CUMCM-2025c-dataset
收藏Hugging Face2025-11-01 更新2025-11-02 收录
下载链接:
https://huggingface.co/datasets/cumcm-dataset/CUMCM-2025c-dataset
下载链接
链接失效反馈官方服务:
资源简介:
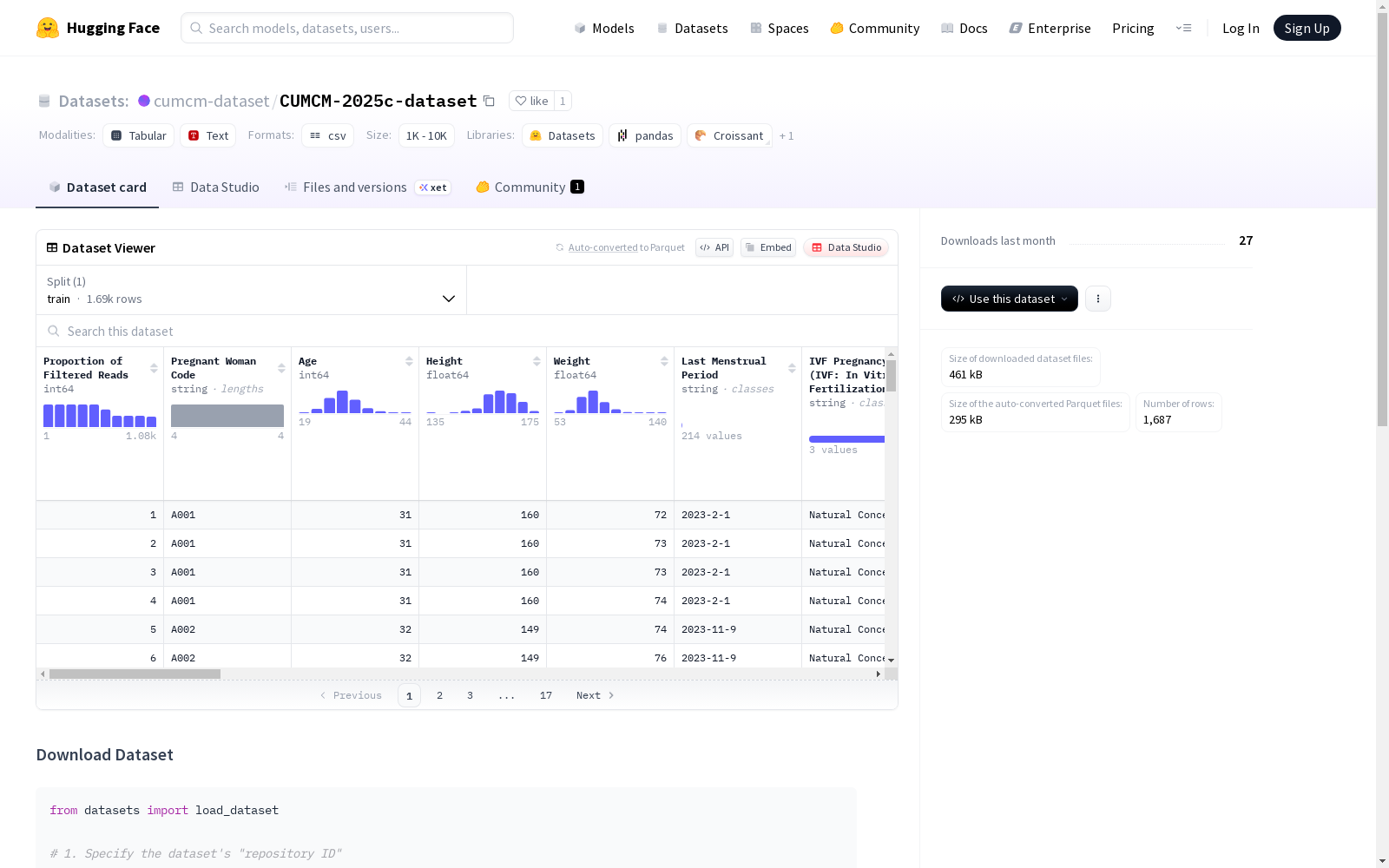
这是一个关于孕妇健康和胎儿发育的数据集,包含了如孕妇代码、年龄、身高、体重、最后一次月经周期、是否为试管婴儿等信息。数据集共有1687条记录,涵盖了孕妇的基本信息、染色体相关指标、生育历史以及胎儿健康状况等特征。
创建时间:
2025-10-24
原始信息汇总
CUMCM-2025c数据集概述
基本信息
- 数据集名称:CUMCM-2025c数据集
- 存储库ID:cumcm-dataset/CUMCM-2025c-dataset
- 数据文件:CUMCM-2025C.csv
- 编码格式:GBK
- 数据分割:训练集
- 样本数量:1,687条
数据特征
数据集包含32个特征字段:
孕妇基本信息
- 孕妇代码
- 年龄
- 身高
- 体重
- 末次月经时间
- 体外受精妊娠情况
- 检测日期
- 检测抽血次数
- 检测时孕周
- 孕妇BMI指数
- 怀孕次数
- 分娩次数
基因测序数据
- 原始读数数量
- 过滤读数比例
- 比对参考基因组比例
- 重复读数比例
- 唯一比对读数数量
- GC含量
染色体分析指标
- 染色体13 Z分数
- 染色体18 Z分数
- 染色体21 Z分数
- 染色体X Z分数
- 染色体Y Z分数
- 染色体Y浓度
- 染色体X浓度
- 染色体13 GC含量
- 染色体18 GC含量
- 染色体21 GC含量
- 过滤读数比例(重复字段)
胎儿健康状态
- 染色体非整倍体情况(如T13、T18、T21分别代表13、18、21三体)
- 胎儿健康状况(是/否)
- 胎儿类型(如男性胎儿)
数据用途
该数据集适用于胎儿染色体异常检测相关的医学研究和数据分析任务。
搜集汇总
数据集介绍
构建方式
在产前筛查领域,CUMCM-2025c-dataset通过收集1687名孕妇的临床检测数据构建而成,涵盖孕产妇基本体征、无创DNA检测指标及胎儿健康状况等多维度信息。数据以结构化表格形式存储,包含过滤读段比例、染色体Z值、GC含量等关键生物标志物,所有字段均采用标准化编码确保数据一致性。
特点
该数据集最显著的特点是覆盖了与染色体非整倍体异常直接相关的核心特征,包括13/18/21/X/Y染色体的Z值分布与浓度指标。通过整合孕周、BMI等临床背景参数,形成了生物学指标与临床表型的立体关联。数据规模适中且特征维度丰富,为产前诊断模型开发提供了扎实的基础。
