sakusakumura/databricks-dolly-15k-ja-scored
收藏Hugging Face2023-06-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/sakusakumura/databricks-dolly-15k-ja-scored
下载链接
链接失效反馈官方服务:
资源简介:
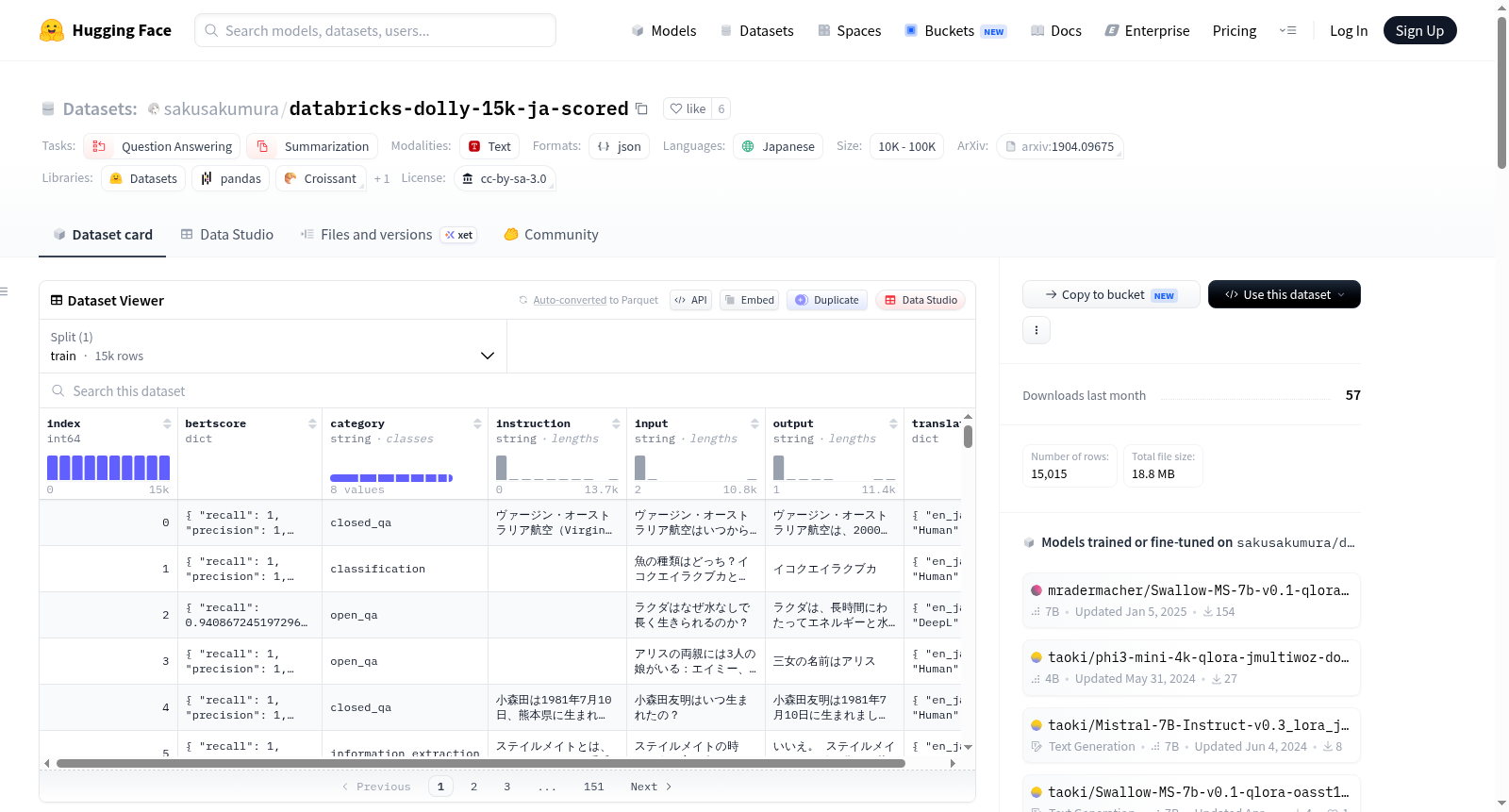
`databricks-dolly-15k-ja-scored`数据集是`kunishou/databricks-dolly-15k-ja`的派生版本,增加了由BERTScore提供的翻译质量评分。该数据集主要用于问答和摘要任务,语言为日语,规模在10K到100K之间。数据集在学术和商业用途下均可使用,遵循CC BY-SA 3.0许可证。数据集的翻译质量通过BERTScore进行评估,评分包括precision、recall和f1 score,用于过滤低质量数据。数据集还包含了各个字段的详细说明,如index、bertscore和translator。
提供机构:
sakusakumura
原始信息汇总
数据集概述
数据集名称
databricks-dolly-15k-ja-scored
数据集来源
该数据集是kunishou/databricks-dolly-15k-ja的衍生版本,通过BERTScore增加了翻译质量评分。
数据集内容
该数据集包含通过机器翻译自databricks-dolly-15k的数据,并附有翻译质量评分。主要问题包括:
input和output完全相同的数据。output直接复制instruction的数据。- 由于表记不一致导致表达不一致的数据。
- 固有名词等翻译错误的数据。
数据集质量
通过BERTScore评估,提供了precision、recall和f1 score的评分,用于过滤低质量数据。
数据集应用
适用于学术和商业用途,根据Creative Commons Attribution-ShareAlike 3.0 Unported License许可使用。
数据集语言
日语(ja)
数据集规模
10,000 < n < 100,000
数据集任务类别
- 问答(question-answering)
- 摘要(summarization)
数据集许可证
Creative Commons Attribution-ShareAlike 3.0 Unported License
数据集字段说明
- index: 数据唯一标识符。
- bertscore: 包含recall、precision和f1 score,用于评估翻译质量。
- translator: 包含
en_ja和ja_en,分别表示英语到日语和日语到英语的翻译服务。
