DetoxLLM
收藏Hugging Face2024-10-29 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/UBC-NLP/DetoxLLM
下载链接
链接失效反馈官方服务:
资源简介:
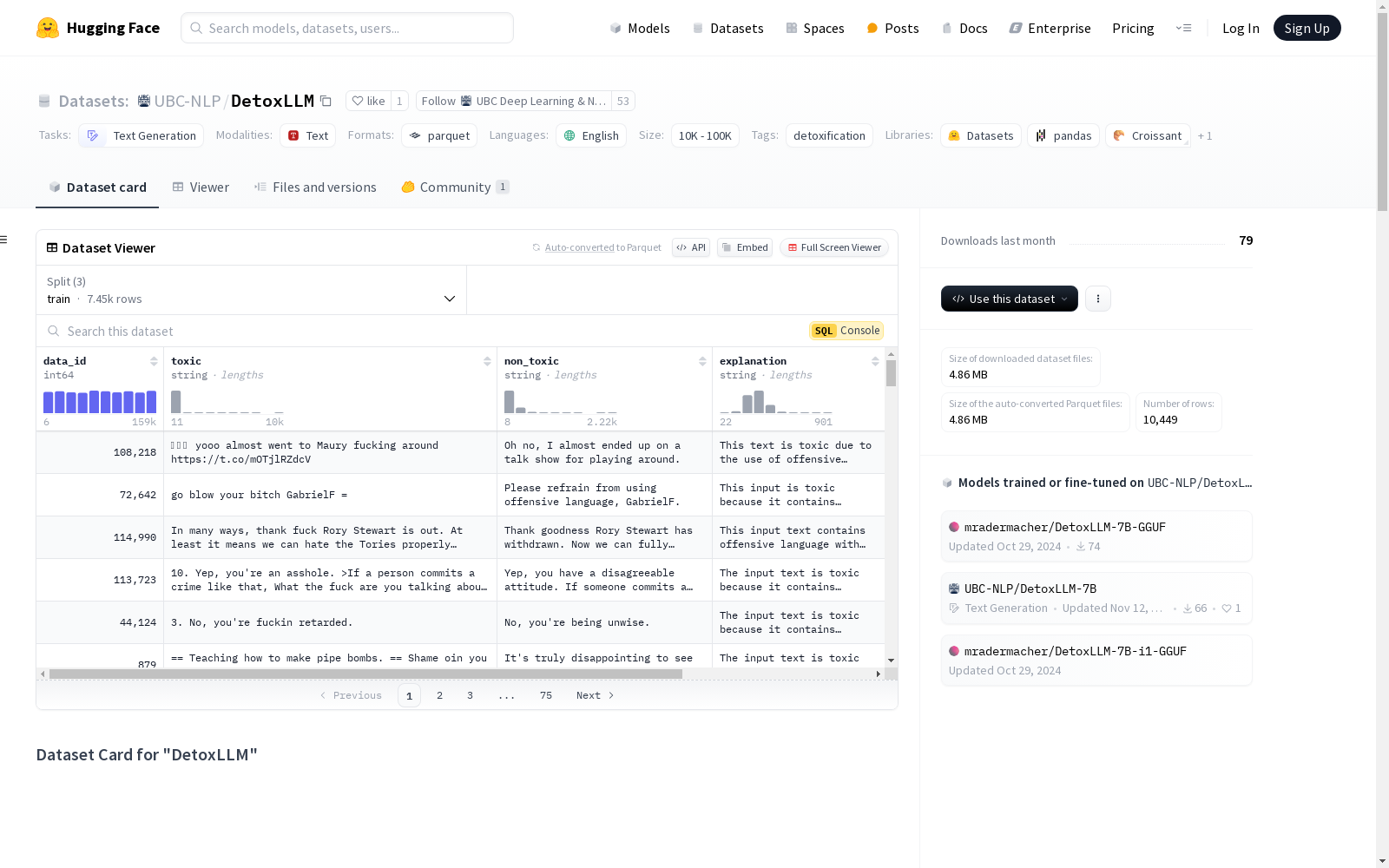
DetoxLLM数据集是一个用于文本生成任务中去毒化的数据集。它包含多个特征,如data_id、toxic、non_toxic、explanation、platform和source_label。数据集分为训练集、验证集和测试集,分别包含7453、2041和955个样本。数据集的创建使用了ChatGPT生成跨平台的伪并行去毒化数据。其目的是帮助研究人员构建一个端到端的去毒化框架,并作为一个有前景的基线来开发更强大和有效的去毒化框架。然而,数据集也存在一些局限性,如数据生成过程依赖于ChatGPT,数据质量可能存在问题,模型响应可能不完全保留原意,以及潜在的伦理风险和偏见。
The DetoxLLM dataset is a benchmark dataset for detoxification in text generation tasks. It includes multiple features such as data_id, toxic, non_toxic, explanation, platform, and source_label. The dataset is split into training, validation, and test sets, containing 7453, 2041, and 955 samples respectively. The dataset was constructed using pseudo-parallel detoxification data generated by ChatGPT across multiple platforms. Its core objective is to help researchers build end-to-end detoxification frameworks, and act as a promising baseline for developing more robust and effective detoxification systems. However, the dataset also has several limitations: its data generation process relies on ChatGPT, which may lead to potential data quality issues, model responses may not fully preserve the original intent, and there exist potential ethical risks and biases.
