mtob
收藏Hugging Face2026-01-20 更新2026-01-22 收录
下载链接:
https://huggingface.co/datasets/tonychenxyz/mtob
下载链接
链接失效反馈官方服务:
资源简介:
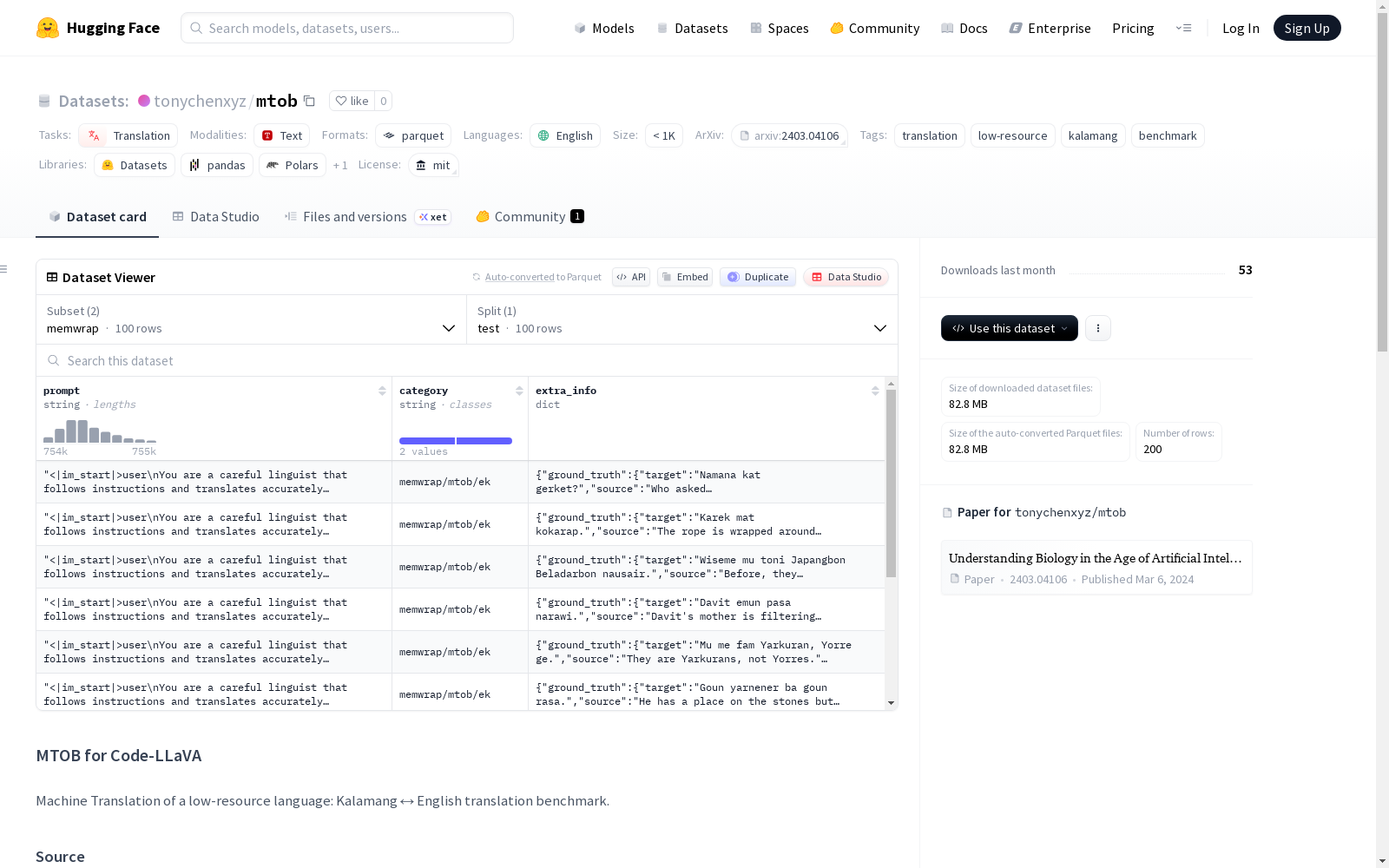
MTOB for Code-LLaVA是一个用于低资源语言Kalamang与英语之间翻译任务的数据集。它包含两种配置:'memwrap'和'plain',分别表示带有和不带有记忆标记的语法教科书内容。数据集的结构包括prompt、category和extra_info等字段,其中extra_info包含ground_truth和scoring_function等信息。数据集的使用和评估方法也进行了详细说明,包括如何加载数据集、过滤数据以及评估翻译质量的指标。此外,数据集还提供了语法教科书和双语词汇表,用于支持Kalamang的语言规则和单词级翻译。
MTOB for Code-LLaVA is a dataset dedicated to the translation task between the low-resource language Kalamang and English. It features two configurations: 'memwrap' and 'plain', which respectively denote grammar textbook content with and without memory markers. The dataset structure includes fields such as prompt, category, and extra_info, where extra_info contains information like ground_truth and scoring_function. The usage and evaluation methodologies of the dataset are elaborated in detail, covering how to load the dataset, filter data, and the metrics for assessing translation quality. Additionally, the dataset also provides grammar textbooks and bilingual glossaries to support the learning of Kalamang linguistic rules and word-level translation.
创建时间:
2026-01-07
原始信息汇总
数据集概述
基本信息
- 数据集名称: MTOB for Code-LLaVA
- 托管地址: https://huggingface.co/datasets/tonychenxyz/mtob
- 许可证: mit
- 主要任务类别: 翻译
- 涉及语言: 英语 (en)、Kalamang
- 标签: 翻译、低资源语言、kalamang、基准测试
- 数据规模: n<1K
