Multi-Image Relational Benchmark (MIRB)
收藏arXiv2024-06-19 更新2024-06-20 收录
下载链接:
https://huggingface.co/datasets/VLLMs/MIRB
下载链接
链接失效反馈官方服务:
资源简介:
Multi-Image Relational Benchmark (MIRB) 是由爱丁堡大学和同济大学共同创建的数据集,旨在评估视觉语言模型在多图像理解方面的能力。该数据集包含925个样本,涵盖感知、视觉世界知识、推理和多跳推理四个维度,每个样本至少需要处理2张图像。MIRB的创建过程涉及从多个来源独立收集图像,并设计了一系列需要跨图像比较和分析的任务。该数据集的应用领域广泛,包括但不限于机器人视觉、医学图像分析和在线购物比较,旨在推动多模态模型在处理复杂视觉场景中的发展。
Multi-Image Relational Benchmark (MIRB) is a dataset jointly created by the University of Edinburgh and Tongji University, which aims to evaluate the capabilities of vision-language models in multi-image understanding. This dataset includes 925 samples covering four dimensions: perception, visual world knowledge, reasoning, and multi-hop reasoning, and each sample requires processing at least two images. The development of MIRB involves independently collecting images from multiple sources and designing a series of tasks that require cross-image comparison and analysis. This dataset has a wide range of application scenarios, including but not limited to robotic vision, medical image analysis and online shopping comparison, and is designed to promote the development of multimodal models in handling complex visual scenarios.
提供机构:
爱丁堡大学 同济大学
创建时间:
2024-06-19
搜集汇总
数据集介绍
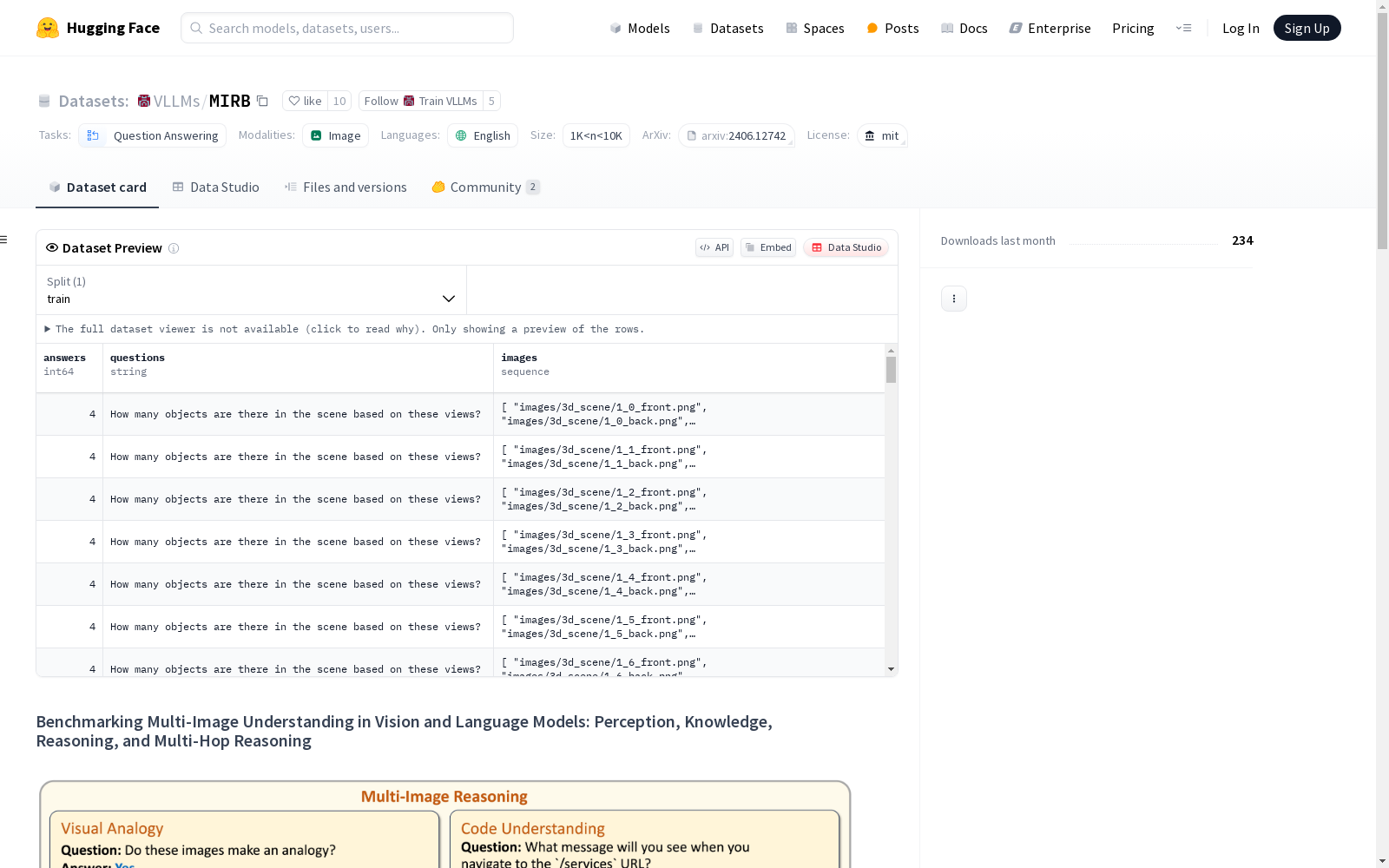
构建方式
Multi-Image Relational Benchmark (MIRB) 数据集的构建旨在评估视觉语言模型(VLMs)在多图像理解任务中的表现。该数据集通过设计四个主要类别的问题:感知、视觉世界知识、推理和多跳推理,涵盖了从简单的图像对比到复杂的跨图像推理任务。数据集的图像来源多样,包括从Python库中提取的代码截图、Matplotlib生成的图表、Blender渲染的3D场景、以及从Pixabay、OpenFoodFact等公开资源中筛选的图像。每个任务都要求模型通过比较和分析多张图像来得出答案,确保任务无法通过单一图像解决。
特点
MIRB 数据集的特点在于其多样性和复杂性。它不仅涵盖了多图像推理的多个维度,还通过独立来源的图像构建任务,避免了视频帧冗余带来的偏差。数据集中的任务设计旨在挑战当前视觉语言模型的极限,尤其是在多图像推理和跨图像关联方面。此外,MIRB 还提供了丰富的任务类型,包括代码理解、视觉类比、3D场景理解、食物成分比较等,确保了对模型能力的全面评估。