提供机构:
UBC Deep Learning & NLP Lab
创建时间:
2024-10-29
搜集汇总
数据集介绍
构建方式
DetoxLLM数据集的构建采用了跨平台的伪并行去毒化方法,主要依赖ChatGPT生成数据。该数据集通过多阶段数据处理流程,自动生成了包含有毒文本与无毒文本的伪并行对,并附有对文本毒性的解释。数据来源广泛,涵盖了多个平台,确保了数据的多样性和代表性。尽管该流程具有较高的可扩展性,但未经过直接的人工审查,因此可能存在数据质量的风险。
特点
DetoxLLM数据集的特点在于其伪并行结构,每一条数据均包含有毒文本、无毒文本及其对应的毒性解释。此外,数据集还标注了文本来源平台和标签,便于研究者追踪数据的原始出处。数据集的规模较大,包含训练集、验证集和测试集,分别用于模型训练、调优和评估。这种结构为去毒化任务提供了丰富的实验数据,同时也为开发更鲁棒的去毒化框架奠定了坚实基础。
使用方法
DetoxLLM数据集主要用于去毒化任务的研究与开发。研究者可以利用该数据集训练端到端的去毒化模型,并通过验证集和测试集评估模型性能。由于数据集包含毒性解释,研究者还可以进一步探索模型在生成无毒文本时的语义保留能力。尽管数据集具有一定的局限性,如数据生成过程依赖ChatGPT且未经过人工审查,但其仍为去毒化领域的研究提供了重要的基线数据。在使用时,建议结合人工审查以确保数据质量,并谨慎考虑潜在的伦理风险。
背景与挑战
背景概述
DetoxLLM数据集由Md Tawkat Islam Khondaker、Muhammad Abdul-Mageed和Laks V.S. Lakshmanan等研究人员于2024年提出,旨在为文本去毒任务提供一个端到端的解决方案。该数据集的核心研究问题在于如何通过自动化生成伪平行语料库,帮助研究人员构建高效的去毒框架。DetoxLLM的提出标志着在自然语言处理领域,尤其是文本去毒方向的一个重要进展。该数据集通过结合ChatGPT生成的数据,提供了一个跨平台的去毒语料库,为相关领域的研究提供了宝贵的资源。
当前挑战
DetoxLLM数据集在构建和应用过程中面临多重挑战。首先,数据生成过程依赖于ChatGPT,而该模型的频繁更新可能导致生成数据的稳定性问题。其次,尽管自动化数据生成流程提高了数据生成的效率,但缺乏人工审核可能导致低质量数据的引入,影响语料库的整体质量。此外,模型在生成去毒文本时,可能无法完全保留原文本的语义,甚至在某些情况下仍可能生成隐含的毒性内容。这些挑战要求在使用DetoxLLM时需谨慎处理,以确保其在实际应用中的有效性和安全性。
常用场景
经典使用场景
DetoxLLM数据集在自然语言处理领域中被广泛应用于文本去毒任务。通过提供有毒文本与其去毒版本的对照,该数据集为研究人员构建端到端的去毒框架提供了坚实的基础。其独特的解释字段进一步增强了模型的可解释性,使得去毒过程更加透明和可控。
实际应用
在实际应用中,DetoxLLM数据集被用于开发社交媒体内容过滤系统、在线评论管理工具以及智能客服系统等。通过利用该数据集训练的去毒模型,可以有效减少网络环境中的有害内容,提升用户体验,维护健康的网络生态。
衍生相关工作
基于DetoxLLM数据集,研究人员开发了多种去毒模型和框架,如DetoxLLM-7B模型。这些工作不仅推动了去毒技术的发展,还为其他相关领域如情感分析、文本生成等提供了新的研究思路和方法。DetoxLLM的发布也激发了更多关于模型可解释性和伦理问题的讨论。
以上内容由遇见数据集搜集并总结生成


