CroQS
收藏arXiv2024-12-18 更新2024-12-24 收录
下载链接:
https://paciosoft.com/CroQS-benchmark/
下载链接
链接失效反馈官方服务:
资源简介:
CroQS数据集是由意大利国家研究委员会-信息科学与技术研究所创建的,专门用于跨模态文本到图像检索中的查询建议任务。该数据集包含50个初始查询,每个查询对应一组图像结果集,并通过人工验证和分组,形成295个语义集群。每个集群都有一个人工定义的建议查询。数据集的创建过程结合了半自动和人工监督的方法,旨在通过视觉线索生成适合的查询建议。CroQS数据集主要应用于跨模态检索领域,旨在通过查询建议提高用户在图像检索中的交互体验和搜索效果。
The CroQS dataset was developed by the Institute of Information Science and Technologies of the Italian National Research Council, and is specifically tailored for the query suggestion task in cross-modal text-to-image retrieval. It includes 50 initial queries, each paired with a corresponding set of image results. Through manual verification and grouping, these are organized into 295 semantic clusters, with each cluster equipped with a manually defined suggested query. The construction of the CroQS dataset adopts a hybrid approach of semi-automatic processing and human supervision, with the objective of generating suitable query suggestions based on visual cues. Primarily utilized in the field of cross-modal retrieval, the CroQS dataset aims to enhance user interaction experience and search efficacy in image retrieval via query suggestions.
提供机构:
意大利国家研究委员会-信息科学与技术研究所
创建时间:
2024-12-18
原始信息汇总
CroQS 数据集概述
数据集名称
CroQS 🐊 Cross-modal Query Suggestion for Text-to-Image Retrieval
数据集描述
CroQS 是一个用于文本到图像检索的跨模态查询建议数据集。该数据集旨在支持跨模态检索任务,特别是文本到图像的检索。
相关会议
- ECIR 2025 Oral
作者信息
- Giacomo Pacini (ISTI CNR, University of Pisa)
- Fabio Carrara (ISTI CNR)
- Nicola Messina (ISTI CNR)
- Nicola Tonellotto (ISTI CNR, University of Pisa)
