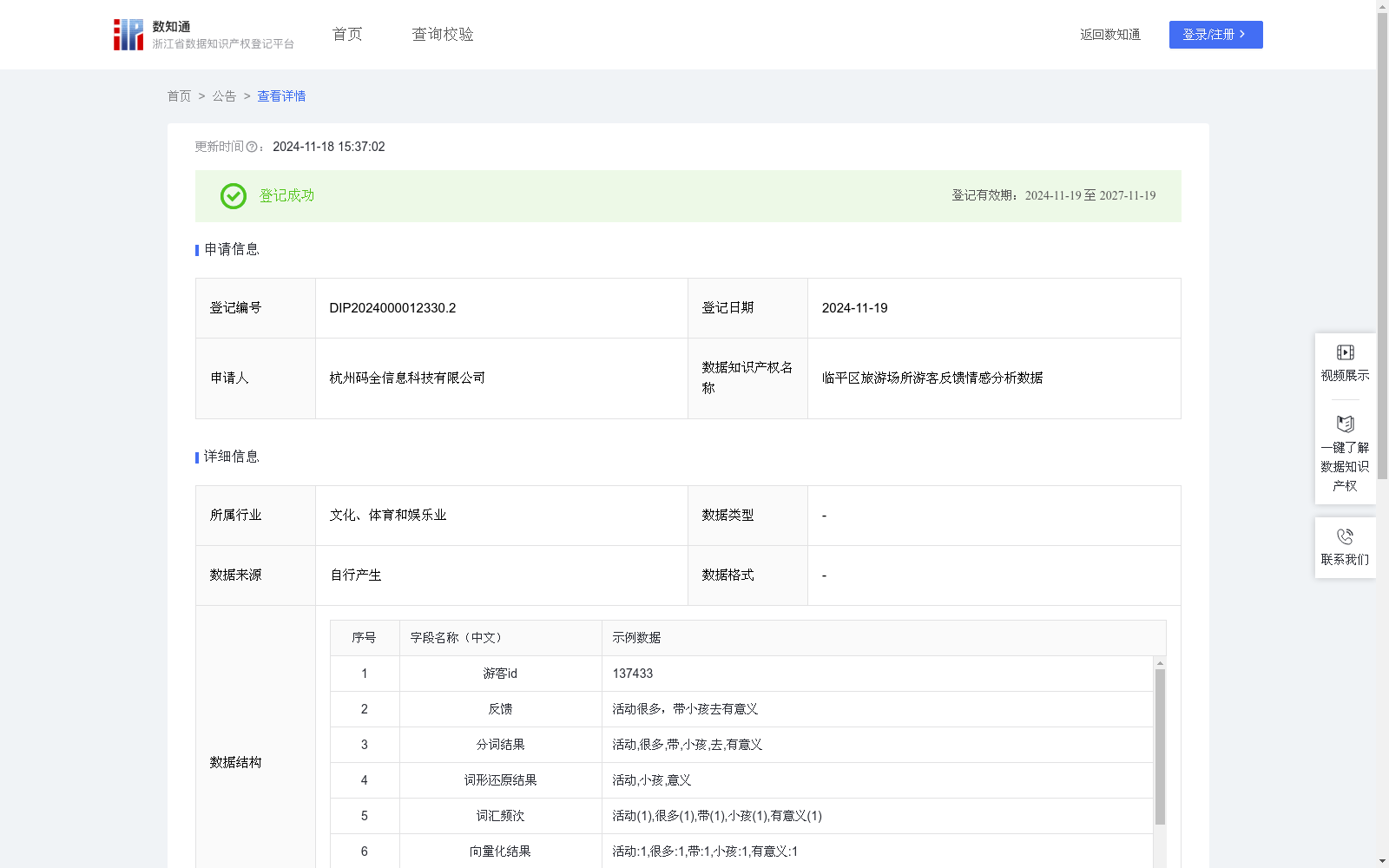
临平区旅游场所游客反馈情感分析数据
收藏浙江省数据知识产权登记平台2024-11-18 更新2024-11-19 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/85952
下载链接
链接失效反馈官方服务:
资源简介:
临平区旅游场所游客反馈情感分析数据的应用场景主要包括:提升游客体验、优化场馆服务、产品创新和市场定位。通过收集和分析游客对旅游场所的反馈,管理者可以识别游客的喜好和不满点,进而针对性地改进服务和体验项目。情感分析可以帮助场馆了解游客对特定旅游活动的情感倾向,评估新推出的体验项目是否受到欢迎,以及监测和改善游客满意度。此外,分析结果可用于制定更加个性化的营销策略,比如针对不同年龄段或兴趣偏好的游客群体推出定制化体验套餐,从而提高旅游场所的吸引力和市场竞争力。1.数据收集和预处理:从公司文化保障卡服务系统中自动抽取临平区旅游场所游客反馈数据(游客id、反馈)。删除无效或错误的数据,如空白条目或非文本字符,确认所有文本数据为同一语言。
2.文本处理:将“反馈”字段的文本切分为单独的词汇,形成分词结果。使用“词形还原结果”,将词汇转换为其基本形态。
3.特征提取:使用词袋模型形成向量化结果。
4.应用朴素贝叶斯算法:根据“情感标签”计算每个特征在不同情感类别下的条件概率。使用朴素贝叶斯公式计算每个文本的情感类别的后验概率,并将其归类为最大概率的情感类别。
5.结果整合:(1)生成标签:结合“情感标签”和“情感强度”,利用Excel函数:IF(AND(情感标签="正面", 归一化情感强度>0.5), "强烈正面", "其他"),为每条反馈生成一个综合的情感标签。(2)上下文调整:根据上下文信息,使用IF、SEARCH、LEN函数进行复杂的逻辑判断。
6.输出结果:利用IF函数生成综合情感标签,Excel函数:IF(情感标签="正面", "正面", IF(情感标签="负面", "负面", "中性"))。
The application scenarios of the sentiment analysis dataset for tourist feedback at tourist attractions in Linping District mainly include enhancing tourist experience, optimizing venue services, product innovation, and market positioning. By collecting and analyzing tourist feedback on these attractions, managers can identify tourists' preferences and pain points, and then make targeted improvements to services and experience projects. Sentiment analysis can help venues understand tourists' emotional tendencies toward specific tourist activities, evaluate the popularity of newly launched experience projects, and monitor and improve tourist satisfaction. In addition, the analysis results can be used to develop more personalized marketing strategies, such as launching customized experience packages for tourist groups of different ages or interest preferences, thereby boosting the attractiveness and market competitiveness of the tourist attractions.
