PhilipMay/stsb_multi_mt
收藏Hugging Face2024-05-14 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/PhilipMay/stsb_multi_mt
下载链接
链接失效反馈资源简介:
STSb Multi MT数据集是一个多语言的语义文本相似度(STS)基准数据集,包含了德语、英语、西班牙语、法语、意大利语、荷兰语、波兰语、葡萄牙语、俄语和中文的翻译版本。该数据集的主要用途是用于训练句子嵌入模型,如T-Systems-onsite/cross-en-de-roberta-sentence-transformer。数据集的结构包括句子对和它们的相似度评分,评分范围从0到5。数据集支持的任务包括文本分类和语义相似度评分。数据集的创建过程涉及众包和机器翻译,源数据来自STSbenchmark数据集。
提供机构:
PhilipMay
原始信息汇总
数据集概述
名称: STSb Multi MT
语言: 德语 (de), 英语 (en), 西班牙语 (es), 法语 (fr), 意大利语 (it), 荷兰语 (nl), 波兰语 (pl), 葡萄牙语 (pt), 俄语 (ru), 中文 (zh)
许可证: 其他
多语言性: 多语言
大小: 10K<n<100K
源数据集: 扩展自其他-sts-b
任务类别: 文本分类
任务ID: 文本评分, 语义相似性评分
标签: sentence-transformers
数据集大小和下载大小:
- 德语: 数据集大小 1307859 字节, 下载大小 823156 字节
- 英语: 数据集大小 1106317 字节, 下载大小 720594 字节
- 西班牙语: 数据集大小 1326943 字节, 下载大小 803220 字节
- 法语: 数据集大小 1364700 字节, 下载大小 828209 字节
- 意大利语: 数据集大小 1306293 字节, 下载大小 813106 字节
- 荷兰语: 数据集大小 1251434 字节, 下载大小 786341 字节
- 波兰语: 数据集大小 1241433 字节, 下载大小 832282 字节
- 葡萄牙语: 数据集大小 1284054 字节, 下载大小 799737 字节
- 俄语: 数据集大小 2077925 字节, 下载大小 1088400 字节
- 中文: 数据集大小 1045055 字节, 下载大小 715580 字节
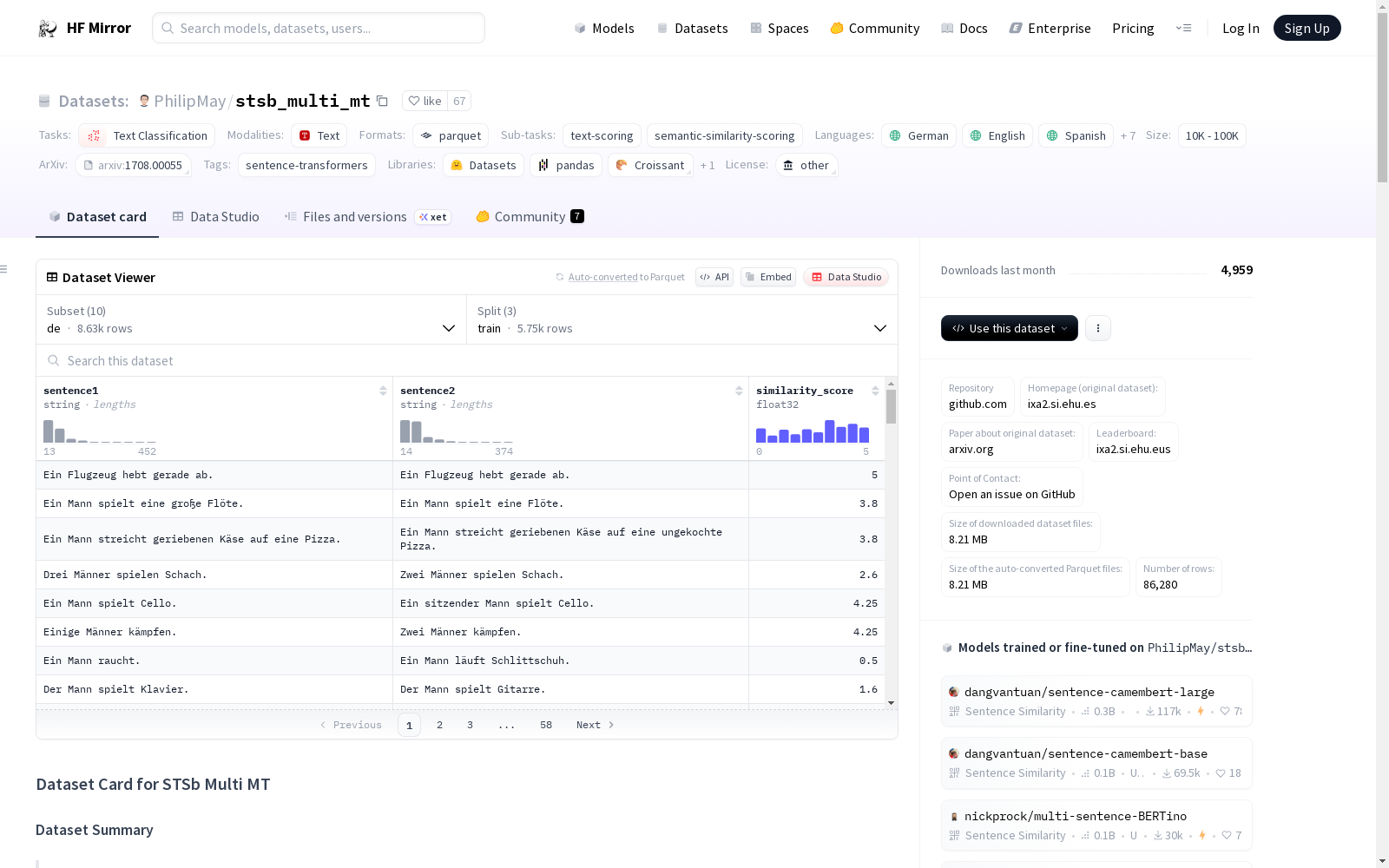
数据集结构:
- 特征:
sentence1: 字符串sentence2: 字符串similarity_score: 浮点数 (32位)
- 数据分割:
- 训练集: 5749 样本
- 验证集: 1500 样本
- 测试集: 1379 样本
数据集创建:
- 语言创建者: 众包, 发现, 机器生成
- 注释创建者: 众包
搜集汇总
数据集介绍
构建方式
构建该数据集的方法是通过对原始英语STSbenchmark数据集进行多语言翻译。首先,从SemEval在2012年至2017年间组织的STS任务中选取了一组英语数据集。这些数据集涵盖了来自图像标题、新闻标题和用户论坛的文本。然后,使用deepl.com进行多语言翻译,将原始英语数据集翻译成德语、西班牙语、法语、意大利语、荷兰语、波兰语、葡萄牙语、俄语和中文。翻译后的数据集包含了成对的句子及其相似度评分。
特点
该数据集的特点是其多语言性和多样性。它包含了多种语言的翻译数据,使得模型可以在跨语言语义相似度评估任务上进行训练和评估。数据集中的句子对覆盖了从完全等价到完全不相似的各种相似度,这为模型提供了广泛的训练和评估场景。此外,数据集的规模适中,包括训练、验证和测试三个数据集,方便研究者进行实验。
