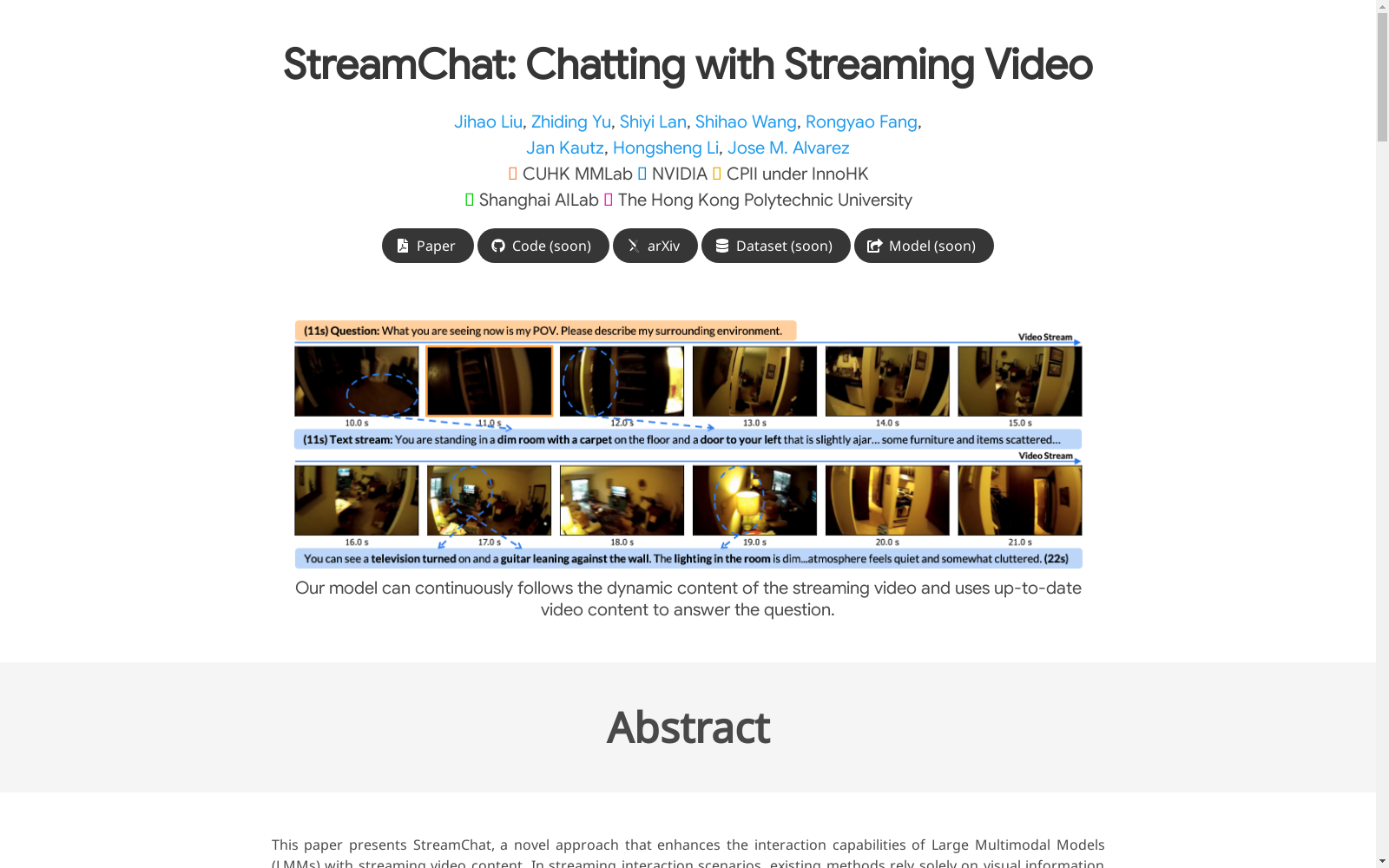
Dense Instruction Dataset
收藏arXiv2024-12-12 更新2024-12-13 收录
下载链接:
https://jihaonew.github.io/projects/streamchat.html
下载链接
链接失效反馈官方服务:
资源简介:
Dense Instruction Dataset是由香港中文大学MMLab和英伟达等机构创建的一个密集指令数据集,旨在支持流式视频交互模型的训练。该数据集包含51,000条指令-答案对,每对都带有时间戳,模拟了流式视频交互的动态变化。数据集的创建过程结合了现有的密集字幕数据集,并通过启发式方法为每个词分配时间戳,确保模型在训练时能够模拟真实的流式交互场景。该数据集主要应用于流式视频交互领域,旨在提升大模态模型在动态视频环境中的交互能力和响应准确性。
Dense Instruction Dataset is a dense instruction dataset created by MMLab of The Chinese University of Hong Kong, NVIDIA and other institutions, aiming to support the training of streaming video interaction models. This dataset contains 51,000 instruction-answer pairs, each accompanied by timestamps, simulating the dynamic changes in streaming video interactions. The dataset was developed by combining existing dense caption datasets, and timestamps were assigned to each word via heuristic methods, ensuring that the model can simulate real streaming interaction scenarios during training. This dataset is primarily applied in the field of streaming video interaction, with the goal of enhancing the interactive ability and response accuracy of large multimodal models in dynamic video environments.
