GEM/e2e_nlg
收藏Hugging Face2022-10-24 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/GEM/e2e_nlg
下载链接
链接失效反馈官方服务:
资源简介:
E2E NLG数据集是一个用于数据到文本模型的英语基准数据集,主要在餐厅领域将2-9个键值属性对转化为自然语言描述。GEM使用的版本是经过清理的E2E NLG数据集,过滤了包含幻觉和未完全覆盖所有输入属性的样本。数据集包含训练、开发和测试集,分别用于模型训练、验证和测试。数据集的输入是餐厅的属性对,输出是对应的自然语言描述。数据集的主要任务是生成推荐或介绍餐厅的文本,基于输入的所有属性。
The E2E NLG dataset is an English benchmark dataset for data-to-text models, which primarily converts 2 to 9 key-value attribute pairs into natural language descriptions in the restaurant domain. The version used by GEM is a cleaned E2E NLG dataset that filters out samples containing hallucinations and those failing to fully cover all input attributes. The dataset comprises training, validation, and test sets, which are respectively used for model training, validation, and testing. The input of the dataset is restaurant attribute pairs, and the output is the corresponding natural language descriptions. The core task of the dataset is to generate texts for recommending or introducing restaurants based on all input attributes.
提供机构:
GEM
原始信息汇总
数据集概述
数据集描述
- 名称: E2E NLG
- 语言: 英语
- 许可证: cc-by-sa-4.0
- 任务类别: 数据-到-文本
- 数据来源: 原始数据
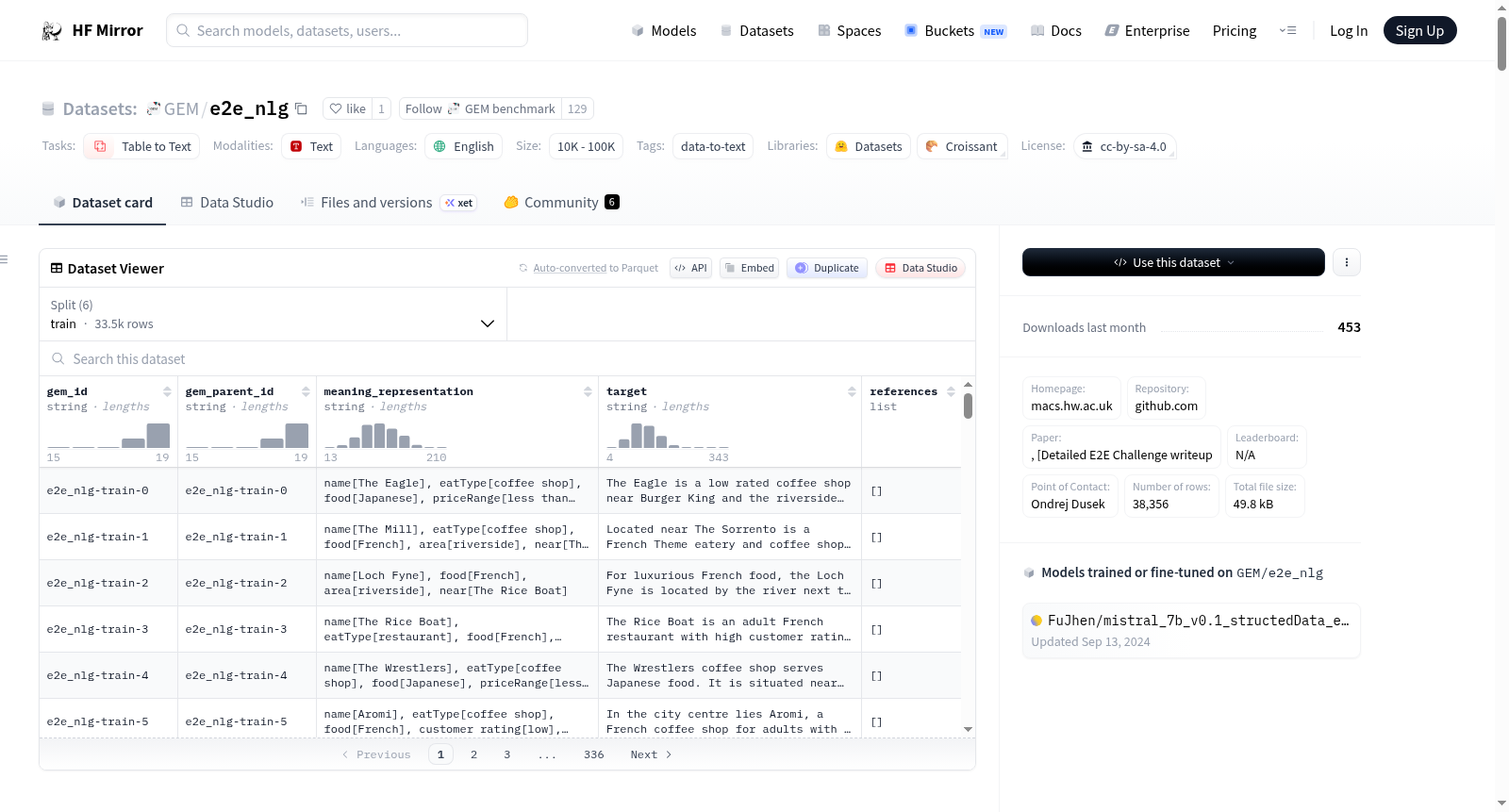
- 数据结构: CSV格式,包含字段
mr(意义表示,输入)和ref(参考,即相应的自然语言描述,输出)
数据集总结
E2E NLG数据集是一个英语基准数据集,用于测试数据到文本模型的能力,该模型将餐馆领域的2-9个键值属性对口头表达出来。GEM使用的版本是经过清理的E2E NLG数据集,该数据集过滤了包含幻觉和未完全覆盖所有输入属性的输出示例。
数据集结构
- 数据字段:
mr- 意义表示(MR,输入)ref- 参考,即相应的自然语言描述(输出)
- 数据分割:
- 训练: 12,568个MRs
- 开发: 1,484个MRs
- 测试: 1,847个MRs
- 分割标准: 数据分割确保不同分割中的MR不重叠。
数据集在GEM中的应用
- GEM特定处理: GEM版本的数据集进行了修改,包括添加了4个特殊测试集,用于测试模型的泛化能力和鲁棒性。
- 评估指标: 使用
BLEU,METEOR,ROUGE等指标进行评估。
数据集创建和维护
- 创建者: Jekaterina Novikova, Ondrej Dusek, Verena Rieser
- 资金来源: EPSRC项目DILiGENt和MaDrIgAL
