SpeechRole-Data
收藏arXiv2025-08-04 更新2025-08-07 收录
下载链接:
https://github.com/yuhui1038/SpeechRole
下载链接
链接失效反馈官方服务:
资源简介:
SpeechRole-Data是一个大规模、高质量的数据集,包含了98种不同的角色和超过11.2万个基于语音的单轮和多轮对话。每个角色都具有独特的音调和韵律特征,从而能够实现更复杂的语音角色扮演。数据集的构建过程包括角色选择、对话生成和音频处理等步骤,旨在为语音驱动多模态角色扮演研究提供坚实的基础。
SpeechRole-Data is a large-scale, high-quality dataset that covers 98 distinct roles and over 112,000 speech-based single-turn and multi-turn dialogues. Each role has unique tonal and prosodic characteristics, enabling more sophisticated speech-driven role-play. The construction of this dataset includes procedures such as role selection, dialogue generation and audio processing, aiming to provide a solid foundation for research on speech-driven multimodal role-play.
提供机构:
复旦大学, 抖音公司, IEIT系统有限公司
创建时间:
2025-08-04
搜集汇总
数据集介绍
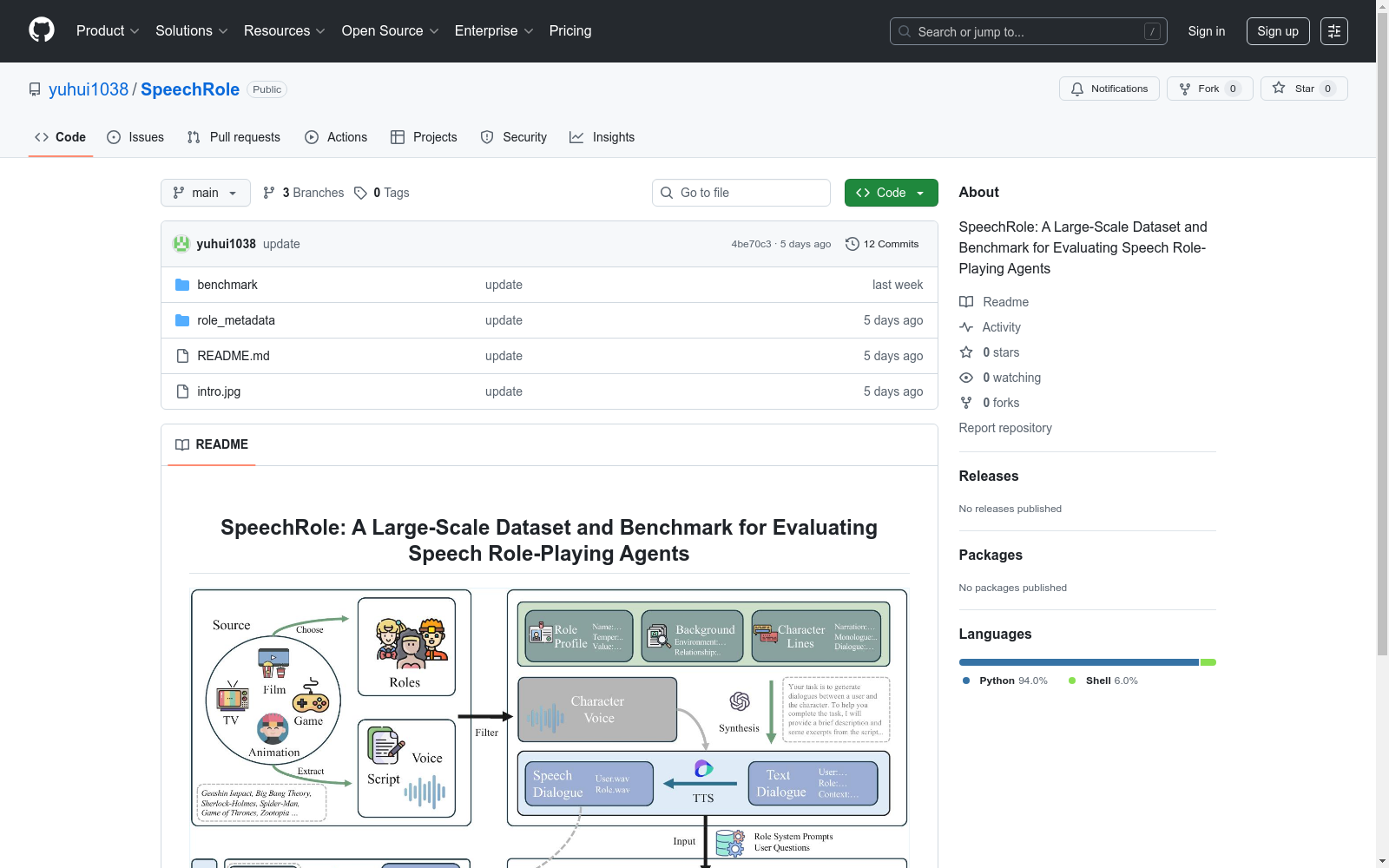
构建方式
SpeechRole-Data数据集的构建采用了多阶段流程,涵盖角色选择、文本对话生成和语音处理三个核心环节。研究团队从ChatHaruhi和RoleLLM等来源精选98个具有鲜明声学特征的角色,通过GPT-4.1模型生成11.2万条单轮及多轮对话文本,并采用语义相似度计算和去重技术确保数据质量。语音数据通过专业声源采集、说话人分离和声纹聚类技术处理,最终为每个角色选定最具代表性的参考音频。
特点
该数据集最显著的特点是实现了多模态角色扮演的完整闭环,包含112k条带参考音频的对话样本,覆盖98个跨语言、跨性别的影视游戏角色。每个角色配备完整的元数据档案,包括性格特征、背景故事和典型台词,其语音数据精准捕捉了音色、韵律等声学特征。数据分布上兼顾内部推理、经验叙述和社交沟通三大对话类型,测试集特别设计未见角色以评估模型泛化能力。
