supreme-court-of-india-judgements
收藏Hugging Face2025-01-10 更新2025-01-11 收录
下载链接:
https://huggingface.co/datasets/debkanchan/supreme-court-of-india-judgements
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含印度最高法院所有判决的元数据,如标题、文件名、日期、案件编号、引用、法官和长度等信息。数据集主要用于文本生成和摘要任务,语言为英语,标签包括法律和印度。数据集的大小类别为10K到100K之间。此外,README还提供了如何访问判决PDF文件的说明,并指出数据来源于印度最高法院的数字报告网站。
This dataset contains metadata for all judgments issued by the Supreme Court of India, covering fields such as title, filename, date, case number, citations, presiding judges, and document length. It is primarily designed for text generation and text summarization tasks, with all content in English. The associated labels are "law" and "India". The dataset size ranges from 10K to 100K. Furthermore, the included README offers guidance on accessing the PDF versions of the judgments, and specifies that the data is sourced from the official digital reporting website of the Supreme Court of India.
创建时间:
2025-01-08
原始信息汇总
数据集概述
数据集名称
Supreme Court of India Judgements
数据集描述
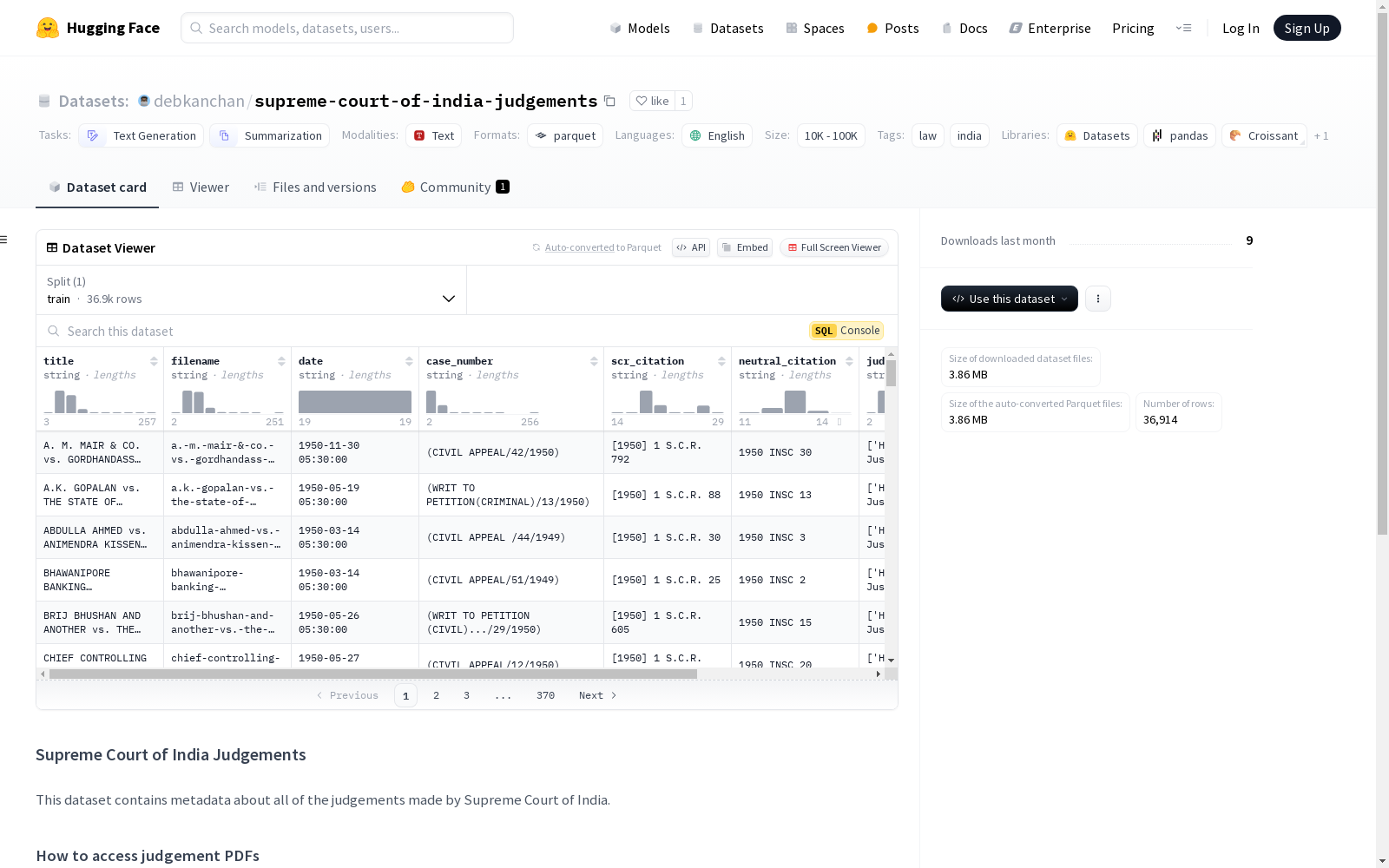
该数据集包含印度最高法院所有判决的元数据。
数据集特征
- title: 判决标题,数据类型为字符串。
- filename: 文件名,数据类型为字符串。
- date: 判决日期,数据类型为字符串。
- case_number: 案件编号,数据类型为字符串。
- scr_citation: SCR引用,数据类型为字符串。
- neutral_citation: 中立引用,数据类型为字符串。
- judges: 法官,数据类型为字符串。
- length: 判决长度,数据类型为浮点数。
数据集分割
- train:
- 字节数: 11851182
- 样本数: 36914
下载信息
- 下载大小: 3857778 字节
- 数据集大小: 11851182 字节
配置
- config_name: default
- data_files:
- split: train
- path: data/train-*
- data_files:
任务类别
- 文本生成
- 摘要生成
语言
- 英语 (en)
标签
- 法律
- 印度
数据集大小类别
- 10K < n < 100K
访问判决PDF
所有判决文件上传至Cloudflare R2存储桶:https://pub-93a7aae0244344319e35611fdc1c80ef.r2.dev
访问特定判决PDF的方法:将判决的filename属性加上".pdf",然后进行URL编码作为路径。
