llama3-1b-closedqa-eval-by-claude3sonnet
收藏Hugging Face2025-04-02 更新2025-04-02 收录
下载链接:
https://huggingface.co/datasets/llama-duo/llama3-1b-closedqa-eval-by-claude3sonnet
下载链接
链接失效反馈官方服务:
资源简介:
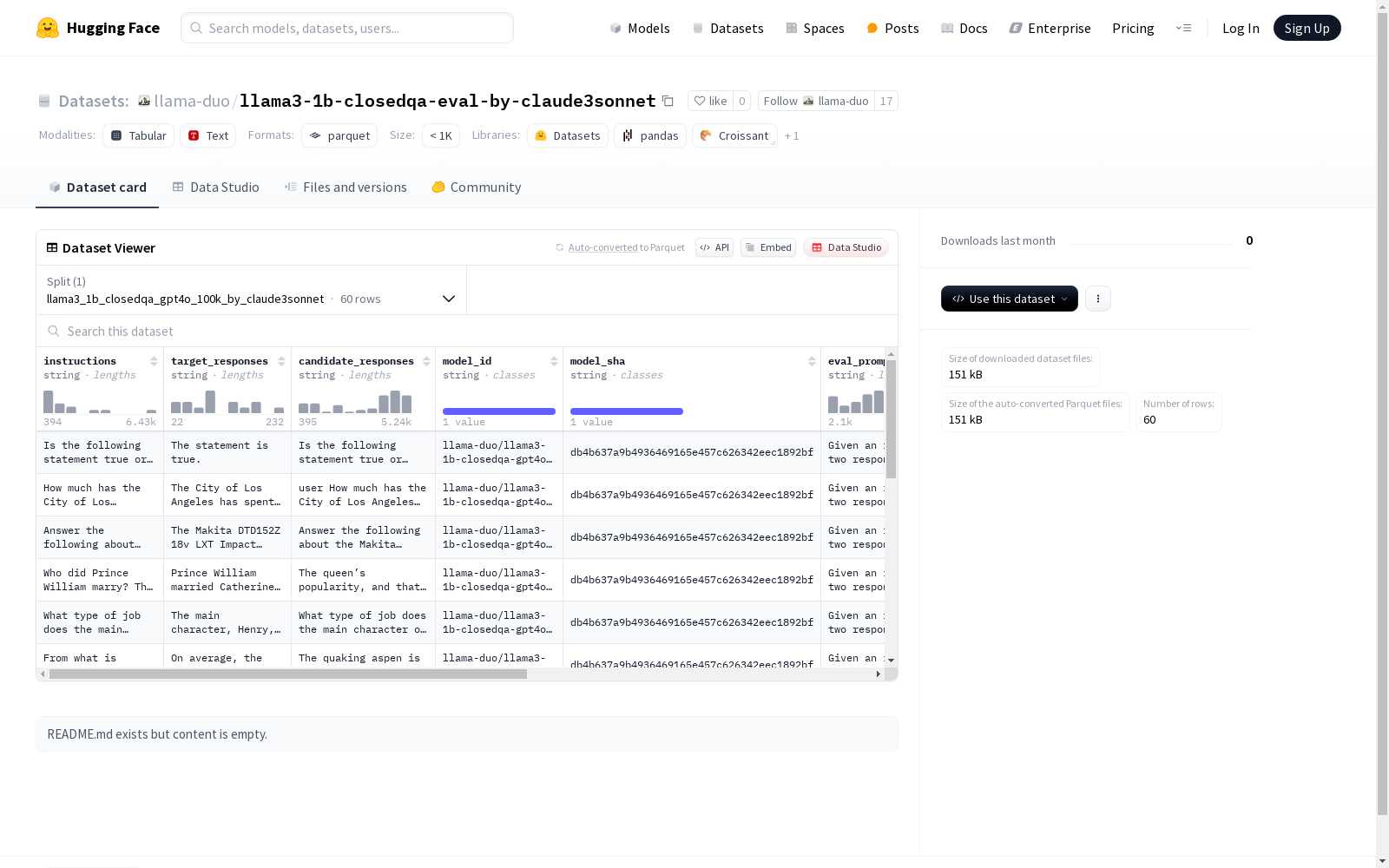
该数据集包含了指令、目标响应、候选响应等字符串类型的数据,以及模型ID、模型SHA、评估提示、相似度评分、精确度评分和评估者等信息。数据集分为不同部分,其中一个部分名为'llama3_1b_closedqa_gpt4o_100k_by_claude3sonnet',包含60个示例。
This dataset includes string-type data fields such as instructions, target responses, and candidate responses, alongside metadata entries including model ID, model SHA, evaluation prompts, similarity scores, precision scores, and evaluators. The dataset is divided into multiple partitions, one of which is named 'llama3_1b_closedqa_gpt4o_100k_by_claude3sonnet' and contains 60 examples.