提供机构:
香港中文大学MMLab, 英伟达, 上海人工智能实验室, 香港理工大学
创建时间:
2024-12-12
搜集汇总
数据集介绍
构建方式
Dense Instruction Dataset的构建基于现有的密集标注数据集,通过启发式方法将视频片段与指令-回答对进行配对,并生成时间戳标注。每个指令-回答对中的每个词都被赋予一个时间戳,确保模型在训练过程中只能访问到该时间戳之前的视频信息,从而模拟流式交互的场景。此外,数据集通过并行3D-RoPE机制编码视觉和文本令牌的相对时间信息,以增强模型对动态视频内容的处理能力。
特点
Dense Instruction Dataset的主要特点在于其密集的时间戳标注和启发式生成的时间间隔,使得模型能够在训练过程中模拟流式视频交互的真实场景。数据集中的每个指令-回答对都与视频片段的时间间隔紧密关联,确保模型在解码过程中能够动态更新视觉上下文。此外,数据集通过并行3D-RoPE机制,有效编码了视觉和文本令牌的相对时间信息,提升了模型在流式交互中的表现。
使用方法
Dense Instruction Dataset主要用于训练流式视频交互模型,特别是那些需要在动态视频内容中进行实时响应的模型。使用该数据集时,模型通过注意力掩码机制确保每个文本令牌只能访问到其对应时间戳之前的视频信息,从而模拟流式交互的真实场景。在推理阶段,模型通过并行处理视频流和文本流,动态更新视觉上下文,确保生成的回答与最新的视频内容保持一致。
背景与挑战
背景概述
Dense Instruction Dataset是由NVIDIA、CUHK MMLab等机构的研究人员共同创建的,旨在支持流媒体交互模型的训练。该数据集的构建背景源于现有视频指令调优数据集主要面向离线视频理解,无法有效应对流媒体场景中视频内容动态变化的挑战。Dense Instruction Dataset通过引入时间戳标注和相对时间编码机制,模拟流媒体交互的真实环境,从而为大模态模型(LMMs)在流媒体视频中的实时交互能力提供了关键支持。该数据集的创建不仅填补了现有数据集的空白,还为流媒体交互模型的训练提供了丰富的语料,推动了多模态模型在动态视频理解领域的应用。
当前挑战
Dense Instruction Dataset在构建过程中面临的主要挑战包括:1) 如何有效模拟流媒体场景中视频内容的动态变化,确保模型能够实时更新视觉上下文;2) 如何为每个文本标记分配精确的时间戳,以确保模型在解码过程中仅依赖于当前可用的视频信息;3) 如何在不引入额外推理复杂度的情况下,设计高效的模型架构以处理流媒体视频的动态输入。此外,数据集的构建还面临标注成本高、时间戳分配的准确性难以保证等问题,这些挑战直接影响模型在流媒体交互场景中的表现。
常用场景
经典使用场景
Dense Instruction Dataset 主要用于训练和优化流媒体交互模型,特别是在处理动态视频内容时。该数据集通过提供时间戳标注的指令和答案对,帮助模型在解码过程中动态更新视觉上下文,从而实现对流媒体视频的实时理解和响应。经典使用场景包括实时视频问答、视频内容描述生成以及动态场景分析等,这些场景要求模型能够根据视频的实时变化调整其输出。
实际应用
Dense Instruction Dataset 在实际应用中具有广泛的应用前景,特别是在需要实时视频交互的领域。例如,在智能监控系统中,该数据集可以用于训练模型实时分析监控视频,提供动态场景描述或异常检测;在教育领域,可以用于开发实时视频问答系统,帮助学生通过视频内容进行学习;在娱乐和直播行业,可以用于增强观众的互动体验,提供实时的视频内容解说和问答服务。
衍生相关工作
Dense Instruction Dataset 的提出催生了一系列相关工作,特别是在流媒体交互和动态视频理解领域。例如,基于该数据集的训练方法,研究者们开发了多种流媒体交互模型,如 StreamChat,这些模型通过动态更新视觉上下文,显著提升了流媒体视频的交互体验。此外,该数据集还推动了多模态模型在视频理解中的应用,促进了视频问答、视频描述生成等任务的研究进展。
以上内容由遇见数据集搜集并总结生成