使用方法
使用该数据集的方法是通过加载特定语言的训练、验证或测试数据集。例如,使用Python的datasets库可以加载德语验证数据集,代码如下:
python
from datasets import load_dataset
dataset = load_dataset("stsb_multi_mt", name="de", split="dev")
同样,也可以加载英语训练数据集,代码如下:
python
from datasets import load_dataset
dataset = load_dataset("stsb_multi_mt", name="en", split="train")
加载后的数据集是一个包含句子对和相似度评分的字典,可以用于训练和评估语义相似度评估模型。
背景与挑战
背景概述
在自然语言处理领域,语义相似度评估是一项关键任务,它对于各种应用,如问答系统、信息检索和机器翻译等,都至关重要。为了促进这一领域的研究,Philip May 创建了 STSb Multi MT 数据集,该数据集是对 STSbenchmark 数据集的多语言扩展,涵盖了德语、英语、西班牙语、法语、意大利语、荷兰语、波兰语、葡萄牙语、俄语和中文等十种语言。该数据集收集了来自图像标题、新闻标题和用户论坛的文本,旨在帮助研究人员训练和评估句子嵌入模型,如 T-Systems-onsite/cross-en-de-roberta-sentence-transformer。STSb Multi MT 数据集自创建以来,已成为多语言语义相似度评估的重要资源,推动了该领域的发展。
当前挑战
尽管 STSb Multi MT 数据集在多语言语义相似度评估方面取得了显著进展,但它也面临一些挑战。首先,数据集的构建依赖于自动翻译,这可能引入翻译误差,从而影响评估的准确性。其次,数据集的规模相对较小,这可能限制了模型在更广泛场景下的泛化能力。此外,由于数据集的多语言特性,不同语言的语义相似度评估可能存在文化差异和语言特性差异,这需要研究人员在处理数据时予以考虑。为了解决这些挑战,未来的研究可能需要探索更精确的翻译技术,扩大数据集规模,并深入分析不同语言间的语义相似度评估差异。
常用场景
经典使用场景
在自然语言处理领域,语义相似度评分是一个基础且关键的任务。STSb Multi MT数据集提供了一个多语言的语义相似度评分基准,包括德语、英语、西班牙语、法语、意大利语、荷兰语、波兰语、葡萄牙语、俄语和中文。该数据集由两个句子及其相似度评分组成,相似度评分的范围从0到5,其中5表示两个句子完全等价。这种结构使得数据集适用于训练和评估句子嵌入模型,如T-Systems-onsite/cross-en-de-roberta-sentence-transformer,这些模型可以学习句子之间的语义关系。
实际应用
在实用场景中,STSb Multi MT数据集可以应用于机器翻译、文本摘要、问答系统等自然语言处理任务。例如,在机器翻译中,该数据集可以帮助模型学习不同语言之间的语义相似性,从而提高翻译的准确性和流畅性。此外,该数据集还可以用于评估文本摘要和问答系统的性能,帮助开发者改进这些系统的语义理解能力。
衍生相关工作
基于STSb Multi MT数据集,研究者们进行了许多相关的工作。例如,一些研究者使用该数据集来训练和评估跨语言句子嵌入模型,这些模型可以在不同语言之间进行语义相似度评分。此外,一些研究者还使用该数据集来研究多语言环境下语义理解的问题,从而推动多语言自然语言处理技术的发展。
以上内容由遇见数据集搜集并总结生成


