details_Qwen__Qwen3-8B_v2
收藏Hugging Face2025-05-09 更新2025-05-10 收录
下载链接:
https://huggingface.co/datasets/OALL/details_Qwen__Qwen3-8B_v2
下载链接
链接失效反馈官方服务:
资源简介:
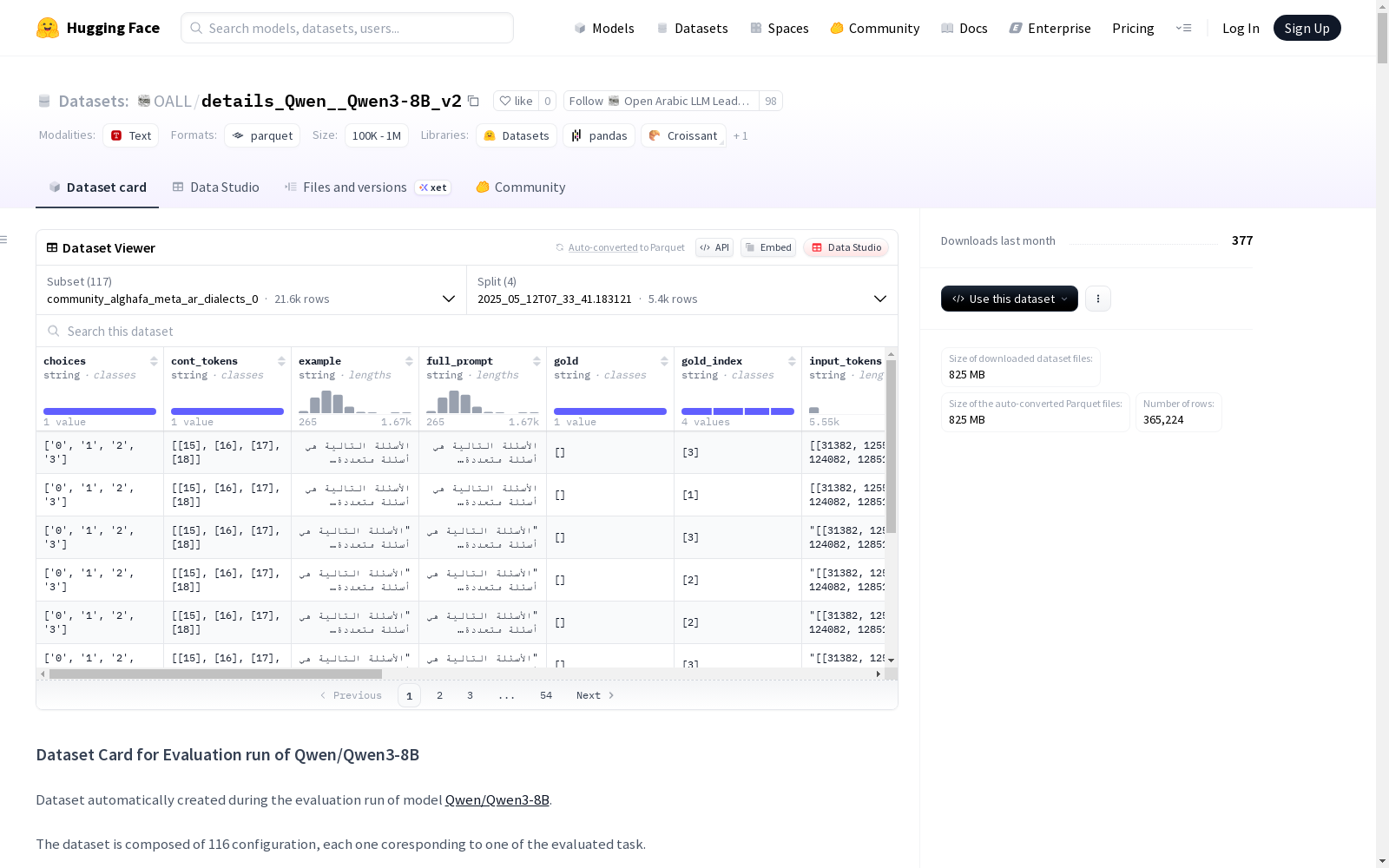
这是一个在Qwen/Qwen3-8B模型评估运行过程中自动创建的数据集。数据集由116个配置组成,每个配置对应一个评估任务。数据集基于3次运行,每次运行都有一个特定的分割,分割名称使用运行的timestamp。'train'分割始终指向最新的结果。还有一个额外的配置名为'results',用于存储所有运行的聚合结果。README文件中还包含了一个使用Python中的datasets库从运行中加载数据的示例。README还提供了关于特定运行的最新结果的信息,包括各种任务的准确性和标准误差。
创建时间:
2025-05-07
搜集汇总
数据集介绍
构建方式
在人工智能模型评估领域,该数据集通过自动化流程构建而成,专门用于记录Qwen/Qwen3-8B模型的多维度性能测试结果。数据集包含116个独立配置单元,每个配置对应特定的评估任务,通过三次独立运行生成完整数据。每次运行结果以时间戳命名的分割形式存储,最新结果始终映射至“train”分割,同时设有专门的“results”配置单元用于聚合所有运行数据。这种分层存储机制确保了评估过程的可追溯性和结果完整性。
特点
该数据集的核心特征体现在其覆盖任务的广泛性和评估指标的精确性上。数据集囊括了从阿拉伯语方言理解到专业学科知识的多元任务,包括阿拉伯语MMLU系列任务、情感分析、事实判断等116个评估维度。每个任务均提供标准化准确率及其标准误差,例如在阿拉伯语会计学任务中准确率为32.43%,而在多选事实判断任务中达到94.67%的优异表现。这种细粒度的性能指标为模型能力评估提供了立体化的观测视角。