使用方法
MIRB 数据集的使用方法主要围绕对视觉语言模型的多图像推理能力进行评估。研究人员可以通过该数据集测试模型在感知、视觉世界知识、推理和多跳推理等任务中的表现。数据集提供了多种任务类型,包括选择题和自由回答题,用户可以通过对比不同模型在这些任务上的表现,评估其在多图像理解任务中的优劣。此外,MIRB 还支持对模型输入格式的探索,例如测试模型在拼接图像与单独图像输入下的表现差异,从而为模型设计和训练提供有价值的参考。
背景与挑战
背景概述
Multi-Image Relational Benchmark (MIRB) 是由爱丁堡大学和同济大学的研究团队于2024年提出的一个多图像理解基准测试数据集。该数据集旨在评估视觉语言模型(VLMs)在跨多图像比较、分析和推理方面的能力。MIRB的提出填补了现有基准测试主要关注单图像输入的空白,涵盖了感知、视觉世界知识、推理和多跳推理四个主要维度。通过广泛的实验,研究团队发现,尽管开源模型在单图像任务中表现接近GPT-4V,但在多图像推理任务中仍存在显著的性能差距。MIRB的推出为开发下一代多模态模型提供了重要的测试平台。
当前挑战
MIRB数据集面临的挑战主要体现在两个方面。首先,多图像推理任务的复杂性要求模型具备跨图像的综合理解能力,而现有模型在处理多图像输入时表现不佳,尤其是在视觉世界知识和多跳推理任务中,开源模型甚至无法超越随机基线。其次,数据集的构建过程中,研究人员需要设计多样化的任务类型,确保每个任务都要求模型通过多图像比较来解决问题。此外,如何有效编码多图像输入、避免冗余信息以及确保模型能够准确理解图像中的文本内容,也是构建过程中的主要挑战。这些挑战凸显了当前视觉语言模型在多图像理解方面的局限性,并为未来的研究提供了明确的方向。
常用场景
经典使用场景
Multi-Image Relational Benchmark (MIRB) 主要用于评估视觉语言模型(VLMs)在多图像理解任务中的表现。该数据集通过设计多种任务,如多图像推理、视觉世界知识、感知和多跳推理,要求模型在多个图像之间进行比较、分析和推理。经典使用场景包括代码理解、视觉类比、3D场景理解等任务,这些任务要求模型能够从多个图像中提取信息并进行复杂的推理。
衍生相关工作
MIRB 的推出催生了一系列相关研究工作,尤其是在多模态模型的评估和改进方面。例如,基于 MIRB 的研究工作探索了如何通过改进模型架构和训练数据来提升多图像推理能力。此外,MIRB 还启发了其他多图像基准测试的开发,如 BLINK 和 Memontos,这些工作进一步扩展了多模态模型在复杂推理任务中的应用场景。
数据集最近研究
最新研究方向
近年来,随着多模态大语言模型(VLMs)的快速发展,其在视觉与语言结合任务中的应用日益广泛。然而,现有的基准测试主要集中于单图像输入的理解,忽视了多图像推理这一关键能力。Multi-Image Relational Benchmark (MIRB) 的提出填补了这一空白,旨在评估模型在跨多图像比较、分析和推理方面的能力。MIRB 包含感知、视觉世界知识、推理和多跳推理四个维度,涵盖了从简单的图像对比到复杂的多步推理任务。通过对多个开源和闭源模型的全面评估,研究发现,尽管开源模型在单图像任务中表现接近 GPT-4V,但在多图像推理任务中仍存在显著差距。这一发现不仅揭示了当前模型的局限性,也为未来多模态模型的发展提供了明确的研究方向。MIRB 的推出为开发下一代多模态模型提供了重要的测试平台,推动了视觉与语言结合领域的进一步探索。
相关研究论文
- 1Benchmarking Multi-Image Understanding in Vision and Language Models: Perception, Knowledge, Reasoning, and Multi-Hop Reasoning爱丁堡大学 同济大学 · 2024年
以上内容由遇见数据集搜集并总结生成


