Gutenberg-BookCorpus-Cleaned-Data-English
收藏Hugging Face2025-03-24 更新2025-03-25 收录
下载链接:
https://huggingface.co/datasets/incredible45/Gutenberg-BookCorpus-Cleaned-Data-English
下载链接
链接失效反馈官方服务:
资源简介:
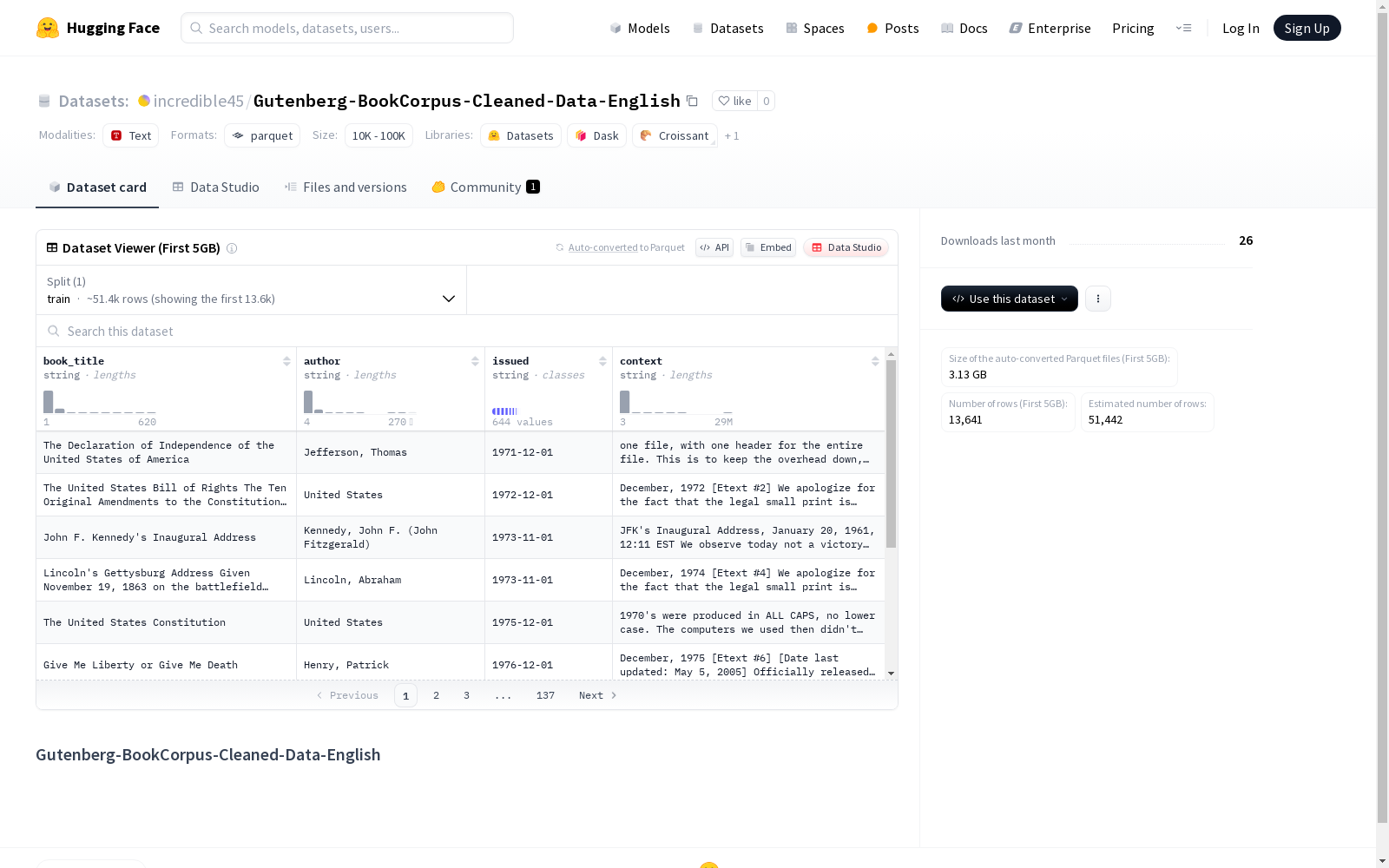
Gutenberg-BookCorpus-Cleaned-数据集是一个英文书籍数据集,包含了书籍标题、作者、发行日期和书籍内容等字段。数据集经过清理,分为训练集,共有58653本书籍数据,数据集大小为21143542108字节。
创建时间:
2025-03-21
搜集汇总
数据集介绍
构建方式
Gutenberg-BookCorpus-Cleaned-Data-English数据集基于古登堡计划(Project Gutenberg)的公共领域图书资源构建,通过系统化的数据清洗与结构化处理流程形成标准化语料库。原始文本经过去重、格式统一、元数据提取等处理步骤,确保每本图书包含规范的标题、作者、出版年份及正文内容字段,最终形成包含58,653册图书的大规模英文文本数据集。
特点
该数据集以高质量文学文本为核心特征,涵盖小说、散文等多种体裁,时间跨度覆盖数个世纪,具有显著的历史语言学研究价值。其独特之处在于完整保留了原始图书的元信息结构,包括精确的作者署名与出版年代标注,为文本生成、风格分析等NLP任务提供了丰富的上下文特征。数据经过专业清洗处理,有效解决了原始文本中的编码混乱、排版错误等问题。
使用方法
研究者可通过HuggingFace数据集库直接加载该语料库,默认配置下自动划分为训练集。建议结合transformers库进行文本预处理,特别适用于语言模型预训练、文学风格迁移等任务。数据字段设计符合标准NLP输入格式,其中context字段可直接用于自监督学习,而元数据字段支持细粒度的作者或时期分类研究。
背景与挑战
背景概述
