cxr_mm2
收藏Hugging Face2024-12-16 更新2024-12-17 收录
下载链接:
https://huggingface.co/datasets/Amarsaish/cxr_mm2
下载链接
链接失效反馈官方服务:
资源简介:
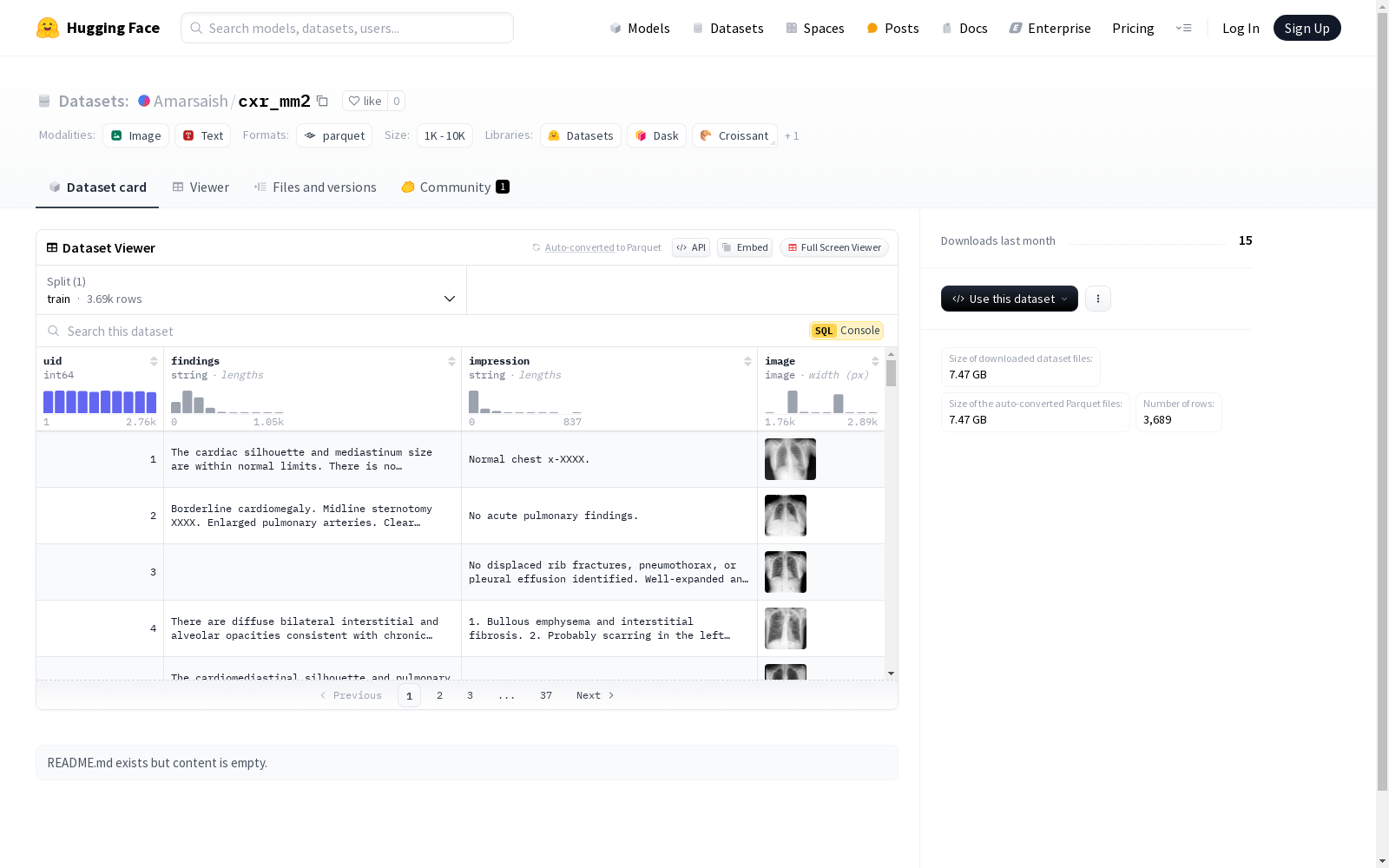
该数据集包含四个特征:用户ID(uid)、发现(findings)、印象(impression)和图像(image)。数据集被分割为训练集,包含3689个样本,数据集的总下载大小为7474283004字节,数据集的总大小为7525851499.271字节。
创建时间:
2024-12-16
原始信息汇总
数据集概述
数据集信息
- 特征(features):
- uid: 数据类型为
int64 - findings: 数据类型为
string - impression: 数据类型为
string - image: 数据类型为
image
- uid: 数据类型为
数据集划分
- train:
- 样本数量: 3689
- 数据大小: 7525851499.271 字节
数据集大小
- 下载大小: 7474283004 字节
- 数据集大小: 7525851499.271 字节
配置
- config_name: default
- data_files:
- split: train
- path: data/train-*
搜集汇总
数据集介绍
构建方式
cxr_mm2数据集的构建基于医学影像与文本描述的结合,旨在为胸部X光片提供详细的诊断信息。数据集包含了3689个训练样本,每个样本由唯一的标识符(uid)、影像发现(findings)、影像印象(impression)以及对应的X光图像(image)组成。通过这种方式,数据集不仅提供了视觉信息,还通过文本描述增强了诊断的准确性和全面性。
特点
cxr_mm2数据集的显著特点在于其多模态数据的融合,即图像与文本的结合。这种设计使得数据集在医学影像分析领域具有独特的优势,能够支持多种机器学习任务,如图像分类、文本生成和多模态学习。此外,数据集的规模适中,适合用于训练和验证模型,同时其结构化的数据格式也便于数据处理和模型开发。
