Online-Retail-Cleaned
收藏Hugging Face2025-04-06 更新2025-04-07 收录
下载链接:
https://huggingface.co/datasets/pavan-naik/Online-Retail-Cleaned
下载链接
链接失效反馈官方服务:
资源简介:
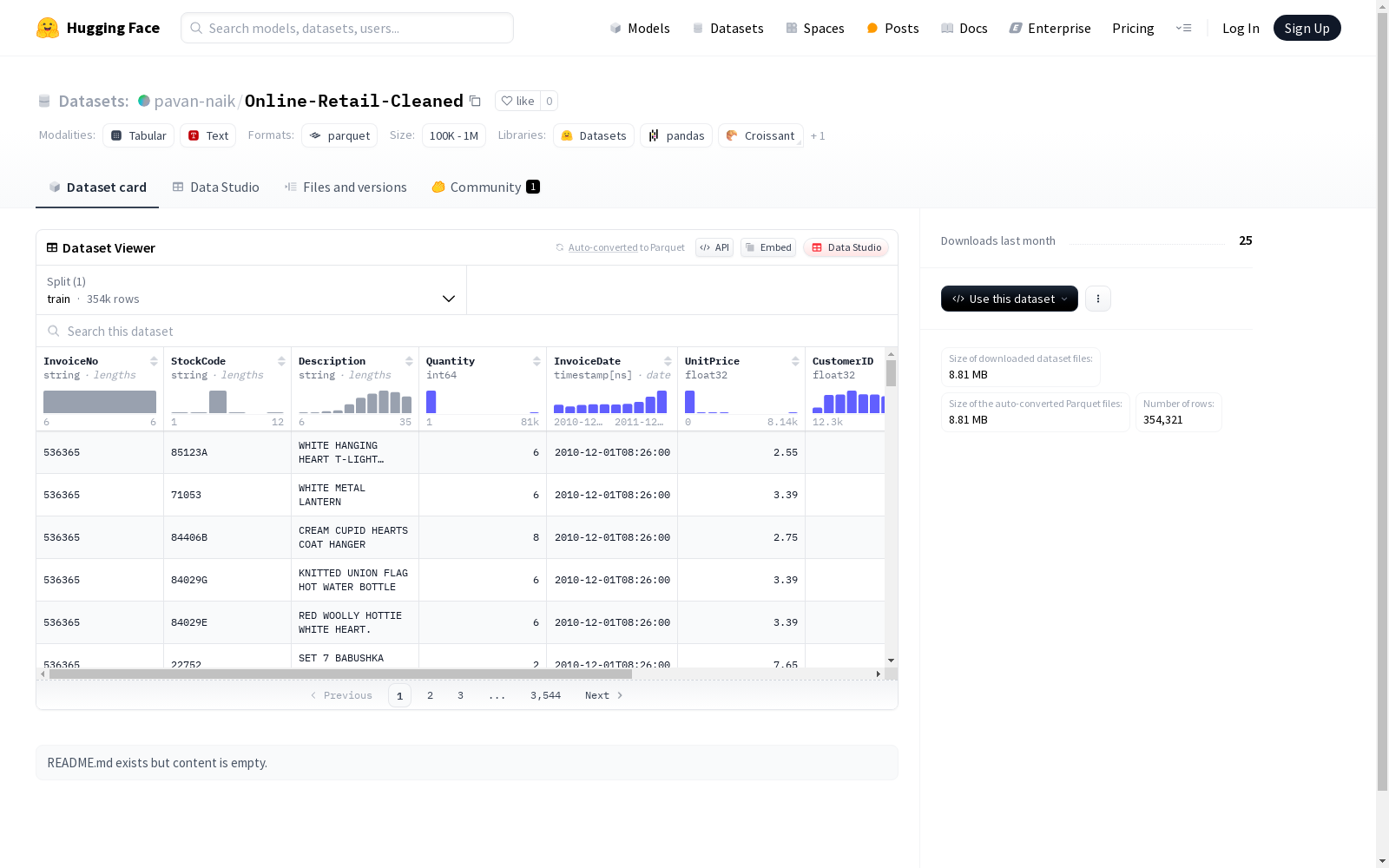
该数据集是一份包含发票详细信息的数据库,具体字段包括发票号码、股票代码、商品描述、数量、开票日期、单价、客户ID和国家信息。此外,还有一个标准化的商品描述字段。数据集分为训练集,共有354,321条示例,数据大小为37,776,996字节。
创建时间:
2025-04-02
原始信息汇总
数据集概述
基本信息
- 数据集名称: Online-Retail-Cleaned
- 下载大小: 8,814,854 bytes
- 数据集大小: 37,776,996 bytes
- 训练集样本数: 354,321
数据特征
- InvoiceNo: 字符串类型,发票编号
- StockCode: 字符串类型,库存代码
- Description: 字符串类型,商品描述
- Quantity: 整型,商品数量
- InvoiceDate: 时间戳类型,发票日期
- UnitPrice: 浮点型,商品单价
- CustomerID: 浮点型,客户ID
- Country: 字符串类型,国家
- Description_Standardized: 字符串类型,标准化后的商品描述
数据分割
- 训练集: 包含354,321个样本,占用37,776,996 bytes
搜集汇总
数据集介绍
构建方式
在电子商务分析领域,Online-Retail-Cleaned数据集源自英国某在线零售商的真实交易记录,经过系统的数据清洗和标准化处理。原始数据通过提取2010至2011年间的交易流水构建,涵盖发票编号、商品代码等关键字段,特别对商品描述进行了文本标准化处理,确保数据质量满足分析需求。时间戳字段精确到纳秒级,为时序分析提供了高精度基础。
特点
该数据集包含354,321条跨国交易记录,具有典型的零售业数据特征。商品数量字段呈现整数分布,单价采用浮点型存储,客户ID和国别信息完整保留。经过标准化的商品描述字段显著提升了文本分析效率,时间戳信息支持细粒度的购买行为模式挖掘。多维度特征组合使其成为客户分群、商品关联规则挖掘的理想实验数据。
