line-test-cache
收藏Hugging Face2025-12-18 更新2025-12-19 收录
下载链接:
https://huggingface.co/datasets/jwidmer/line-test-cache
下载链接
链接失效反馈官方服务:
资源简介:
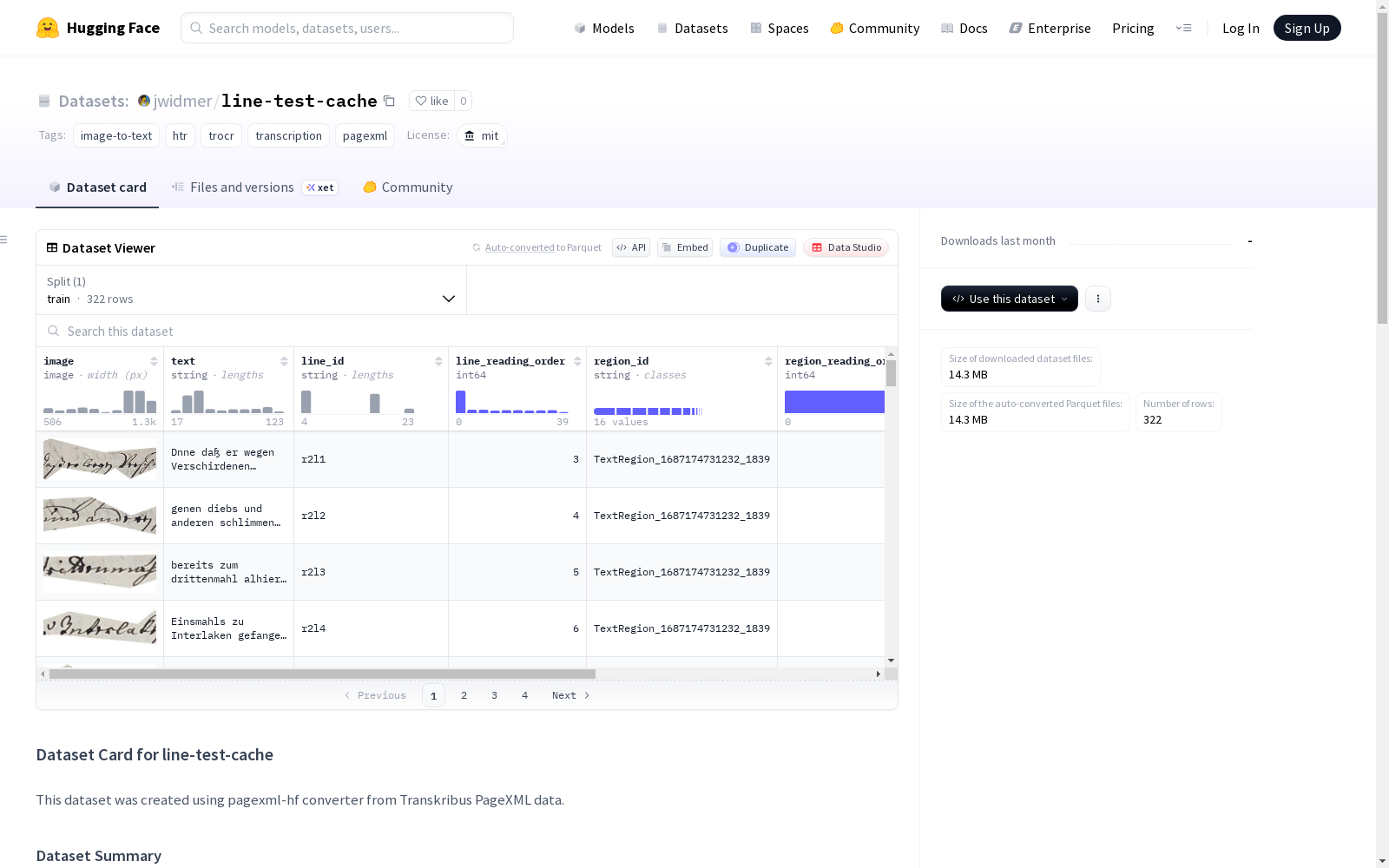
该数据集是使用pagexml-hf转换器从Transkribus PageXML数据创建的。包含485个样本,分为1个训练集。包含来自两个项目的样本:B_IX_490_duplicated和export_doc2_modell_training_casanatense_pagexml_202507041437。数据集特征包括:图像、文本、行ID、行阅读顺序、区域ID、区域阅读顺序、区域类型、文件名和项目名称。数据以parquet格式存储,并按项目和分片组织。
创建时间:
2025-12-18
原始信息汇总
数据集概述
基本信息
- 数据集名称: line-test-cache
- 创建方式: 使用 pagexml-hf 转换器从 Transkribus PageXML 数据创建
- 许可证: MIT
- 标签: image-to-text, htr, trocr, transcription, pagexml
数据集规模
- 总样本数: 485
- 数据分割: 仅包含一个 "train" 分割,样本数为 485
- 下载大小: 112,923,520 字节
- 数据集大小: 112,923,520 字节
- 近似总大小: 107.69 MB
包含的项目
- B_IX_490_duplicated
- export_doc2_modell_training_casanatense_pagexml_202507041437
数据结构与特征
数据特征
- image: 图像数据,类型为
Image(mode=None, decode=False) - text: 文本字符串,类型为
Value(string) - line_id: 行标识符,类型为
Value(string) - line_reading_order: 行阅读顺序,类型为
Value(int64) - region_id: 区域标识符,类型为
Value(string) - region_reading_order: 区域阅读顺序,类型为
Value(int64) - region_type: 区域类型,类型为
Value(string) - filename: 文件名,类型为
Value(string) - project_name: 项目名称,类型为
Value(string)
数据组织
数据按分割和项目组织为 Parquet 分片:
data/ ├── <split>/ │ └── <project_name>/ │ └── <timestamp>-<shard>.parquet
HuggingFace Hub 在加载数据集时会自动合并所有 Parquet 文件。
使用方法
python from datasets import load_dataset
加载整个数据集
dataset = load_dataset("jwidmer/line-test-cache")
加载特定分割
train_dataset = load_dataset("jwidmer/line-test-cache", split="train")
搜集汇总
数据集介绍
构建方式