数据集贡献者
- 基于
kunishou/databricks-dolly-15k-ja数据集,由Sakusakumura开发。 - 原始数据集
databricks-dolly-15k由Databricks, Inc.开发。
搜集汇总
数据集介绍
构建方式
该数据集sakusakumura/databricks-dolly-15k-ja-scored是kunishou/databricks-dolly-15k-ja的衍生版本,后者源自Databricks发布的英文数据集databricks-dolly-15k,经过机器翻译得到日语版本。为了提升数据质量,构建者针对机器翻译中常见的缺陷——如输入输出完全一致、输出复制自指令、术语不一致及专有名词翻译失败等问题,采用逆向翻译策略,将日语数据回译至英语,并利用BERTScore评估回译结果与原始英文文本的语义相似度,从而为每条数据附加了精确的翻译质量评分。该评分包含精确率、召回率和F1分数三个维度,旨在量化数据的可靠性。
使用方法
数据集的使用方法灵活多样,用户可直接通过HuggingFace的datasets库加载,并根据BERTScore中的F1分数设定阈值,过滤掉低质量样本以优化训练效果。例如,针对翻译质量较差的数据(如F1分数低于0.6的样本),可将其排除以提高模型微调的稳定性。此外,用户还可利用提供的翻译服务字段追溯翻译来源,或结合原始英文数据集进行对比分析。数据集采用CC BY-SA 3.0许可,允许学术与商业用途,但需遵守相应署名和相同方式共享的条件。
背景与挑战
背景概述
在自然语言处理领域,高质量指令微调数据集对于提升大语言模型的性能至关重要,然而非英语语种(尤其是日语)的此类资源长期匮乏。为填补这一空白,研究者Sakusakumura于2023年创建了sakusakumura/databricks-dolly-15k-ja-scored数据集。该数据集基于kunishou/databricks-dolly-15k-ja(后者是Databricks公司发布的英文指令数据集databricks-dolly-15k的机器翻译版本),通过引入BERTScore评估机制,为每条样本附加了翻译质量评分。其核心研究问题在于:如何系统性地识别并量化机器翻译数据中的低质量样本,从而为日语指令微调提供更可靠的资源。这一工作不仅直接提升了dolly-15k日语版本的实用性,更为多语言数据集的质量控制树立了方法论典范,对推动日语大语言模型的发展具有显著影响力。
当前挑战