Gutenberg-BookCorpus-Cleaned-Data-English数据集源于古登堡计划这一历史悠久的数字图书馆项目,该项目自1971年由Michael Hart创立以来,致力于将公共版权领域的文学作品数字化。该数据集由研究团队对原始语料进行系统化清洗和结构化处理,旨在为自然语言处理领域提供高质量的英文文学文本资源。其核心研究问题聚焦于如何从非结构化的原始文本中提取标准化、可计算的语料,以支持机器阅读理解、文本生成等下游任务。作为早期大规模电子书语料库之一,该数据集对计算语言学、数字人文等领域产生了深远影响,为语言模型预训练提供了重要基础数据。
当前挑战
该数据集面临的核心挑战主要体现在领域问题和构建过程两个维度。在领域层面,文学文本特有的长距离依赖关系、复杂叙事结构和古旧语言用法,对现代自然语言处理模型的理解能力提出了严峻考验。构建过程中的技术挑战则包括:原始扫描文本的光学字符识别错误校正,不同版本电子书的去重与合并,以及元数据缺失或不一致的标准化处理。此外,历史文献中的拼写变体和印刷错误,要求开发复杂的文本规范化流程,这些因素共同构成了该数据集在质量和可用性方面的主要技术壁垒。
常用场景
经典使用场景
在自然语言处理领域,Gutenberg-BookCorpus-Cleaned-Data-English数据集因其丰富的文学文本资源而备受青睐。该数据集常被用于训练和评估语言模型,尤其是在文本生成、语义理解和风格迁移等任务中展现出卓越性能。研究人员通过分析不同时期和风格的文学作品,能够深入探索语言演变的规律和文学表达的多样性。
解决学术问题
该数据集有效解决了文学计算研究中高质量语料匮乏的难题,为语言模型预训练提供了规模庞大且经过清洗的文本资源。其覆盖多个世纪和流派的文学作品,使学者能够系统研究历时语言变化、作者风格识别以及跨文化叙事比较等核心问题,极大推动了数字人文和计算语言学的发展。
衍生相关工作
基于该数据集衍生的经典研究包括BERT等预训练语言模型的文学适应性改进,以及针对特定文学流派生成的专用模型。在作者归属研究领域,学者们构建了基于该数据集的风格特征提取框架,相关成果发表在计算语言学顶会上,开创了文学计算的新范式。
以上内容由遇见数据集搜集并总结生成


