vcr-org/VCR-wiki-zh-hard
收藏Hugging Face2024-07-28 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/vcr-org/VCR-wiki-zh-hard
下载链接
链接失效反馈资源简介:
VCR-Wiki数据集是一个用于视觉字幕恢复(VCR)任务的数据集,旨在评估视觉语言模型在图像中恢复部分遮挡文本的能力。数据集包含图像、字幕、堆叠图像等特征,并提供了训练、验证和测试集的详细信息。数据集构建过程包括数据收集、过滤、n-gram选择、文本嵌入图像创建、图像拼接和二次过滤等步骤。数据集还提供了模型评估的详细方法和结果。
VCR-Wiki数据集是一个用于视觉字幕恢复(VCR)任务的数据集,旨在评估视觉语言模型在图像中恢复部分遮挡文本的能力。数据集包含图像、字幕、堆叠图像等特征,并提供了训练、验证和测试集的详细信息。数据集构建过程包括数据收集、过滤、n-gram选择、文本嵌入图像创建、图像拼接和二次过滤等步骤。数据集还提供了模型评估的详细方法和结果。
提供机构:
vcr-org
原始信息汇总
数据集概述
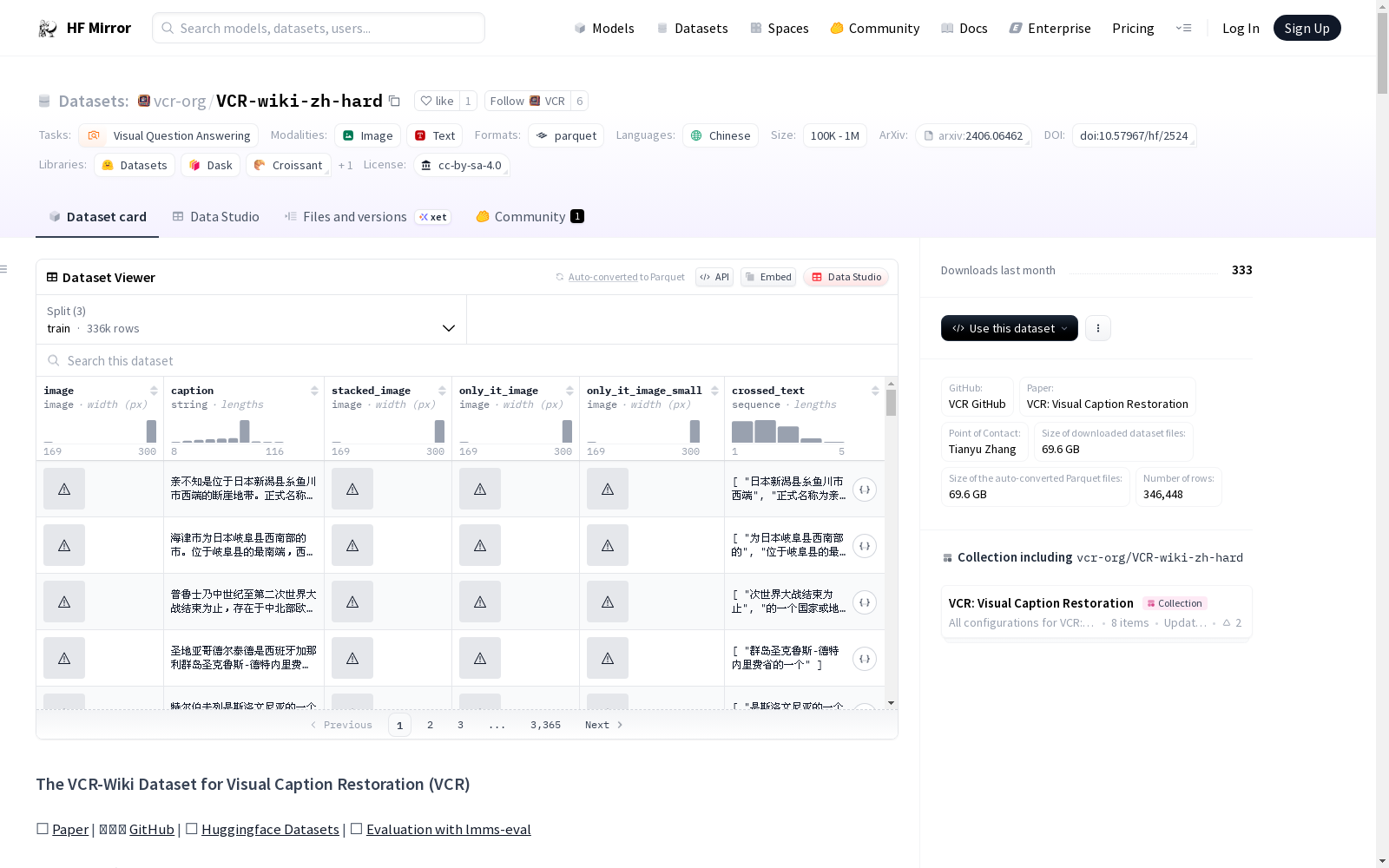
数据集特征
- image:图像数据类型
- caption:字符串数据类型
- stacked_image:图像数据类型
- only_it_image:图像数据类型
- only_it_image_small:图像数据类型
- crossed_text:字符串序列数据类型
数据集分割
- test:包含5000个示例,总大小为1005851898.7488415字节
- validation:包含5000个示例,总大小为1007605144.261219字节
- train:包含336448个示例,总大小为67801347115.279724字节
数据集大小
- 下载大小:69580595287字节
- 数据集总大小:69814804158.28978字节
数据文件配置
- default配置:
- test:路径为
data/test-* - validation:路径为
data/validation-* - train:路径为
data/train-*
- test:路径为
AI搜集汇总
数据集介绍
构建方式
该数据集构建于从[wikimedia/wit_base](https://huggingface.co/datasets/wikimedia/wit_base)收集的原始数据,旨在通过图像中的像素级提示准确恢复部分遮挡的文本。构建过程首先进行数据清洗,去除敏感内容,然后使用spaCy工具对描述进行分词,随机遮挡5-grams,并创建带有文本的图像。最后,将图像与原始视觉图像拼接,形成最终的训练数据。
特点