- 维护计划: 无
使用注意事项
- 版权和许可状态: 开放许可,允许商业使用
- 个人识别信息: 数据集不包含个人识别信息
搜集汇总
数据集介绍
构建方式
在自然语言生成领域,E2E NLG数据集作为一项经典基准,其构建过程体现了严谨的工程化设计。该数据集通过自动化程序随机生成包含2至9个属性对的餐厅领域结构化语义表示,随后借助CrowdFlower平台招募以英语为母语的众包工作者,为每个语义表示创作自然语言描述。为提升数据质量,研究团队后续采用正则表达式算法对原始数据进行清洗,过滤了存在幻觉或属性覆盖不全的样本,最终形成当前使用的洁净版本。
特点
该数据集在数据到文本任务中展现出鲜明的技术特征。其输入采用扁平化的键值对结构,涵盖名称、位置、菜系等八个餐厅属性,同一语义表示常对应多个同义文本描述,有效增强了语言表达的多样性。数据经过精心划分,确保训练集、开发集与测试集的语义表示互不重叠,并提供了基于输入属性数量的子集分析。相较于同类数据集,E2E NLG以其较高的洁净度与有限的领域范围,为模型表面实现能力的评估提供了清晰而直接的测试环境。
使用方法
研究人员可通过Hugging Face的datasets库便捷加载该数据集,其标准字段包括语义表示与对应文本描述。该数据集主要服务于端到端自然语言生成模型的训练与评估,尤其适用于测试模型在给定结构化输入条件下生成流畅、准确文本的能力。在GEM评测框架中,数据集进一步引入了包含输入置乱与长度分层的特殊测试集,用以系统检验模型的泛化性与鲁棒性。评估通常采用BLEU、ROUGE等自动化指标,并辅以人工质量与自然度评分。
背景与挑战
背景概述
E2E NLG数据集由赫瑞瓦特大学的Jekaterina Novikova、Ondrej Dušek与Verena Rieser等研究人员于2017年首次发布,旨在为数据到文本生成领域提供一个标准化的评测基准。该数据集聚焦于餐厅领域的自然语言生成任务,要求模型将包含2至9个属性对的语义表示转化为流畅、准确的描述性文本。作为GEM基准的重要组成部分,其清洗版本通过过滤幻觉输出与不完全覆盖输入属性的实例,显著提升了数据质量,推动了神经自然语言生成模型在受限领域内的研究与应用,成为评估表面实现能力的关键资源。
当前挑战
E2E NLG数据集致力于解决数据到文本生成中的核心挑战,即如何确保生成文本在语法正确、流畅自然的同时,精确无误地覆盖所有输入属性,避免信息遗漏或虚构。在构建过程中,数据集面临两大主要挑战:其一,原始众包数据中存在约40%的实例存在属性对齐偏差或幻觉问题,需通过算法清洗与正则表达式匹配进行修正;其二,为增强模型的泛化与鲁棒性,需设计特殊测试集以评估模型对输入顺序扰乱、属性数量变化等情况的适应能力,这对数据划分与质量控制提出了较高要求。
常用场景
经典使用场景
在自然语言生成领域,E2E NLG数据集作为数据到文本任务的经典基准,广泛应用于评估模型将结构化数据转化为流畅自然语言的能力。该数据集聚焦于餐厅领域,要求模型根据2至9个关键属性值对生成连贯的推荐性描述。其高度规范化的输入输出结构,为研究者提供了可控的实验环境,便于系统性地比较不同神经架构在表面实现任务上的性能差异。
实际应用
在实际应用层面,基于E2E NLG数据集训练的模型可服务于自动化内容生成系统,例如在线旅游平台或餐饮推荐应用中的个性化描述生成。系统能够根据餐厅的属性信息即时生成自然、准确的介绍文本,提升用户体验并降低人工撰写成本。这种技术还可扩展至其他垂直领域,如产品描述生成或结构化报告撰写,展现了数据到文本技术在信息高效传达方面的实用价值。
衍生相关工作
围绕该数据集已衍生出多项经典研究工作,包括最初的E2E挑战赛及后续系统性能深入分析。这些研究比较了序列到序列、模板填充及基于预训练语言模型等不同架构的生成效果。相关工作还探讨了输入扰动、长度泛化等鲁棒性测试,并提出了针对属性覆盖度与语义一致性的评估方法,持续推动着可控文本生成领域的技术演进与理论深化。
以上内容由遇见数据集搜集并总结生成