使用方法
使用cxr_mm2数据集时,研究者可以利用其提供的图像和文本数据进行多种任务的训练和评估。例如,可以构建基于图像的分类模型来识别不同的医学影像特征,或者开发多模态模型来结合图像和文本信息进行更复杂的诊断任务。数据集的结构化格式使得数据加载和预处理变得简单,研究者可以直接使用或根据需要进行数据增强和特征提取。
背景与挑战
背景概述
cxr_mm2数据集是由某研究机构或团队在近期创建的,专注于胸部X光图像的多模态分析。该数据集的核心研究问题涉及如何通过结合图像与文本信息,提升医学影像的诊断准确性。主要研究人员或机构通过整合大量的胸部X光图像及其对应的临床发现和印象描述,旨在为医学影像分析领域提供一个全面且高质量的数据资源。这一数据集的推出,不仅为多模态学习提供了新的研究方向,也为医学影像的自动化诊断技术的发展奠定了坚实的基础。
当前挑战
cxr_mm2数据集在构建过程中面临了多重挑战。首先,如何确保图像与文本数据的高质量匹配是一个关键问题,因为错误的匹配可能导致模型训练的偏差。其次,医学影像数据的隐私和安全问题也是一大挑战,尤其是在处理敏感的病人信息时,必须严格遵守相关法律法规。此外,多模态数据的整合与处理技术要求较高,如何在图像和文本之间建立有效的关联模型,以提升诊断的准确性,是该数据集面临的主要技术难题。
常用场景
经典使用场景
cxr_mm2数据集在医学影像分析领域中,主要用于胸部X光片的自动诊断与分析。通过结合图像数据与文本描述,该数据集支持多模态学习,使得模型能够在图像特征与临床文本信息之间建立关联,从而提升诊断的准确性与鲁棒性。
实际应用
在实际应用中,cxr_mm2数据集可用于开发和验证胸部X光片的自动诊断系统,这些系统能够辅助放射科医生进行快速、准确的诊断,特别是在资源有限的地区,能够显著提升医疗服务的效率与质量。
衍生相关工作
基于cxr_mm2数据集,研究者们开发了多种多模态学习模型,如结合卷积神经网络(CNN)与自然语言处理(NLP)的混合模型,这些模型在医学影像分析竞赛中取得了优异成绩,并推动了多模态学习在医学领域的广泛应用。
以上内容由遇见数据集搜集并总结生成


