FIOVA
收藏arXiv2024-10-20 更新2024-10-23 收录
下载链接:
https://huuuuusy.github.io/fiova/
下载链接
链接失效反馈官方服务:
资源简介:
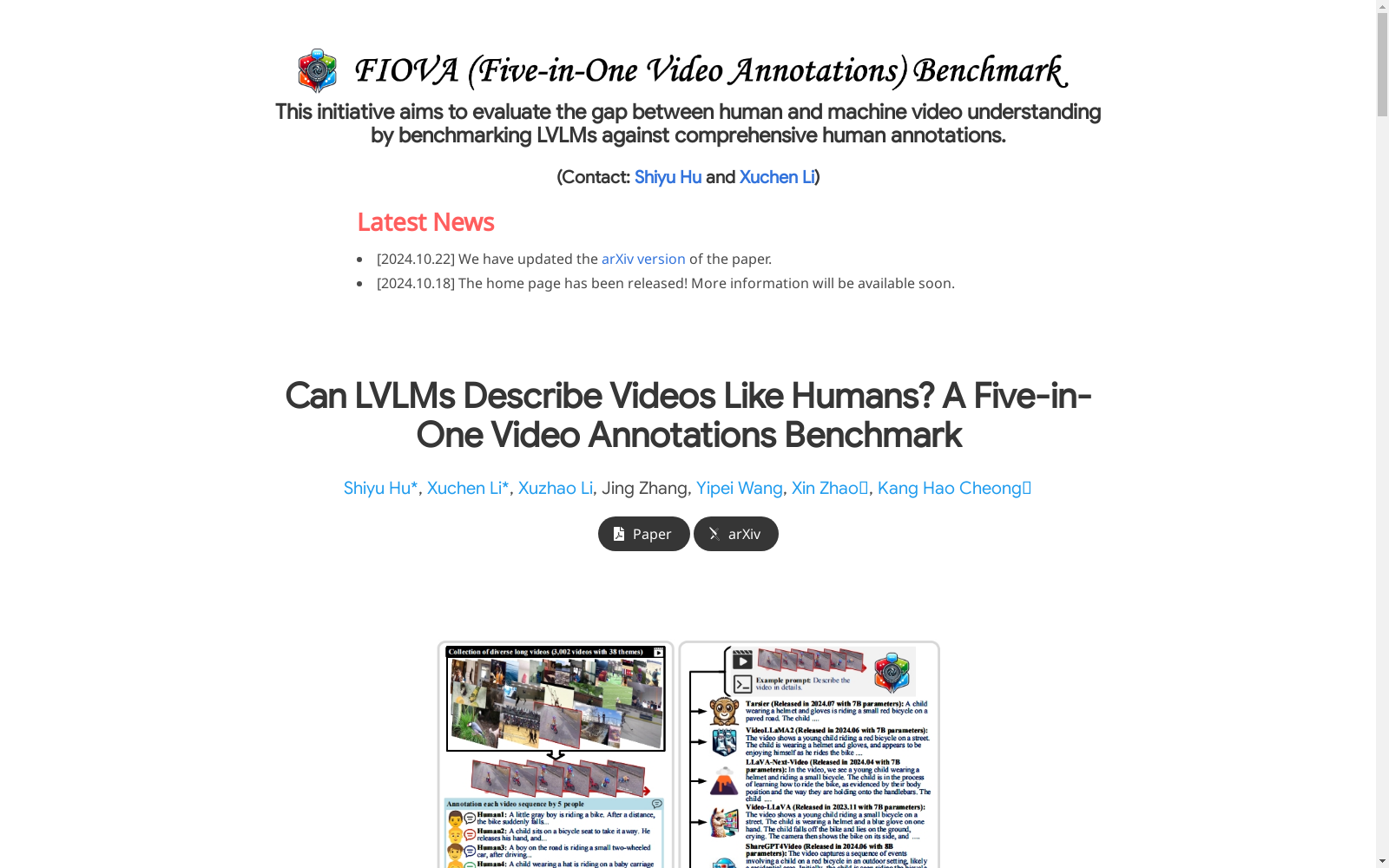
FIOVA数据集由南洋理工大学和中国科学院自动化研究所等机构共同创建,包含3002个长视频序列,平均时长为33.6秒,涵盖38个不同的主题。每个视频由五名不同的标注者进行详细标注,生成4到15倍于现有基准的描述长度,旨在建立一个全面的人类理解基线。数据集的创建过程严格遵循标准化指南,确保描述的准确性和一致性。FIOVA数据集主要用于评估和比较大型视觉语言模型与人类在视频理解任务中的表现,旨在解决视频描述任务中的复杂时空关系理解问题。
The FIOVA dataset was co-created by institutions including Nanyang Technological University and the Institute of Automation of the Chinese Academy of Sciences. It comprises 3002 long video sequences with an average duration of 33.6 seconds, covering 38 distinct topics. Each video was meticulously annotated by five separate annotators, generating descriptive content that is 4 to 15 times longer than that of existing benchmark datasets, with the goal of establishing a comprehensive human understanding baseline. The dataset's development process strictly follows standardized guidelines to ensure the accuracy and consistency of the annotations. The FIOVA dataset is primarily used to evaluate and compare the performance of large vision-language models and humans in video understanding tasks, aiming to address the challenge of understanding complex spatio-temporal relationships in video captioning tasks.
