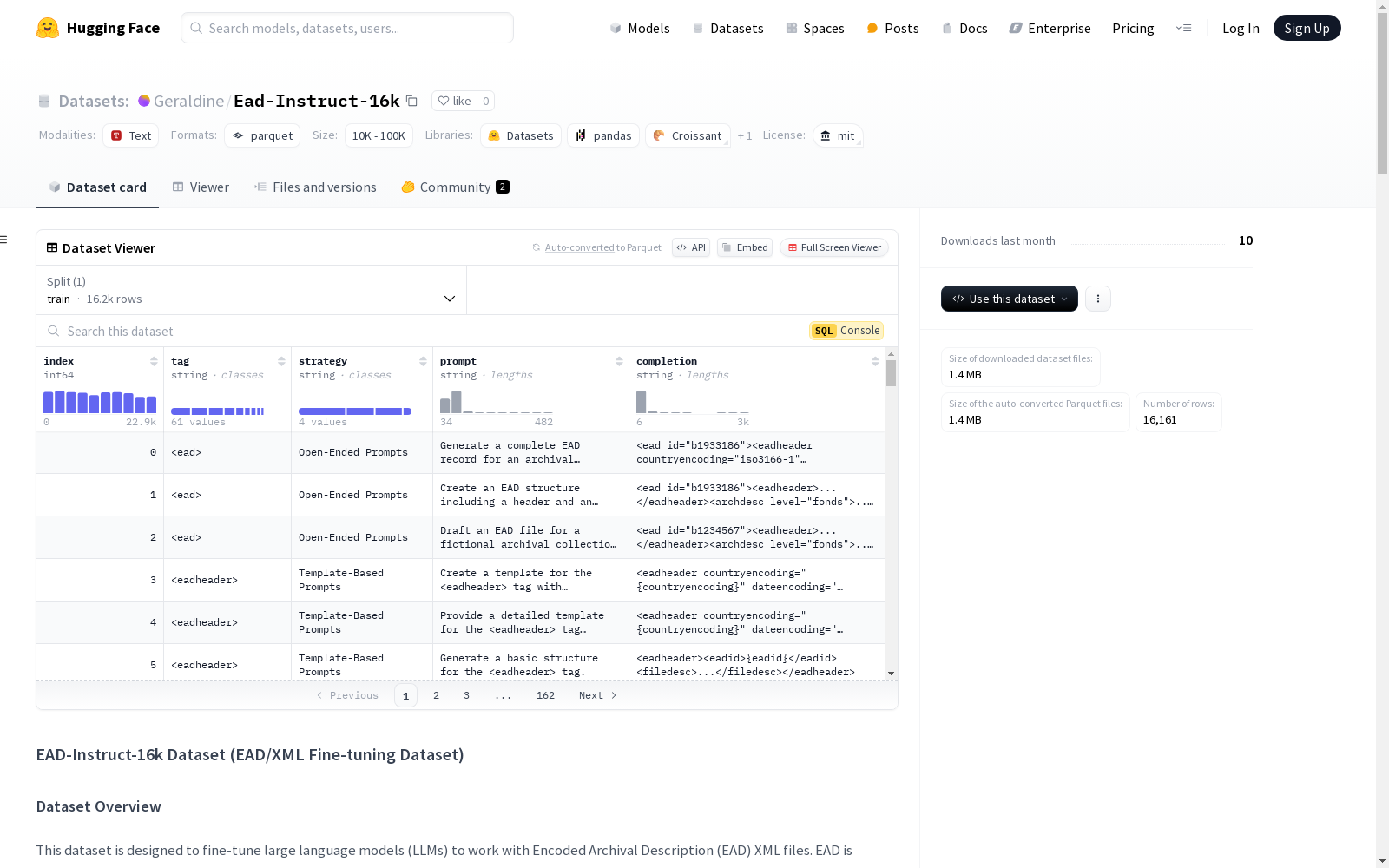
Ead-Instruct-16k
收藏EAD-Instruct-16k 数据集
数据集概述
EAD-Instruct-16k 数据集旨在微调大型语言模型(LLMs)以处理 Encoded Archival Description(EAD)XML 文件。EAD 是一种用于编码档案查找工具的 XML 标准格式,在档案科学中管理和共享元数据方面至关重要。
该数据集由通过混合方法生成的提示-完成对组成,结合了:
- 真实世界的 EAD/XML 数据:完整且符合模式的 EAD 文件。
- 合成数据生成:使用生成语言模型(
gpt-4o-mini)基于预定义策略创建的指令-完成对,以确保 XML 标签和元数据的全面覆盖。
该数据集的主要目标是训练 LLMs 以准确生成、分析和操作 EAD/XML 元数据,使其更擅长支持档案专业人员和需要精确模式合规性的应用程序。
数据集详情
数据格式
数据集中的每个条目都是一个 JSON 对象,包含以下字段:
tag:目标的 XML 标签或子标签(例如,<ead>,<repository>)。strategy:用于生成提示-完成对的策略。策略包括:Open-Ended PromptsTemplate-Based PromptsPartial XML PromptsInstruction with Schema Emphasis
prompt:用于指导模型的输入提示。completion:符合 EAD/XML 模式的预期完成输出。
示例条目:
json { "tag": "<ead>", "strategy": "Open-Ended Prompts", "prompt": "Generate a complete EAD record for an archival collection.", "completion": "<ead id="b1933186"><eadheader countryencoding="iso3166-1" dateencoding="iso8601" langencoding="iso639-2b" relatedencoding="dc" repositoryencoding="iso15511" scriptencoding="iso15924">...</eadheader><archdesc level="fonds">...</archdesc></ead>" }
数据生成过程
-
系统提示:使用专门的系统提示来指导生成模型。系统提示强调:
- XML 标签的全面覆盖。
- 模式合规性。
- 通过多种策略实现指令-完成对的多样性。
-
真实数据:解析并规范化符合模式的 EAD/XML 文件,以确保有效性和一致性。
-
合成数据:使用生成模型为真实数据中的每个 XML 标签创建合成提示-完成对。策略包括开放式生成、模板创建、部分片段的完成和模式聚焦的指令。
-
验证:生成的数据经过验证,确保符合 EAD/XML 标准。错误和不一致性被记录以供审查。
数据量
数据集包含约 16,000 个提示-完成对,每个 XML 标签通过多种策略生成多个示例,以确保模型训练的鲁棒性。
数据集统计
- 文件来源:来自法国
