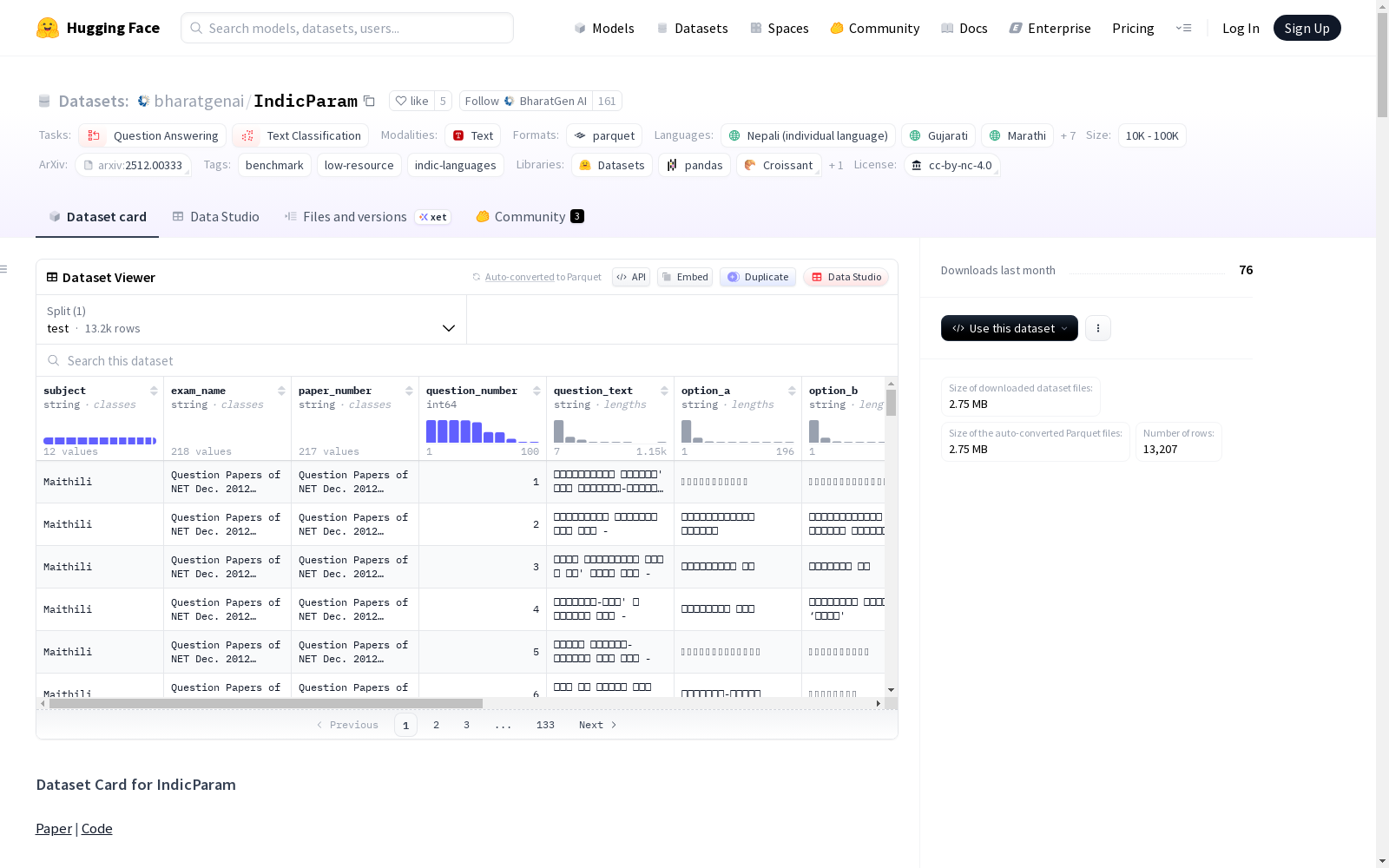
IndicParam
收藏数据集概述:IndicParam
数据集简介
IndicParam 是一个研究生级别的基准测试数据集,旨在评估大型语言模型(LLMs)对低资源及极低资源印度语言的理解能力。该数据集包含13,207道多项选择题(MCQs),涵盖11种印度语言以及一个独立的梵语-英语混合语集,所有题目均源自官方的UGC-NET语言试卷和答案。
支持的任务
multiple-choice-qa:评估LLMs在低资源印度语言上的研究生级别多项选择题问答能力。language-understanding-evaluation:使用明确标注的题目评估语言特定能力(形态学、句法学、语义学、语篇)。general-knowledge-evaluation:衡量在文学、文化、历史及相关学科领域的事实性和领域知识。question-type-evaluation:分析模型在不同MCQ格式(普通MCQ、断言-推理、列表匹配等)上的表现。
语言覆盖
IndicParam 涵盖以下语言及一种混合语变体:
- 低资源语言(4种):尼泊尔语、古吉拉特语、马拉地语、奥里亚语
- 极低资源语言(7种):多格拉语、迈蒂利语、拉贾斯坦语、梵语、博多语、桑塔利语、孔卡尼语
- 混合语:梵语-英语混合语
书写系统:
- 天城文:尼泊尔语、马拉地语、迈蒂利语、孔卡尼语、博多语、多格拉语、拉贾斯坦语、梵语
- 古吉拉特文:古吉拉特语
- 奥里亚文:奥里亚语
- 桑塔利文:桑塔利语
所有问题均以目标语言的原生文字(或梵语-英语混合语形式)呈现。
数据集结构
数据实例
每个实例是UGC-NET语言试卷中的一道MCQ。示例如下(迈蒂利语): json { "unique_question_id": "782166eef1efd963b5db0e8aa42b9a6e", "subject": "Maithili", "exam_name": "Question Papers of NET Dec. 2012 Maithili Paper III hindi", "paper_number": "Question Papers of NET Dec. 2012 Maithili Paper III hindi", "question_number": 1, "question_text": "मिथिलाभाषा रामायण में सीताराम-विवाहक वर्णन भेल अछि -", "option_a": "बालकाण्डमें", "option_b": "अयोध्याकाण्डमे", "option_c": "सुन्दरकाण्डमे", "option_d": "उत्तरकाण्डमे", "correct_answer": "a", "question_type": "Normal MCQ" }
题目范围涵盖:
- 语言理解:语言学和语法(音系学、形态学、句法学、语义学、语篇)。
- 常识:文学、作者、作品、文化概念、历史及相关事实内容。
数据字段
unique_question_id:每道题的唯一标识符。subject:语言/科目名称。exam_name:完整的考试名称(UGC-NET届次和科目)。paper_number:UGC-NET给出的试卷标识符。question_number:在原试卷中的题目序号。question_text:目标语言(或梵语-英语混合语)的题目文本。option_a,option_b,option_c,option_d:四个答案选项。correct_answer:正确选项标签。question_type:题目格式,包括:Normal MCQ、Assertion and Reason、List Matching、Fill in the blanks、Identify incorrect statement、Ordering。
数据划分
IndicParam 仅提供一个单一评估划分:
| 划分 | 题目数量 |
|---|---|
| test | 13,207 |