- Giuseppe Amato (ISTI CNR)
- Fabrizio Falchi (ISTI CNR)
数据集链接
搜集汇总
数据集介绍
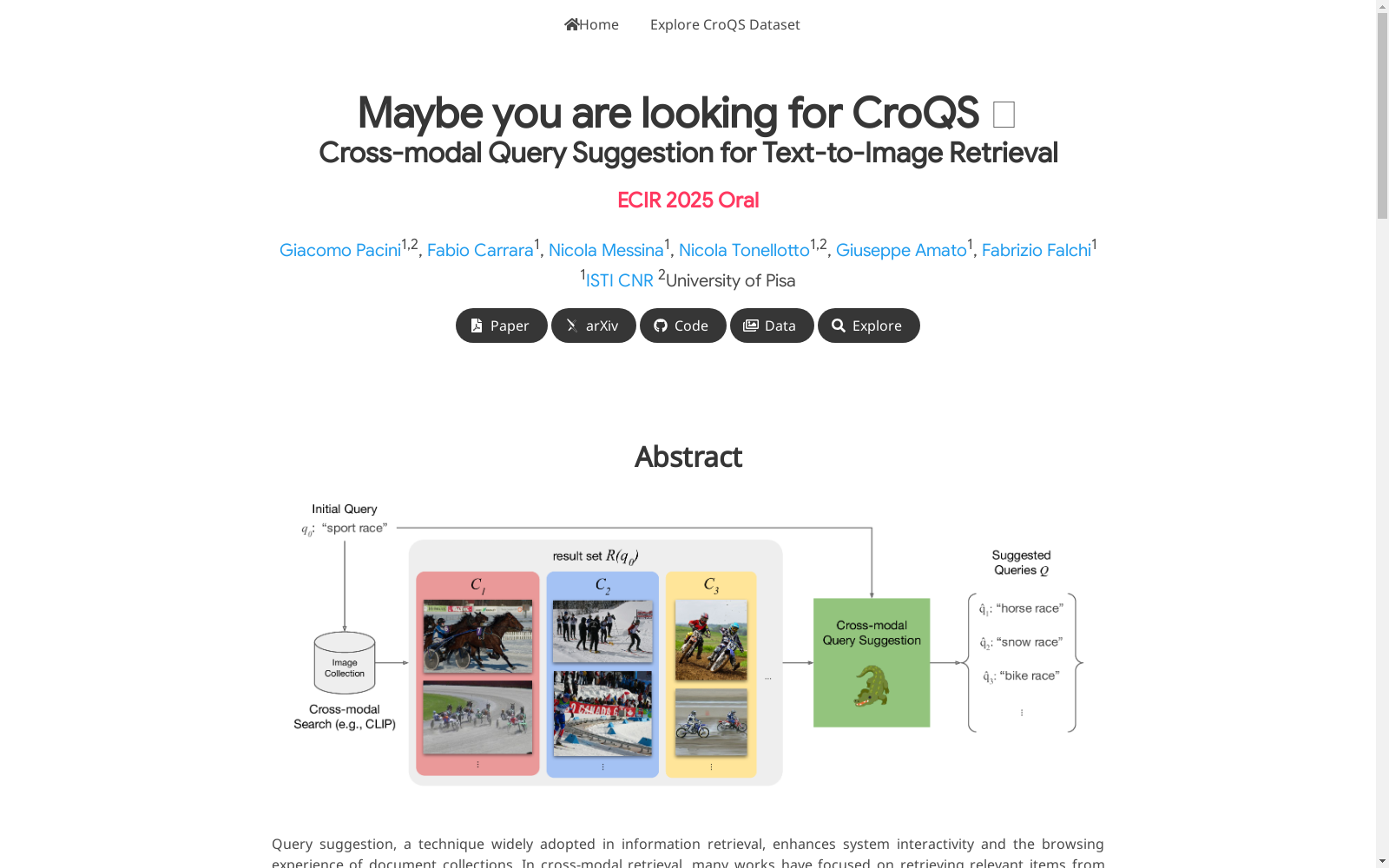
构建方式
CroQS数据集通过半自动、人工监督的过程构建,旨在为跨模态文本到图像检索中的查询建议任务提供一个基准。首先,从初始查询和图像集合中生成语义图像簇,然后通过人工判断对这些簇进行微调,确保每个簇的语义一致性。每个簇还配备了一个由人工定义的参考查询建议,以提供可靠的基准。
特点
CroQS数据集的特点在于其专注于跨模态查询建议任务,涵盖了50个初始文本查询和295个语义图像簇。每个簇都附有人工标注的查询建议,确保了数据集的高质量。此外,数据集基于COCO数据集的训练集构建,但仅使用其图像,摒弃了原有的图像描述,从而专注于无文本元数据的图像检索场景。
使用方法
CroQS数据集主要用于评估跨模态查询建议方法的性能。研究者可以通过该数据集测试不同方法在生成查询建议时的表现,重点关注查询的簇特异性、代表性和与原始查询的相似性。数据集提供了专门的评估指标,如召回率、平均精度等,帮助研究者量化方法的有效性,并推动该领域的进一步发展。
背景与挑战
背景概述
CroQS数据集由意大利国家研究委员会(CNR-ISTI)和比萨大学的研究人员于2024年提出,旨在解决跨模态文本到图像检索中的查询建议问题。该数据集的核心研究问题是如何在缺乏图像文本描述的情况下,通过视觉线索生成适合的查询建议,以帮助用户更好地探索图像集合。CroQS通过半自动化的方式构建,结合了人工监督和图像聚类技术,提供了50个初始查询和295个语义集群,每个集群都有人工定义的建议查询。该数据集的提出填补了跨模态检索领域中查询建议研究的空白,并为相关方法的评估提供了基准。
当前挑战
CroQS数据集面临的挑战主要集中在跨模态检索场景中的查询建议生成。首先,图像集合通常缺乏文本描述或元数据,这使得传统的基于文本的查询建议方法难以直接应用。其次,图像的语义信息可能因上下文而异,静态的文本特征(如图像标题)无法有效捕捉图像的多重含义。此外,生成与原始查询语义一致且能够区分不同图像集群的建议查询也是一个难题。为了应对这些挑战,CroQS引入了专门的评估指标,如集群特异性、代表性和与原始查询的相似性,以量化不同方法的性能。
常用场景
经典使用场景
CroQS数据集的经典使用场景主要集中在跨模态文本到图像检索中的查询建议任务。该数据集通过提供初始查询、分组结果集以及人工定义的建议查询,帮助研究者开发和评估跨模态查询建议系统。这些系统旨在根据检索到的图像内容,生成能够探索视觉一致子集的文本查询建议,从而提升用户在多媒体检索中的交互体验。
实际应用
CroQS数据集在实际应用中具有广泛的应用场景,特别是在多媒体检索和交互式图像浏览领域。例如,在图像搜索引擎中,用户可以通过CroQS生成的查询建议,更精确地探索和定位感兴趣的图像子集。此外,该数据集还可用于视频检索、电子商务图像搜索等场景,帮助用户在无文本描述的情况下,通过视觉线索快速找到所需内容。
衍生相关工作
CroQS数据集的推出催生了一系列相关研究工作。基于图像描述和内容摘要的基线方法被广泛应用于跨模态查询建议任务,如ClipCap和DeCap等模型。此外,大型语言模型(LLMs)也被引入,通过Few-shot学习生成查询建议,如GroupCap架构。这些衍生工作不仅提升了查询建议的准确性,还为跨模态检索领域的进一步研究提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