Inventaires du Catalogue général des manuscrits (CGM)(BnF)的 EAD/XML 文件:https://api.bnf.fr/fr/CCFr/CGM。 - 总样本数:数据集包含 175,410 个示例,涵盖四个提示-完成类别。
数据生成笔记本
该数据集已使用此 Kaggle Notebook 生成。
使用场景
该数据集可用于微调 LLMs 以执行以下任务:
- 档案元数据生成:创建符合模式的 EAD/XML 记录。
- 元数据完成:填充不完整 XML 片段中缺失的属性或子元素。
- 模板创建:生成 EAD/XML 标签的模板。
- 模式验证:训练模型以验证 XML 文件是否符合 EAD 模式。
结构
数据集以 JSONL(JSON Lines)格式提供,其中每行代表一个单独的提示-完成对。
示例 JSONL 文件
json { {"tag": "<ead>", "strategy": "Open-Ended Prompts", "prompt": "Generate a complete EAD record for an archival collection.", "completion": "<ead id="b1933186"><eadheader ...</eadheader><archdesc level="fonds">...</archdesc></ead>"} {"tag": "<repository>", "strategy": "Template-Based Prompts", "prompt": "Generate a template for the <repository> tag with placeholder attributes.", "completion": "<repository code="[PLACEHOLDER]">[PLACEHOLDER]</repository>"} }
可用数据集
另一个更轻量且更平衡的版本的数据集可用:
- Ead-Instruct-12k:包含 12,000 条记录的子集。
引用
如果您在研究或应用程序中使用此数据集,请按如下方式引用:
@dataset{ead_instruct_16k, author = {Geraldine}, title = {EAD-Instruct-16k}, year = {2024}, publisher = {Hugging Face}, url = {https://huggingface.co/datasets/Geraldine/Ead-Instruct-16k} }
致谢
该数据集使用来自 Inventaires du Catalogue général des manuscrits (CGM)(BnF)收藏的 EAD/XML 文件创建。
许可证
该数据集在 MIT 许可证下发布。有关详细信息,请参阅 LICENSE 文件。
联系方式
如有问题、反馈或数据集问题,请联系:
- 姓名:Géraldine Geoffroy
- 电子邮件:grldn.geoffroy@gmail.com
- GitHub:https://github.com/gegedenice