使用方法
研究人员可通过两种范式利用该数据集:级联系统(ASR-LLM-TTS管线)或端到端模型进行语音角色扮演实验。数据集提供标准化的训练/验证/测试划分,支持基于SpeechRole-Eval基准的自动化评估,涵盖交互能力、语音表现力和角色一致性等8项指标。为提升研究效率,建议采用参考音频的声纹嵌入进行说话人相似度优化,并利用角色元数据增强生成内容的一致性。
背景与挑战
背景概述
SpeechRole-Data是由复旦大学与字节跳动等机构于2025年联合构建的大规模语音角色扮演数据集,旨在填补语音模态在角色扮演智能体(SRPAs)系统性评估领域的空白。该数据集包含98个具有鲜明声学特征的虚构角色和11.2万条单轮/多轮语音对话,覆盖影视、游戏等多源素材,通过严谨的元数据提取和GPT-4辅助对话生成流程构建。其创新性在于首次将语音特征(音色、韵律)与角色一致性评估相结合,为多模态人机交互研究提供了重要基准。
当前挑战
该数据集主要面临双重挑战:在领域问题层面,需解决语音角色扮演中声学特征与人格特征的多维对齐难题,包括跨语言韵律一致性保持、长对话角色连贯性等核心问题;在构建过程中,需克服多源音频清洗(降噪/说话人分离)、角色声纹特征量化排序、以及生成对话与原始角色设定的语义匹配等工程技术挑战。实验表明,现有端到端模型在语音自然度与角色保真度间仍存在显著权衡。
常用场景
经典使用场景
SpeechRole-Data作为语音角色扮演领域的重要数据集,广泛应用于语音交互系统的开发与评估。其经典使用场景包括构建具备个性化语音特征的虚拟角色,例如在游戏、影视配音和虚拟助手等领域,通过模拟不同角色的音色、韵律和情感表达,实现自然流畅的角色对话。数据集中的多轮对话设计特别适用于复杂交互场景的建模,如剧情推进式游戏或沉浸式教育应用。
实际应用
在实际应用层面,SpeechRole-Data支撑了智能客服、有声读物生成和虚拟偶像等商业化场景的开发。基于该数据集训练的语音角色系统已应用于抖音等平台的互动视频创作,能够根据角色设定自动生成符合人物特征的语音内容。在教育领域,支持历史人物或文学角色的语音再现,为沉浸式学习体验提供技术支持。
衍生相关工作
该数据集催生了多项创新研究,如OmniCharacter提出的跨模态角色扮演框架和MMRole的多模态评估系统。基于SpeechRole-Data的基准测试推动了CosyVoice2、F5-TTS等语音合成模型的优化,相关成果发表在Interspeech等顶级会议。字节跳动等企业利用该数据集开发的端到端语音角色系统,在保持角色音色一致性方面取得显著进展。
以上内容由遇见数据集搜集并总结生成