VCR数据集的特点在于它能够测试视觉语言模型在图像中恢复被遮挡文本的能力。由于遮挡部分通常只有微小的暴露区域,这使得基于文本的处理方法无效。数据集分为训练集、验证集和测试集,每个集合并提供原始图像、带文本的图像、仅文本的图像和被遮挡的n-grams。
使用方法
VCR数据集可通过HuggingFace Datasets平台下载和使用。用户可以根据需要选择训练集、验证集或测试集。数据集提供了多种评估模型性能的方法,包括使用开源脚本、VLMEvalKit框架和lmms-eval框架。此外,用户还可以通过API对闭源模型进行评估。
背景与挑战
背景概述
视觉问答系统在人工智能领域一直是一个重要的研究方向,其核心在于让机器能够理解和回答关于图像的问题。VCR-Wiki数据集应运而生,旨在评估视觉语言模型在视觉标题修复任务中的能力。该数据集由Tianyu Zhang等人于2024年创建,主要研究人员包括来自MILA和Google的专家。VCR-Wiki数据集的核心研究问题是如何利用图像中的像素级线索来准确地恢复被部分遮挡的文本。这一问题的解决对于视觉问答系统的发展具有重要意义,因为它能够提高机器对图像内容的理解和表达能力。
当前挑战
VCR-Wiki数据集所面临的挑战主要包括:1)视觉问答领域的问题挑战:如何准确地恢复被部分遮挡的文本,这需要模型能够理解图像中的像素级线索,以及图像和上下文之间的关系;2)数据集构建过程中的挑战:如何生成具有挑战性的合成图像,以控制任务的难度。此外,由于当前视觉语言模型在VCR任务上的表现与人类相比仍有差距,因此如何提升模型在这一任务上的表现也是一个重要的挑战。
常用场景
经典使用场景
VCR-Wiki数据集旨在评估视觉-语言模型在图像中恢复部分遮挡文本的能力。该数据集的经典使用场景是视觉问题回答(Visual Question Answering, VQA),其中模型需要根据图像内容、上下文和遮蔽文本的微小暴露区域来准确恢复文本。这种任务对OCR和基于文本的处理方法提出了挑战,因为它们无法充分利用图像中的像素级提示。
衍生相关工作
基于VCR-Wiki数据集,研究人员已经开展了多项相关工作。例如,一些研究探索了如何利用图像中的像素级提示来提高文本恢复的准确性,而另一些研究则关注于如何设计更有效的模型结构来处理视觉-语言任务。此外,还有一些研究尝试将VCR-Wiki数据集与其他数据集相结合,以进一步提高模型的性能。
数据集最近研究
最新研究方向
VCR-Wiki 数据集专注于视觉语言模型在视觉字幕恢复任务上的能力。该数据集挑战模型在部分遮挡文本的情况下,利用图像中的像素级提示准确恢复文本的能力。当前研究热点集中在如何提高视觉语言模型在VCR任务上的表现,以及如何利用该数据集评估和改进视觉语言模型在视觉字幕恢复任务上的能力。该数据集的发布对视觉语言模型的评估和改进具有重要意义,有望推动视觉字幕恢复领域的研究发展。
以上内容由AI搜集并总结生成