所有数据行仅用于评估(无专用的训练/验证划分)。
语言分布
基准测试遵循IndicParam论文中报告的分布:
| 语言 | 题目数量 | 书写系统 | 代码 |
|---|---|---|---|
| Nepali | 1,038 | Devanagari | npi |
| Marathi | 1,245 | Devanagari | mar |
| Gujarati | 1,044 | Gujarati | guj |
| Odia | 577 | Orya | ory |
| Maithili | 1,286 | Devanagari | mai |
| Konkani | 1,328 | Devanagari | gom |
| Santali | 873 | Olck | sat |
| Bodo | 1,313 | Devanagari | brx |
| Dogri | 1,027 | Devanagari | doi |
| Rajasthani | 1,190 | Devanagari | – |
| Sanskrit | 1,315 | Devanagari | san |
| Sans-Eng | 971 | (code-mixed) | – |
| 总计 | 13,207 |
每种语言的题目均来自其相应的UGC-NET语言试卷。
数据集创建
来源与收集
- 来源:官方的UGC-NET语言试卷和答案,从UGC-NET/NTA网站下载。
- 范围:涵盖多个考试届次和年份,包括11种语言及梵语-英语混合语的语言/文学和语言学试卷。
- 提取:
- 可直接解析机器可读的PDF。
- 非可选PDF使用OCR处理。
- 所有文本在保留原始文字和内容的同时进行规范化。
标注
除了原始MCQ,每道题还标注了题目类型:
- 题目类型:多项选择、断言-推理、列表匹配、填空、识别错误陈述、排序。
这些标注支持对模型在知识 vs. 语言能力以及题目格式上的行为进行细粒度分析。
使用注意事项
社会影响
IndicParam旨在:
- 实现对代表性不足的印度语言的严格评估,这些语言使用人口众多但网络存在感极低。
- 鼓励构建在印度文字和语言现象上表现稳健的文化根基型AI系统。
- 揭示高资源与低/极低资源印度语言之间的性能差距,为未来的预训练和数据收集工作提供信息。
用户应注意,内容源自学术考试,可能过度代表正式、考试风格的语言,而非日常使用。
评估指南
为确保与论文一致并允许可比性:
- 任务:将每个实例视为具有四个选项的多项选择题问答项目。
- 输入格式:向模型呈现
question_text及四个选项。 - 所需输出:单个选项标签,无需解释。
- 解码:使用贪婪解码 / temperature = 0 /
do_sample = False以确保确定性输出。 - 指标:基于预测选项与
correct_answer的精确匹配计算准确率。 - 分析:
- 报告总体准确率。
- 按语言细分结果。
附加信息
引用信息
若在研究中使用了IndicParam,请引用: bibtex @misc{maheshwari2025indicparambenchmarkevaluatellms, title={IndicParam: Benchmark to evaluate LLMs on low-resource Indic Languages}, author={Ayush Maheshwari and Kaushal Sharma and Vivek Patel and Aditya Maheshwari}, year={2025}, eprint={2512.00333}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2512.00333}, }
许可证
CC-BY-NC-4.0 IndicParam 发布用于非商业研究和评估。
致谢
IndicParam由作者和母语标注者根据论文描述进行整理和标注。感谢UGC-NET/NTA公开考试材料,以及更广泛的印度NLP社区提供的基础工具和资源。