在历史文档数字化与手写文本识别领域,line-test-cache数据集通过Transkribus平台中的PageXML格式数据转换而来。具体构建过程采用了pagexml-hf转换工具,将原始的PageXML标注文件系统性地转化为适用于机器学习任务的标准化格式。数据以分片Parquet文件形式组织,并按项目名称与时间戳进行归档,确保了数据结构的清晰性与可扩展性。这一构建方式不仅保留了文档的版面结构信息,如行与区域的标识及阅读顺序,也为后续的模型训练提供了高质量的图像-文本配对样本。
使用方法
使用该数据集时,研究人员可通过Hugging Face的datasets库便捷加载。典型操作包括调用load_dataset函数并指定数据集名称以加载完整数据,或通过split参数选取特定分割如训练集。加载后的数据可直接用于图像到文本的端到端训练,尤其适合手写文本识别模型的开发。得益于Parquet格式与自动合并机制,数据访问高效且无缝。用户可依据行或区域的元数据信息进行样本筛选或批次构建,从而灵活支持不同粒度转录任务的实验需求。
背景与挑战
背景概述
在文档分析与数字人文领域,手写文本识别(HTR)技术对于历史文献的数字化与可访问性至关重要。line-test-cache数据集由研究人员或机构通过Transkribus PageXML数据转换工具创建,专注于图像到文本的转录任务,其核心研究问题在于提升手写文档行级文本的自动识别精度与效率。该数据集的出现,为基于Transformer的OCR模型如TrOCR提供了专门的评估与训练资源,推动了文化遗产保护与自动化转录技术的发展,增强了相关领域的研究基础与应用潜力。
当前挑战
该数据集旨在解决手写文本识别中行级转录的挑战,包括处理复杂版面布局、多样书写风格以及历史文档的退化问题。构建过程中,数据源自特定项目如B_IX_490_duplicated,样本量有限仅485个,可能面临数据代表性不足、标注一致性维护以及跨项目格式整合的困难,这些因素共同制约了模型泛化能力与大规模应用的可行性。
常用场景
经典使用场景
在文档分析与手写文本识别领域,line-test-cache数据集为研究者提供了一个标准化的评估基准。该数据集通过PageXML格式整合了图像与文本的对应关系,特别适用于训练和验证基于深度学习的端到端手写文本识别模型。其经典使用场景包括对历史文档或手写笔记的自动转录,模型能够依据图像中的行级标注,精准识别并输出对应的文本内容,为古籍数字化和档案管理提供了关键技术支撑。
解决学术问题
该数据集有效解决了手写文本识别中常见的学术研究问题,如文本行检测与分割、复杂版面分析和多语言手写体识别等。通过提供精确的行级标注和阅读顺序信息,它支持模型学习文档的结构化特征,从而提升识别准确率。其意义在于推动了光学字符识别技术向更细粒度的行级识别发展,并为跨领域的历史文献研究提供了可靠的数据基础,促进了文化遗产的数字化保存与传播。
实际应用
在实际应用层面,line-test-cache数据集被广泛部署于图书馆、档案馆和博物馆的数字化项目中。例如,在历史手稿的自动化转录过程中,该数据集帮助开发系统快速提取文本内容,辅助学者进行文献分析和内容检索。此外,它还可用于教育领域的智能阅卷系统或医疗记录的手写识别,提升信息处理效率,降低人工成本,实现文档管理的智能化转型。
数据集最近研究
最新研究方向
在文档图像分析与手写文本识别领域,line-test-cache数据集凭借其源自Transkribus PageXML的精细标注结构,正推动着基于深度学习的端到端识别模型的前沿探索。当前研究热点聚焦于利用该数据集中的行级图像与文本对齐信息,优化如TrOCR等Transformer架构的预训练与微调策略,以提升对历史文献及复杂版式文档的转录准确率。同时,结合区域类型与阅读顺序等结构化元数据,学者们致力于开发多模态理解模型,旨在实现文档内容的语义重构与智能检索,这对于文化遗产数字化保护与知识图谱构建具有深远意义。
以上内容由遇见数据集搜集并总结生成