提供机构:
llama-duo创建时间:
2025-04-02
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量评估数据集的构建对模型性能验证至关重要。该数据集采用严谨的构建流程,通过Claude3 Sonnet模型对Llama3-1B模型在封闭式问答任务中的表现进行系统评估。数据采集过程包含60个精心设计的问答实例,每个实例均包含原始指令、目标响应、候选响应及详细的评估指标,确保评估维度的全面性。数据标注环节整合了多种评分标准,包括相似度分数和精确度分数,为模型性能分析提供多角度参考依据。
特点
作为专门针对大语言模型评估设计的数据集,其显著特点体现在多维度的评估体系构建。数据集不仅包含模型生成的候选回答,还记录了GPT-4等先进模型提供的目标回答作为基准参考。特征字段设计科学完备,涵盖模型标识符、评估提示语、评估者信息等元数据,支持深度的模型表现溯源分析。时间戳信息的保留使得数据集具备纵向研究价值,可追踪模型性能的演进趋势。
使用方法
该数据集为研究人员提供了标准化的模型评估框架。使用时可重点关注相似度分数和精确度分数的对比分析,这两个核心指标能有效反映生成文本在语义相关性和事实准确性方面的表现。数据集采用分块存储设计,支持灵活加载特定评估子集。建议结合模型标识符和评估时间进行交叉分析,以探究不同模型版本或不同时期的表现差异。评估提示语字段为后续研究提供了可复用的评估标准模板。
背景与挑战
背景概述
随着大规模语言模型的快速发展,评估其性能成为自然语言处理领域的关键课题。llama3-1b-closedqa-eval-by-claude3sonnet数据集应运而生,专注于闭卷问答场景下的模型响应质量评估。该数据集由Claude3 Sonnet团队构建,通过系统化收集指令、目标响应和候选响应,为语言模型的自动评估提供了标准化基准。其创新性在于整合了多维度评分体系,包括相似度分数和精确度分数,为研究者深入分析模型在知识检索和语言生成方面的表现提供了重要工具。
当前挑战
闭卷问答评估面临的核心挑战在于如何建立客观且全面的评价标准。该数据集试图解决模型在缺乏外部知识检索情况下,仅凭参数化知识生成准确回答的能力评估难题。在构建过程中,研究人员需要克服候选响应多样性控制、评分者一致性维护以及跨模型可比性保障等技术障碍。同时,保持评估提示词的中立性和有效性,避免引入评估偏差,也是数据集构建过程中需要特别关注的问题。
常用场景
经典使用场景
在自然语言处理领域,llama3-1b-closedqa-eval-by-claude3sonnet数据集为封闭式问答系统的性能评估提供了标准化基准。该数据集通过精心设计的指令集和目标响应,使研究人员能够系统地比较不同语言模型生成的候选回答质量。其内置的相似度评分和精确度评分机制,为模型在语义理解和信息准确性方面的表现提供了量化依据。
解决学术问题
该数据集有效解决了大语言模型评估中缺乏标准化测试框架的难题。通过提供多维度评估指标和人工标注的参考回答,研究人员能够客观衡量模型在封闭式问答任务中的语义保持能力和事实准确性。这种结构化评估方法显著提升了模型对比实验的可重复性,为语言理解领域的基准测试研究提供了重要数据支撑。
衍生相关工作
基于该数据集衍生的研究包括多模态问答评估框架构建、跨语言封闭式问答系统开发等方向。部分团队扩展了原始数据集的评估维度,加入了事实核查和逻辑一致性等新指标。这些工作推动了自动问答系统评估从单一分数向多维度综合测评的范式转变,形成了新一代评估标准体系。
以上内容由遇见数据集搜集并总结生成


