KITTI-360
收藏arXiv2025-09-30 收录
下载链接:
http://www.cvlibs.net/datasets/kitti-360/
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一份全面的集合,包含了在不同环境下收集的激光雷达扫描数据。它被用于测试模型在各种环境中的泛化能力。此外,该数据集还可用于执行闭环检测和重定位任务。
This dataset is a comprehensive collection of LiDAR scanning data gathered in diverse environments. It is employed to test the generalization capability of models across various scenarios. Additionally, this dataset can also be utilized to conduct loop closure detection and relocalization tasks.
提供机构:
KITTI
搜集汇总
数据集介绍
构建方式
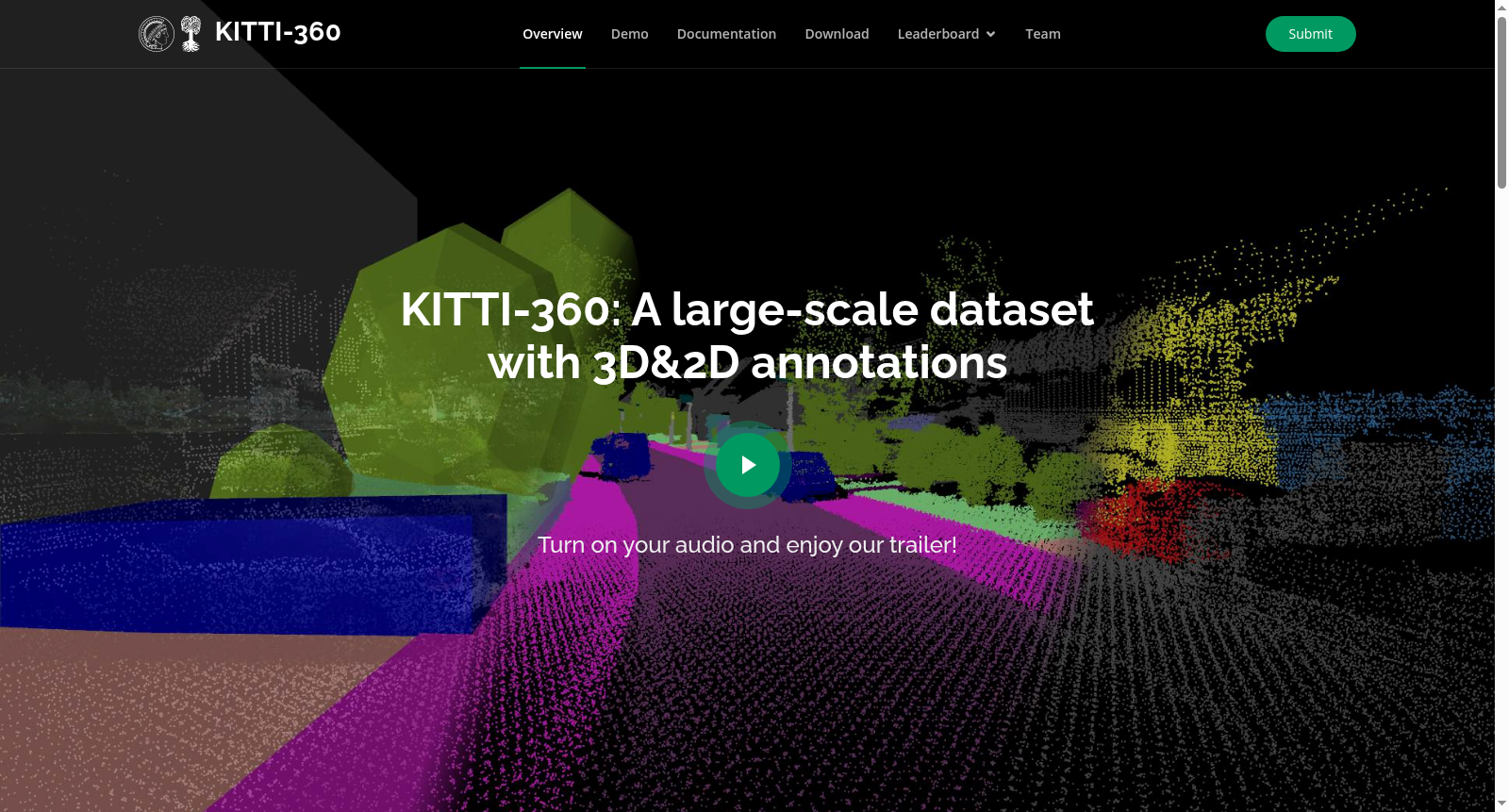
KITTI-360 数据集构建于一个装备了多模态传感器的移动平台之上,包括前向立体相机、侧向鱼眼相机、Velodyne 激光扫描仪以及推扫式激光扫描仪,实现了360度的环境感知。为了获取密集且连贯的语义与实例标注,研究团队开发了一款基于WebGL的三维标注工具,允许标注人员直接在三维空间中利用包围基元(如立方体、椭球体)对静态与动态场景元素进行标注。随后,通过一种非局部多场条件随机场模型,将稀疏的三维标注信息精确地传递至二维图像域,从而生成了超过15万张图像与10亿个三维点的语义实例标签,确保了跨模态与跨时间的一致性。
特点
该数据集的核心特点在于其丰富的感知模态与高度一致的跨模态标注。与仅提供前向视角或稀疏三维标注的数据集不同,KITTI-360 提供了包含鱼眼图像与推扫式激光扫描在内的全景感知数据,并实现了二维像素与三维点云之间语义与实例标签的严格对齐。此外,其标注具备时间连贯性,每个物理对象在视频序列中拥有唯一实例标识,这为动态场景理解、新颖视角合成以及语义即时定位与地图构建等交叉领域的研究提供了前所未有的数据支持。
使用方法
数据集的使用方法灵活多样,支持多种计算机视觉、图形学与机器人学任务的基准测试。用户可依据具体任务需求,利用其提供的精确位姿信息与多模态原始数据(图像、激光点云)进行模型训练。数据集官方提供了在线评估服务器,针对语义场景理解(如二维/三维分割、三维目标检测)、新颖视角合成(包括外观与语义联合合成)以及语义SLAM等挑战性任务,设立了独立的测试集与评估协议。用户需遵循数据集定义的标准标签体系,并利用配套的脚本工具进行数据加载与预处理,以参与基准测试或开展自主研究。
背景与挑战
背景概述