1. Data Collection and Preprocessing: Automatically extract tourist feedback data (including tourist ID and feedback content) of tourist attractions in Linping District from the Corporate Cultural Security Card Service System. Delete invalid or erroneous data such as blank entries or non-text characters, and confirm that all text data is in the same language.
2. Text Processing: Segment the text in the "feedback" field into individual words to obtain word segmentation results. Use lemmatization to convert words into their base forms.
3. Feature Extraction: Generate vectorized results using the bag-of-words model.
4. Naive Bayes Algorithm Application: Calculate the conditional probability of each feature across different sentiment categories based on the "sentiment label" field. Use the Naive Bayes formula to calculate the posterior probability of each text for each sentiment category, and classify the text into the sentiment category with the highest probability.
5. Result Integration:
(1) Label Generation: Combine the "sentiment label" and "sentiment intensity", and use the Excel function IF(AND("sentiment label"="Positive", "normalized sentiment intensity">0.5), "Strongly Positive", "Other") to generate a comprehensive sentiment label for each feedback.
(2) Context Adjustment: Conduct complex logical judgments using IF, SEARCH, and LEN functions based on contextual information.
6. Output Results: Generate comprehensive sentiment labels using the IF function with the Excel formula: IF("sentiment label"="Positive", "Positive", IF("sentiment label"="Negative", "Negative", "Neutral")).
提供机构:
杭州码全信息科技有限公司
创建时间:
2024-10-21
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