使用方法
研究者可通过HuggingFace平台的load_dataset接口直接加载数据,指定仓库ID即可自动完成下载与解析流程。数据集以字典结构组织,支持对训练集的切片访问与特征遍历。典型应用场景包括构建胎儿健康状态分类模型或染色体异常风险预测系统,原始数据需经过特征工程处理后方可输入机器学习算法。
背景与挑战
背景概述
在无创产前检测技术快速发展的背景下,CUMCM-2025c-dataset作为中国大学生数学建模竞赛的专用数据集应运而生。该数据集聚焦于通过孕妇外周血游离DNA分析实现胎儿染色体非整倍体异常的无创筛查,涵盖了孕妇生理参数、测序质量指标及染色体Z值等关键特征。其构建体现了多学科交叉研究趋势,为生物信息学与临床医学的融合提供了标准化数据支撑,对推动产前诊断技术的精准化发展具有重要参考价值。
当前挑战
该数据集需解决胎儿染色体异常检测中生物信息学特征与临床表型的复杂映射问题,包括测序数据质量波动对Z值稳定性的影响、多染色体异常模式的协同判别等核心难点。在构建过程中面临临床数据标准化采集的挑战,如孕妇生理参数记录的完整性保障、不同测序平台数据的兼容性处理,以及胎儿健康状态标签的医学验证等实际困难。
常用场景
经典使用场景
在产前筛查领域,CUMCM-2025c-dataset作为无创DNA检测数据的典型代表,其经典使用场景聚焦于通过孕妇外周血游离DNA分析胎儿染色体异常风险。数据集整合了孕妇生理指标、测序质量参数及染色体Z值评分等关键特征,为构建染色体非整倍体疾病的风险预测模型提供了标准化数据基础。研究人员可基于该数据集开发机器学习分类器,实现对唐氏综合征等常见染色体疾病的自动化筛查,显著提升产前诊断的覆盖范围与效率。
解决学术问题
该数据集有效解决了产前诊断领域样本标注稀缺、多模态特征关联复杂等学术难题。通过提供包含临床表型与基因组学特征的配对数据,支持研究者探索生物信息学指标与胎儿健康状态的潜在关联机制。其标准化数据格式突破了传统医学研究中数据异构性的壁垒,为建立可解释的染色体异常检测算法提供了验证平台,推动了围产医学与生物信息学的跨学科融合。
衍生相关工作
基于该数据集衍生的经典研究包括《基于集成学习的胎儿染色体异常预测模型》与《多模态特征融合的产前筛查系统优化》。这些工作通过引入注意力机制改进Z值评分算法的敏感性,结合GC含量与测序深度参数构建动态风险评估框架。后续研究进一步拓展了表观遗传标记与染色体浓度的关联分析,形成了从数据预处理到临床决策的全链条方法论体系。
以上内容由遇见数据集搜集并总结生成