使用方法
研究人员可通过HuggingFace数据集库便捷访问该评估数据,使用标准加载接口即可获取特定配置的详细结果。以加载聚合结果为例,通过指定数据集名称、配置单元和分割参数,即可结构化获取模型在各任务上的性能表现。数据集支持按时间戳追溯历史运行记录,同时保持最新结果的实时更新,这种设计使得纵向对比分析和模型迭代追踪成为可能,为学术研究提供持续可靠的数据支撑。
背景与挑战
背景概述
随着大语言模型在多语言理解任务中的广泛应用,针对阿拉伯语等低资源语言的评估需求日益凸显。details_Qwen__Qwen3-8B_v2数据集由OALL团队于2024年构建,专门用于系统评估Qwen3-8B模型在阿拉伯语多领域任务中的表现。该数据集涵盖116项评测任务,涉及语言学、社会科学、自然科学等学科,通过标准化评估框架推动阿拉伯语自然语言处理技术的发展。
当前挑战
该数据集需应对阿拉伯语多方言语义差异与领域知识融合的双重挑战,其构建过程涉及跨学科标注一致性控制与多轮实验数据整合。具体而言,在解决阿拉伯语语义理解问题时,需克服方言变体与标准阿拉伯语的语法差异;在数据集构建阶段,则面临多任务评测指标对齐与时间维度结果溯源的复杂性。
常用场景
解决学术问题
该数据集有效解决了阿拉伯语大模型评估体系缺失的学术难题,通过构建覆盖语言学、社会科学、自然科学等多领域的综合评估矩阵,为衡量模型在低资源语言上的知识迁移能力提供了量化依据。其标准化评估流程显著提升了跨语言模型比较研究的科学性,特别是在处理阿拉伯语方言与现代标准阿拉伯语的语义差异、文化特定内容理解等复杂语言现象时,为突破语言技术壁垒提供了关键数据支撑。
衍生相关工作
围绕该数据集衍生的经典研究形成了阿拉伯语大模型评估的方法论体系,包括基于任务配置的元评估框架设计、多维度性能指标的可解释性分析、以及跨语言迁移学习的基准构建等创新方向。这些工作不仅推动了阿拉伯语自然语言处理技术的标准化进程,更通过开源评估生态的建立,促进了全球研究者在低资源语言人工智能领域的协作创新。
以上内容由遇见数据集搜集并总结生成