该数据集所应对的领域挑战在于:机器翻译生成的指令数据常包含多种质量缺陷,包括输入与输出完全重复、输出被错误复制为指令、因表记不统一导致语义不一致,以及专有名词翻译失败等,此类问题会严重污染微调数据,损害模型性能。在构建过程中,研究者面临的核心挑战是如何设计一种客观、可复现的评估框架来量化这些缺陷。为此,他们采用将日语数据反向翻译为英语,再通过BERTScore计算与原始英文文本的相似度,以F1分数作为质量指标。然而,该方法本身也面临挑战:评分结果高度依赖所选的英日翻译服务和BERT模型,即使质量合格的数据也可能因翻译偏差而获得低分,这要求使用者需根据具体应用场景谨慎设定过滤阈值,避免过度剔除有用样本。
常用场景
经典使用场景
sakusakumura/databricks-dolly-15k-ja-scored 作为日文指令微调与文本生成领域的标杆性数据集,其最经典的使用场景在于为大语言模型提供高质量的日文问答与摘要训练样本。该数据源自 Databricks 的英文 Dolly-15k,经由机器翻译并辅以 BERTScore 质量筛选,确保了日文指令数据的语义保真度。研究者常利用其丰富的分类、开放域问答与摘要任务,对模型进行监督微调,从而提升模型在日文语境下的指令遵循能力与生成流畅性。通过对低质量样本的剔除,该数据集为构建鲁棒的日文对话系统奠定了坚实的数据基础。
解决学术问题
在学术研究中,该数据集有效解决了机器翻译语料库普遍存在的噪声问题,即翻译不一致、内容重复及专有名词误译等对模型性能的负面影响。通过引入 BERTScore 作为翻译质量评估指标,研究者能够量化并过滤低效样本,从而提升微调数据的信度与效度。这一方法为跨语言指令数据集的质量控制提供了可复现的范式,推动了多语言 NLP 中数据清洗与评估标准的进步。其意义在于,不仅降低了低质量数据对模型泛化能力的干扰,还促进了日文自然语言理解与生成任务的学术探索。
实际应用
在实际应用层面,该数据集被广泛用于构建日文智能客服、知识问答系统及内容摘要工具。例如,企业可基于其高质量指令样本微调对话模型,以应对用户关于产品信息、操作指南等日文查询。媒体机构则利用摘要子集训练自动新闻概括系统,提升信息处理效率。此外,其开源许可特性使得小型开发团队也能低成本地定制日文 AI 助手,加速了语言技术在日本本土化场景中的落地,如医疗咨询、教育辅导等垂直领域。
数据集最近研究
最新研究方向
近年来,随着大语言模型在自然语言处理领域的广泛应用,高质量、多语言微调数据集的构建成为前沿研究焦点。sakusakumura/databricks-dolly-15k-ja-scored 数据集正是在这一背景下应运而生,它是对英文 Databricks-Dolly-15k 数据集进行日语机器翻译后,引入 BERTScore 评估机制以量化翻译质量的衍生资源。该研究直指机器翻译数据中普遍存在的语义失真、指令与输出雷同、专有名词误译等顽疾,通过逆向翻译与 F1 分数过滤,有效筛选出高保真度的训练样本。这一创新方法不仅提升了日语问答与摘要任务的微调效果,也为多语言 NLP 资源的质量控制提供了可复现的范式,对推动非英语社区的大模型落地具有里程碑式的意义。
以上内容由遇见数据集搜集并总结生成


