有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
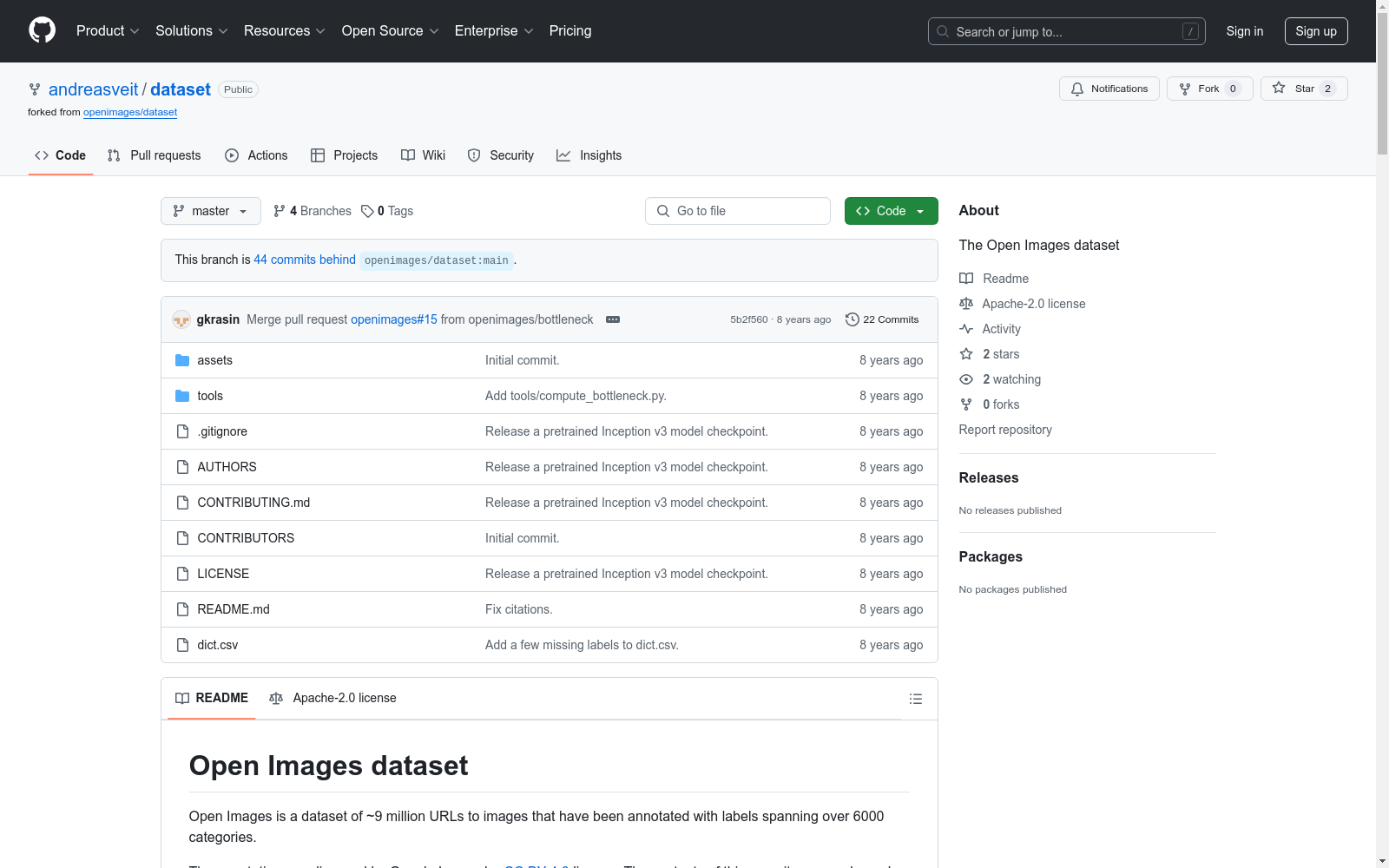
名称: Open Images dataset
规模: 约900万张图片
类别: 超过6000个类别
许可:
数据组织:
标签:
注释:
数据文件:
数据下载:
数据质量:
模型训练:
引用信息:
APA-style citation: "Krasin I., Duerig T., Alldrin N., Veit A., Abu-El-Haija S., Belongie S., Cai D., Feng Z., Ferrari V., Gomes V., Gupta A., Narayanan D., Sun C., Chechik G, Murphy K. OpenImages: A public dataset for large-scale multi-label and multi-class image classification, 2016. Available from https://github.com/openimages".
BibTeX:
@article{openimages, title={OpenImages: A public dataset for large-scale multi-label and multi-class image classification.}, author={Krasin, Ivan and Duerig, Tom and Alldrin, Neil and Veit, Andreas and Abu-El-Haija, Sami and Belongie, Serge and Cai, David and Feng, Zheyun and Ferrari, Vittorio and Gomes, Victor and Gupta, Abhinav, and Narayanan, Dhyanesh and Sun, Chen and Chechik, Gal and Murphy, Kevin}, journal={Dataset available from https://github.com/openimages}, year={2016} }
学生课堂行为数据集 (SCB-dataset3)
学生课堂行为数据集(SCB-dataset3)由成都东软学院创建,包含5686张图像和45578个标签,重点关注六种行为:举手、阅读、写作、使用手机、低头和趴桌。数据集覆盖从幼儿园到大学的不同场景,通过YOLOv5、YOLOv7和YOLOv8算法评估,平均精度达到80.3%。该数据集旨在为学生行为检测研究提供坚实基础,解决教育领域中学生行为数据集的缺乏问题。
arXiv 收录
PQAref
PQAref数据集是一个用于生物医学领域参考问答任务的数据集,旨在微调大型语言模型。该数据集包含三个部分:指令(问题)、摘要(从PubMed检索的相关摘要,包含PubMed ID、摘要标题和内容)和答案(预期答案,包含PubMed ID形式的参考)。数据集通过半自动方式创建,利用了PubMedQA数据集中的问题。
huggingface 收录
Figshare
Figshare是一个在线数据共享平台,允许研究人员上传和共享各种类型的研究成果,包括数据集、论文、图像、视频等。它旨在促进科学研究的开放性和可重复性。
figshare.com 收录
中国食物成分数据库
食物成分数据比较准确而详细地描述农作物、水产类、畜禽肉类等人类赖以生存的基本食物的品质和营养成分含量。它是一个重要的我国公共卫生数据和营养信息资源,是提供人类基本需求和基本社会保障的先决条件;也是一个国家制定相关法规标准、实施有关营养政策、开展食品贸易和进行营养健康教育的基础,兼具学术、经济、社会等多种价值。 本数据集收录了基于2002年食物成分表的1506条食物的31项营养成分(含胆固醇)数据,657条食物的18种氨基酸数据、441条食物的32种脂肪酸数据、130条食物的碘数据、114条食物的大豆异黄酮数据。
国家人口健康科学数据中心 收录
LIDC-IDRI
LIDC-IDRI 数据集包含来自四位经验丰富的胸部放射科医师的病变注释。 LIDC-IDRI 包含来自 1010 名肺部患者的 1018 份低剂量肺部 CT。
OpenDataLab 收录