数据来源与背景
- 核心论文: MTOB: A Benchmark for Learning to Translate from Textbooks
- 基础内容: 基于Kalamang语法和词汇
数据集结构
数据集提供两种配置:
- 配置名称:
memwrap- 描述: 语法教科书内容被包裹在
<|memory_start|>/<|memory_end|>标记中。 - 数据文件:
memwrap/test-* - 注意: 仅语法教科书在记忆块内,词汇表和指令在外部。
- 描述: 语法教科书内容被包裹在
- 配置名称:
plain- 描述: 相同内容,但不包含记忆标记(作为基线)。
- 数据文件:
plain/test-*
两种配置均仅包含test分割。
数据字段说明
通用字段(两种配置共有)
prompt: 聊天模板化的提示字符串。category: 格式为{variant}/mtob/{direction},其中direction是ek(英语→Kalamang)或ke(Kalamang→英语)。extra_info: 一个结构体,包含:ground_truth: 包含target(目标文本)、source(源文本)、direction(翻译方向)、url、original_id。scoring_function: 评分函数,值为mtob_translation。variant: 变体信息。
配置详情
memwrap 配置
- 特征:
prompt: stringcategory: stringextra_info: struct
- 分割信息:
- 分割名称: test
- 样本数量: 100
- 数据集大小: 75694063 字节
- 下载大小: 40918120 字节
plain 配置
- 特征:
prompt: stringcategory: stringextra_info: struct
- 分割信息:
- 分割名称: test
- 样本数量: 100
- 数据集大小: 75690463 字节
- 下载大小: 40926263 字节
使用方式
python from datasets import load_dataset
加载 memwrap 变体
ds = load_dataset("tonychenxyz/mtob", "memwrap", split="test")
按方向过滤数据
eng_to_kal = ds.filter(lambda x: "ek" in x["category"]) kal_to_eng = ds.filter(lambda x: "ke" in x["category"])
评估方法
评分函数 (mtob_translation) 计算以下指标:
exact_match: 精确字符串匹配(不区分大小写,经过标准化)。chrf: 字符n-gram F分数。
数据统计
- 每个翻译方向(E→K 和 K→E)的翻译对。
- 语法教科书提供了Kalamang的语言规则。
- 双语词汇表用于单词级翻译。
搜集汇总
数据集介绍
构建方式
在低资源语言翻译研究领域,MTOB数据集的构建依托于卡兰芒语(Kalamang)的语法教材与双语词汇表。该数据集通过两种配置呈现:memwrap版本将语法教材内容置于特定记忆标记之间,而plain版本则移除了这些标记,作为基础对照。构建过程中,仅语法教材被纳入记忆块,词汇表与翻译指令则置于外部,确保了翻译任务的结构化与可评估性。