提供机构:
南洋理工大学、中国科学院自动化研究所、中国科学院大学、北京理工大学、东南大学、北京科技大学
创建时间:
2024-10-20
搜集汇总
数据集介绍
构建方式
FIOVA数据集的构建过程分为三个主要步骤。首先,收集了3,002个长视频序列,涵盖38种不同的主题,确保了数据集的多样性和复杂性。其次,每个视频由五名不同的标注者进行标注,以捕捉广泛的人类视角,并生成详细且多样化的描述。最后,通过GPT-3.5-turbo模型对这些标注进行评估和整合,生成每个视频的综合基准描述,从而形成一个全面的人类理解基准。
特点
FIOVA数据集的主要特点在于其广泛的主题覆盖和详细的标注。每个视频平均长度为33.6秒,且每个视频由五名标注者进行标注,生成的描述长度是现有基准的4到15倍。这种多标注者的方式不仅提高了数据集的可靠性,还为评估模型提供了更丰富的参考。此外,数据集中的视频包含了复杂的时空关系,挑战了模型在处理复杂视频内容时的能力。
使用方法
FIOVA数据集主要用于评估大型视觉语言模型(LVLMs)在视频描述任务中的表现。研究者可以通过对比LVLMs生成的描述与人类标注的基准描述,来分析模型在理解复杂视频内容方面的能力。此外,数据集的多维度评估方法,包括传统的BLEU、METEOR、GLEU指标以及新的AutoCQ方法,为模型的全面评估提供了工具。通过这些评估,研究者可以识别模型的优势和不足,从而指导未来模型的改进方向。
背景与挑战
背景概述
FIOVA数据集由南洋理工大学、中国科学院自动化研究所等多个机构的研究人员共同创建,旨在评估大型视觉语言模型(LVLMs)在视频描述任务中的表现。该数据集于2024年7月发布,包含了3,002个长视频序列,平均时长为33.6秒,涵盖了38个多样化的主题。每个视频由五名不同的标注者进行标注,生成的描述长度是现有基准的4到15倍,从而为视频描述任务提供了更全面的基准。FIOVA数据集的核心研究问题是评估LVLMs是否能够像人类一样全面地描述视频,并通过合理的人机比较来增强对这些模型的理解和应用。
当前挑战
FIOVA数据集在构建过程中面临的主要挑战包括:1) 需要处理复杂的长视频序列,这些视频包含复杂的时空关系,对模型的理解和描述能力提出了高要求;2) 每个视频需要由五名标注者进行标注,确保标注的一致性和多样性,这增加了数据集构建的复杂性和成本;3) 现有的视频理解基准存在局限性,如视频时长短、标注简短、依赖单一标注者的视角等,这些因素限制了对LVLMs理解复杂长视频能力的全面评估。FIOVA数据集通过提供多重标注和更长的描述,旨在解决这些挑战,建立一个更健壮的人类基准,以准确反映人类对视频理解的能力。
常用场景
经典使用场景
FIOVA数据集的经典使用场景在于评估大型视觉语言模型(LVLMs)在视频描述任务中的表现,通过与人类注释进行对比,揭示模型在理解复杂视频内容方面的能力。该数据集包含3,002个长视频序列,每个视频由五名不同的注释者进行描述,生成4至15倍于现有基准的详细描述,从而建立了一个全面的基准,用于评估LVLMs在视频理解任务中的表现。
衍生相关工作
FIOVA数据集的提出催生了多项相关研究工作,包括对现有LVLMs在视频描述任务中的深入评估,以及开发新的评估方法和模型架构以提高视频理解能力。此外,FIOVA数据集还促进了跨学科研究,如心理学和计算机科学的结合,以更好地理解人类和机器在视频理解中的差异和相似性。
数据集最近研究
最新研究方向
在视频理解领域,FIOVA数据集的最新研究方向聚焦于评估大型视觉语言模型(LVLMs)在视频描述任务中的表现,特别是与人类描述的对比。研究通过构建包含3,002个长视频序列的FIOVA数据集,每个视频由五名不同的标注者进行标注,生成详细且多样化的描述,从而建立一个全面的基准。该研究不仅评估了六种最先进的LVLMs(如VideoLLaMA2、LLaVA-NEXT-Video等)在视频描述任务中的表现,还通过细粒度的分析揭示了这些模型在复杂视频理解中的局限性。研究发现,尽管LVLMs在某些方面表现出与人类相似的感知和推理能力,但在信息遗漏和描述深度方面仍存在显著不足。此外,研究强调了传统评估指标在复杂视频描述任务中的局限性,并提出了新的评估方法,如AutoCQ,以更全面地评估模型的性能。
相关研究论文
- 1Can LVLMs Describe Videos like Humans? A Five-in-One Video Annotations Benchmark for Better Human-Machine Comparison南洋理工大学、中国科学院自动化研究所、中国科学院大学、北京理工大学、东南大学、北京科技大学 · 2024年
以上内容由遇见数据集搜集并总结生成