在自动驾驶与机器人感知领域,2D视觉、3D几何与图形学长期独立发展,直至近年学界才意识到融合多模态信息是实现鲁棒智能系统的关键。为填补这一交叉研究空白,德国蒂宾根大学与马克斯·普朗克智能系统研究所的Yiyi Liao、Jun Xie及Andreas Geiger等于2022年发布了KITTI-360数据集。作为经典KITTI数据集的继承者,该数据集聚焦于城郊驾驶场景,提供了超过30万张图像与80万次激光扫描,涵盖360°环视鱼眼图像、推扫式激光雷达及高精度位姿信息。其核心创新在于通过WebGL工具在3D空间直接标注静态与动态物体,再借助非局部多场条件随机场模型将稀疏3D标注传播至2D图像,最终生成超过15万张像素级语义实例标签与10亿个3D语义点。该数据集定义了37类语义标签,与Cityscapes兼容,并设立了语义场景理解、新视角合成及语义SLAM三大基准任务,为跨学科研究提供了统一评测平台,对推动全自动驾驶系统的终极目标具有里程碑意义。
当前挑战
KITTI-360的构建与使用面临多重挑战。首先,在领域问题层面,该数据集旨在解决城市环境理解中2D与3D语义一致性的根本难题——传统方法多在2D或3D域独立标注,导致跨域标签冲突且标注效率低下。其次,构建过程中存在三大技术挑战:一是动态物体的精确标注,由于其在3D重建中轨迹分散、感知困难,需开发半自动方案,假设物体尺寸恒定且轨迹平滑,通过关键帧插值与样条拟合自动生成时变3D包围盒;二是从稀疏、嘈杂的3D点云与粗粒度3D基元生成密集、准确的2D像素级标签,为此设计了非局部多场CRF模型,联合推理3D点与2D像素的语义实例分布,并利用学习网络提供先验;三是确保标注质量,需对379个批次(每批约200米行驶距离)进行严格质检,通过多次试标注训练评估标注员,并设立交叉校验机制,平均每批3小时的3D标注时间显著优于传统2D逐帧标注(每帧需60分钟),但动态物体因点云累积误差与形变仍易产生对齐偏差,导致边界区域置信度下降。
常用场景
经典使用场景
KITTI-360作为KITTI数据集的进阶版本,专为城市场景理解中的跨学科研究而设计。其经典使用场景涵盖自动驾驶领域中的多模态感知任务,包括利用立体相机、鱼眼相机和激光雷达的360度全方位数据,进行2D图像与3D点云的联合语义与实例分割。研究者常借助该数据集的高精度位姿与稠密标注,开展从视觉到机器人学的跨领域研究,例如在复杂的郊区驾驶环境中验证语义场景理解算法的鲁棒性。
衍生相关工作
KITTI-360的发布催生了一系列经典衍生工作。在方法层面,其提出的3D到2D的标签迁移框架启发了后续研究,如利用条件随机场融合多模态信息进行高效标注。在任务层面,基于该数据集的语义场景补全和语义SLAM基准,推动了如PointGroup等3D实例分割方法的发展,以及NeRF系列在新视图合成中的突破。这些工作共同促进了视觉、图形学与机器人学交叉领域的技术融合与创新。
数据集最近研究
最新研究方向
在自动驾驶与城市场景理解的交叉领域,KITTI-360数据集的最新研究聚焦于多模态融合与联合推理,推动视觉、图形学与机器人学的协同发展。该数据集通过提供360°感知数据、精确的语义实例标注及高精度定位信息,支撑了语义场景理解、新视角合成与语义SLAM等前沿任务。其创新的3D标注工具与标签迁移方法,显著降低了人工成本并提升了标注一致性,为构建全自主驾驶系统提供了关键基础。当前研究热点包括利用神经辐射场进行真实感新视角渲染、基于点云的语义补全,以及结合几何与语义的同步定位与建图,这些工作正逐步弥合虚拟仿真与现实场景之间的鸿沟。
相关研究论文
- 1KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D · 2022年
以上内容由遇见数据集搜集并总结生成


