令微调模板,并利用语料库内置的系统去污染机制过滤与评估基准的重叠内容。评估阶段,除采用标准的医学多项选择题基准外,推荐结合Auto-MOOVE这一经204名人类评分者校准的自动临床推理评价协议,对模型在开放问答、指南对齐、无害性与公平性等多个维度进行细致评分,从而全面衡量其临床决策支持能力。
背景与挑战
背景概述
全开放医疗语言模型(Fully Open Meditron)是由瑞士洛桑联邦理工学院(EPFL)的LiGHT实验室于2026年推出的首个端到端全开源临床大语言模型构建管线。该数据集由Xavier Theimer-Lienhard、Mary-Anne Hartley等研究人员主导,旨在解决当前医疗大语言模型在透明性与可审计性上的根本缺陷——绝大多数所谓"开放"模型仅公开权重,却隐匿训练数据的来源、筛选流程与生成管线。研究团队通过整合八个公开医疗问答数据集、46,469份临床实践指南以及专家编写的临床案例,构建了涵盖约60万条记录的结构化语料库,并引入医师评审机制对合成数据进行质量把控。该数据集的核心贡献在于建立了完全可复现、可审计的模型训练框架,不仅推动了临床决策支持系统从"黑箱"向"透明化"的范式转变,也为低资源环境、急诊医学等被传统基准忽视的临床场景提供了更均衡的覆盖。Apertus-70B-MeditronFO模型在综合医疗基准上达到53.8%的准确率,创下全开放系统的新高,标志着该领域从重量不重质的开放权重时代迈入全栈透明的可信阶段。
当前挑战
该数据集的核心挑战体现在三个层面。首先,在领域任务层面,传统医疗大语言模型面临数据污染与基准饱和的双重困境——多数评测基准与预训练语料存在显著重叠,导致性能提升可能源于记忆而非真正的临床推理能力;同时,多选问答形式无法捕捉开放场景下的语境感知、沟通能力与患者安全性等关键维度。其次,在数据构建过程中,研究团队面临着在完全开源约束下平衡语料质量与覆盖广度的难题:一方面需避免依赖受限制的临床数据库或未经披露的合成管线,另一方面要克服公共医疗数据集固有的北美与欧洲偏差,通过合成生成将急诊场景覆盖从15.0%提升至38.7%、危及生命病例从8.6%升至31.8%。此外,教师模型(GPT-OSS-120B)可能引入风格化偏见,医师评审虽覆盖生成提示模板但难以穷举每一条合成样本的错误,而去污流程仅聚焦于语法层面而非语义等价变形,这些技术局限性要求持续迭代以构建真正鲁棒且可信的临床决策支持系统。
常用场景
经典使用场景
在临床决策支持系统的构建中,Fully Open Meditron Corpus最为经典的使用场景是作为完全可审计、可复现的医学大语言模型训练与评估的基础语料库。该数据集通过整合八个公开医学问答数据集,并经由临床医师审核的合成数据扩展策略,系统性地覆盖了急诊、重症、基层医疗等以往被低估的临床场景。其独特的价值在于提供了端到端开放的训练管道,使研究者能够在完全透明的数据来源和预处理流程下,训练出面向医学领域的专业化语言模型,从而避免了传统“仅开放权重”模式下数据溯源不清、基准污染等核心痛点。
解决学术问题
该数据集解决了医学人工智能领域长期存在的两大核心学术难题:其一是临床大语言模型训练管道的不可审计性问题,过往多数“开源”模型仅公布权重,而训练数据的来源、筛选逻辑与生成流程均不透明,严重制约了模型行为的可追溯性与可复现验证;其二是传统多项选择式医学基准(如MedQA、MedMCQA)因广泛的数据污染和固化的考试导向,难以真实评估模型的临床推理能力。Fully Open Meditron Corpus通过引入严格的去污染流程、基于临床实践指南的问答生成以及开放式临床小病例评估协议,为建立可信、可审计的医学LLM提供了方法学范式,显著推动了领域内对模型透明性与评估真实性的认知。
实际应用
在实际临床场景中,该数据集驱动的模型已展现出多维度的应用潜力。以Apertus-70B-MeditronFO为例,其在自动开放医学评估(Auto-MOOVE)和HealthBench测试中均超越了原基座模型,甚至在开放式临床交互评估中优于未公开训练数据的MedGemma-27B。这意味着基于该语料库微调的模型能够更准确地理解临床语境、遵循诊疗指南、并生成结构清晰且符合安全规范的应答,可被部署于临床决策支持、医学教育模拟、患者咨询初步筛查等场景。其完全开放的属性也使得医疗机构能够根据本地化需求(如特定地区疾病谱或资源水平)进行二次适配与合规审查,从而实现真正的可落地的临床AI辅助。
数据集最近研究
最新研究方向
在临床大语言模型(LLM)领域,当前最前沿的研究方向聚焦于构建完全开放、可审计且可复现的模型训练管线,以解决传统“开放权重”模型在数据来源、处理流程和评估范式上的不透明性问题。Fully Open Meditron数据集的诞生标志着这一方向的里程碑式突破,它首次在医学领域实现了从基础模型权重、训练代码到临床审核语料库和合成数据管道的端到端完全开放。该工作通过整合八个公共医学问答数据集、引入由临床医生审核的合成覆盖扩展(如基于46,469条临床指南的问答对和开放式临床场景),并采用经204名人类评估者校准的LLM-as-a-judge评价协议,成功使Apertus-70B-MeditronFO模型在综合医学基准上达到53.8%的准确率,创下完全开放模型的新纪录。这一进展不仅论证了在牺牲数据隐私的前提下仍可取得领域专用性能的突破,更为医疗AI的可信、透明和可问责部署提供了范式级的解决方案,对推动低资源环境下的临床决策支持系统具有深远意义。
相关研究论文
- 1Fully Open Meditron: An Auditable Pipeline for Clinical LLMs洛桑联邦理工学院·LiGHT实验室 · 2026年
以上内容由遇见数据集搜集并总结生成