使用方法
研究人员可通过HuggingFace平台直接加载数据集,默认配置包含完整的训练集分割。建议使用时重点关注时序特征与商品属性的交叉分析,利用标准化描述字段构建文本特征。数据规模约37.7MB,适合在常规计算环境中进行客户购买预测、购物篮分析等机器学习任务,注意处理CustomerID中的浮点型缺失值。
背景与挑战
背景概述
Online-Retail-Cleaned数据集源于电子商务领域的交易数据分析需求,由匿名研究机构于近年整理发布。该数据集收录了跨国零售商的在线交易记录,涵盖发票编号、商品描述、数量、单价等关键字段,旨在为消费者行为分析、销售预测及库存优化提供数据支持。其标准化商品描述字段的引入,显著提升了数据质量,使之成为零售分析领域的重要基准数据集。
当前挑战
该数据集面临的领域挑战在于如何从高维度交易数据中提取有效的消费者购买模式,尤其在处理稀疏性数据和长尾商品分布时存在显著困难。构建过程中的技术挑战包括原始数据的多源异构性处理,如发票日期格式的全球标准化问题,以及缺失客户ID字段的插补难题。商品描述文本的语义归一化过程亦需克服多语言混杂和拼写变异等自然语言处理瓶颈。
常用场景
经典使用场景
Online-Retail-Cleaned数据集作为零售行业交易记录的标准化集合,其经典使用场景聚焦于消费者行为分析与销售预测领域。该数据集通过记录完整的交易时间序列、商品明细及客户信息,为研究者提供了构建客户购买路径模型的理想素材。在机器学习应用中,常被用于训练时序预测模型以判断商品需求波动,或构建推荐系统算法来优化商品展示策略。
实际应用
在实际商业环境中,该数据集支撑着智能库存管理系统的开发,通过分析历史购买记录预测区域性缺货风险。零售企业依据其构建的客户分群模型,可实施精准营销活动。数据中的跨国交易特征尤为珍贵,为跨境电商平台优化物流仓储布局提供了决策依据。
衍生相关工作
基于该数据集衍生的经典研究包括《基于LSTM的零售需求预测模型》,其创新性地将时序神经网络应用于该数据集。另有学者发表《跨国零售中的消费者画像构建》,利用标准化商品描述开发了新型特征工程方法。这些工作显著推动了零售分析领域从传统统计方法向机器学习范式的转型。
以上内容由遇见数据集搜集并总结生成