示例:对于filename为"(ex)-capt.-randhir-singh-dhull-vs.-s.-d.-bhambri-,-others"的判决,可以通过以下链接访问PDF:https://pub-93a7aae0244344319e35611fdc1c80ef.r2.dev/(ex)-capt.-randhir-singh-dhull-vs.-s.-d.-bhambri-%26-others.pdf
数据来源
该数据从印度最高法院的数字最高法院报告网站(DigiSCR)抓取:https://digiscr.sci.gov.in
用途
该数据集旨在帮助用户查找和处理最高法院判决,而无需手动抓取数据。
搜集汇总
数据集介绍
构建方式
该数据集通过从印度最高法院的数字报告网站(DigiSCR)中抓取数据构建而成,涵盖了印度最高法院的所有判决记录。每个判决的元数据包括标题、文件名、日期、案件编号、引用信息、法官姓名以及判决长度等字段。数据以结构化形式存储,便于后续的分析和处理。
特点
该数据集的特点在于其全面性和结构化程度。它不仅提供了判决的详细元数据,还通过云存储服务提供了判决的PDF文件链接,用户可以根据文件名直接访问具体的判决文档。数据集涵盖了36914个判决案例,适用于文本生成、摘要生成等自然语言处理任务,尤其适合法律领域的研究和应用。
使用方法
用户可以通过数据集中的`filename`字段生成PDF文件的URL,从而访问具体的判决文档。例如,将文件名进行URL编码并附加到云存储服务的基地址后即可下载对应的PDF文件。此外,数据集的结构化元数据可直接用于文本分析、案例研究或法律信息检索等任务,为法律研究和自动化处理提供了便利。
背景与挑战
背景概述
印度最高法院判决数据集(Supreme Court of India Judgements)是一个专注于法律领域的文本数据集,收录了印度最高法院的判决文书及其相关元数据。该数据集由印度最高法院的数字报告平台(DigiSCR)提供支持,旨在为研究人员、法律从业者以及自然语言处理领域的研究者提供便捷的判决文书访问和分析工具。数据集的核心研究问题在于如何通过自动化手段高效处理和分析大量的法律文本,从而为法律研究、判例分析以及文本生成等任务提供支持。该数据集的创建标志着法律文本数字化进程的重要一步,对法律信息检索、法律文本挖掘等领域具有深远影响。
当前挑战
印度最高法院判决数据集在构建和应用过程中面临多重挑战。首先,法律文本的复杂性和专业性使得自动化的文本处理任务极具挑战性,尤其是在文本生成和摘要任务中,如何准确捕捉法律文书中的关键信息并保持其法律严谨性是一个核心难题。其次,数据集的构建依赖于网络爬虫技术,而法律文书的格式多样性和结构复杂性增加了数据清洗和标准化的难度。此外,数据集的规模较大,如何高效存储和检索这些数据,同时确保数据的完整性和可访问性,也是技术实现中的一大挑战。这些挑战不仅影响了数据集的构建过程,也对后续的研究和应用提出了更高的要求。
常用场景
经典使用场景
在法学研究领域,Supreme Court of India Judgements数据集为研究者提供了一个丰富的资源库,用于分析和理解印度最高法院的判决。该数据集通过提供详细的判决元数据,如案件编号、法官姓名、判决日期等,使得研究者能够深入探讨法律判决的模式、法官的决策倾向以及法律条文的应用情况。
衍生相关工作
基于Supreme Court of India Judgements数据集,已经衍生出多项经典研究工作。例如,有研究利用该数据集开发了自动化的法律文本摘要工具,帮助快速理解复杂的法律文件。此外,还有研究利用这些数据训练机器学习模型,用于预测最高法院的判决结果,这些工作极大地推动了法律科技的发展。
数据集最近研究
最新研究方向
近年来,随着自然语言处理技术的迅猛发展,印度最高法院判决数据集在法学与人工智能交叉领域的研究中展现出重要价值。该数据集不仅为法律文本的自动生成与摘要提供了丰富的语料,还为法律判决的智能分析与预测开辟了新的研究方向。研究者们正致力于利用深度学习模型,从海量判决文本中提取关键法律要素,构建法律知识图谱,以支持司法决策的智能化。此外,该数据集在跨语言法律文本处理、法律术语标准化等领域也展现出广阔的应用前景,为全球法律科技的发展提供了重要参考。
以上内容由遇见数据集搜集并总结生成