特点
MTOB数据集聚焦于卡兰芒语与英语之间的双向翻译,其核心特点在于整合了系统的语法规则与词汇资源,为低资源语言机器翻译提供了语言学支撑。数据集包含100个测试样本,每个样本均标注了翻译方向(英语至卡兰芒语或反之)及详细的元信息,如原始文本来源与评估函数。这种设计使得数据集不仅适用于翻译性能的量化评估,还能促进模型对语言结构的理解与泛化。
使用方法
使用MTOB数据集时,可通过Hugging Face的datasets库加载指定配置,例如memwrap或plain版本,并依据翻译方向筛选样本。评估过程采用内置的mtob_translation评分函数,计算精确匹配率与字符n-gram F分数,从而全面衡量翻译质量。研究人员可借助该数据集测试模型在低资源语言场景下的翻译能力,尤其关注语法规则与词汇知识的整合效果。
背景与挑战
背景概述
在低资源语言机器翻译研究领域,数据稀缺性长期制约着模型性能的提升。MTOB数据集由研究人员于2024年提出,其核心研究问题聚焦于如何利用结构化教材知识来增强机器翻译系统对低资源语言的理解与生成能力。该数据集以Kalamang语——一种使用人口稀少的巴布亚语言——为研究对象,通过整合语法教科书与双语词汇表,构建了英语与Kalamang语之间的双向翻译基准。这一创新性尝试为探索知识增强型翻译模型提供了重要实验平台,推动了低资源语言处理从单纯数据驱动向知识与数据融合范式的转变。
当前挑战
MTOB数据集所针对的低资源语言翻译任务,本身面临着语言结构复杂、可用平行语料极度匮乏等固有挑战。在构建过程中,研究者需克服教材知识结构化整合的难题,即将语法规则与词汇信息有效编码为模型可理解的提示格式。同时,评估机制的设计需兼顾翻译结果的准确性与语言学合理性,传统的自动评价指标在捕捉低资源语言细微语法差异方面存在局限性。此外,如何平衡记忆标记引入的上下文信息与模型泛化能力,避免过拟合于特定教材内容,亦是该基准测试需要解决的关键问题。
常用场景
经典使用场景
在低资源机器翻译研究领域,MTOB数据集被广泛用于评估模型在卡兰芒语与英语之间的双向翻译性能。该数据集通过提供语法教科书和双语词汇,模拟了真实语言学习环境,使研究者能够测试模型在有限数据下理解和应用语言规则的能力。其经典使用场景包括评测大型语言模型或专门翻译系统在低资源语言对上的泛化表现,特别是在结合外部知识(如语法规则)时的翻译准确性。
实际应用
在实际应用中,MTOB数据集支持了针对濒危语言卡兰芒语的翻译工具开发,有助于语言文档化和教育资源的创建。例如,它可以用于构建辅助语言学习的应用程序,或集成到多语言信息检索系统中,提升低资源语言社区的数字化访问能力。此外,该数据集为跨语言通信平台提供了基准测试,推动了技术在语言多样性保护方面的实际落地。
衍生相关工作
围绕MTOB数据集,衍生了一系列经典研究工作,主要集中在记忆增强翻译和低资源语言处理领域。例如,基于其记忆包装配置的研究探索了如何将语法教科书作为外部知识源整合到翻译模型中,以提高翻译质量。这些工作进一步扩展了上下文学习、少样本翻译等方向,为后续低资源语言基准数据集的设计提供了重要参考。
以上内容由遇见数据集搜集并总结生成


