raw-food-recognition
收藏资源简介:
该数据集是三个公开可用的食物识别数据集的综合汇编,经过合并和整理,用于生鲜食品识别任务。数据集包含各种生鲜食品的图像,包括水果、蔬菜、乳制品和饮料,旨在用于教育目的和图像识别模型的开发。数据集包含90多个食品类别,约15,000张图像,按照80/20的比例分为训练集和验证集。图像格式为JPEG/PNG,分辨率可变(通常为224x224或更高)。数据集通过合并三个来源的数据集(Food and Vegetables Dataset、Fruit and Vegetable Image Recognition Dataset和Grocery Store Dataset)创建,并经过数据收集、标签标准化、去重、类别整合和分层分割等处理步骤。
This dataset is a comprehensive compilation of three publicly available food recognition datasets, merged and curated for fresh produce recognition tasks. It contains images of various fresh foods including fruits, vegetables, dairy products and beverages, and is intended for educational purposes and the development of image recognition models. The dataset includes more than 90 food categories, approximately 15,000 images, and is split into training and validation sets with an 80/20 ratio. The images are in JPEG/PNG formats, with variable resolutions (typically 224x224 or higher). The dataset is created by merging three source datasets: Food and Vegetables Dataset, Fruit and Vegetable Image Recognition Dataset and Grocery Store Dataset, and has undergone processing steps including data collection, label standardization, deduplication, category consolidation and stratified splitting.
Merged Raw Food Recognition Dataset 概述
数据集描述
本数据集是三个公开可用的食物识别数据集的综合汇编,经过合并和整理,用于生鲜食物识别任务。数据集包含各种生鲜食物项目的图像,包括水果、蔬菜、乳制品和饮料,旨在用于教育目的和图像识别模型的开发。
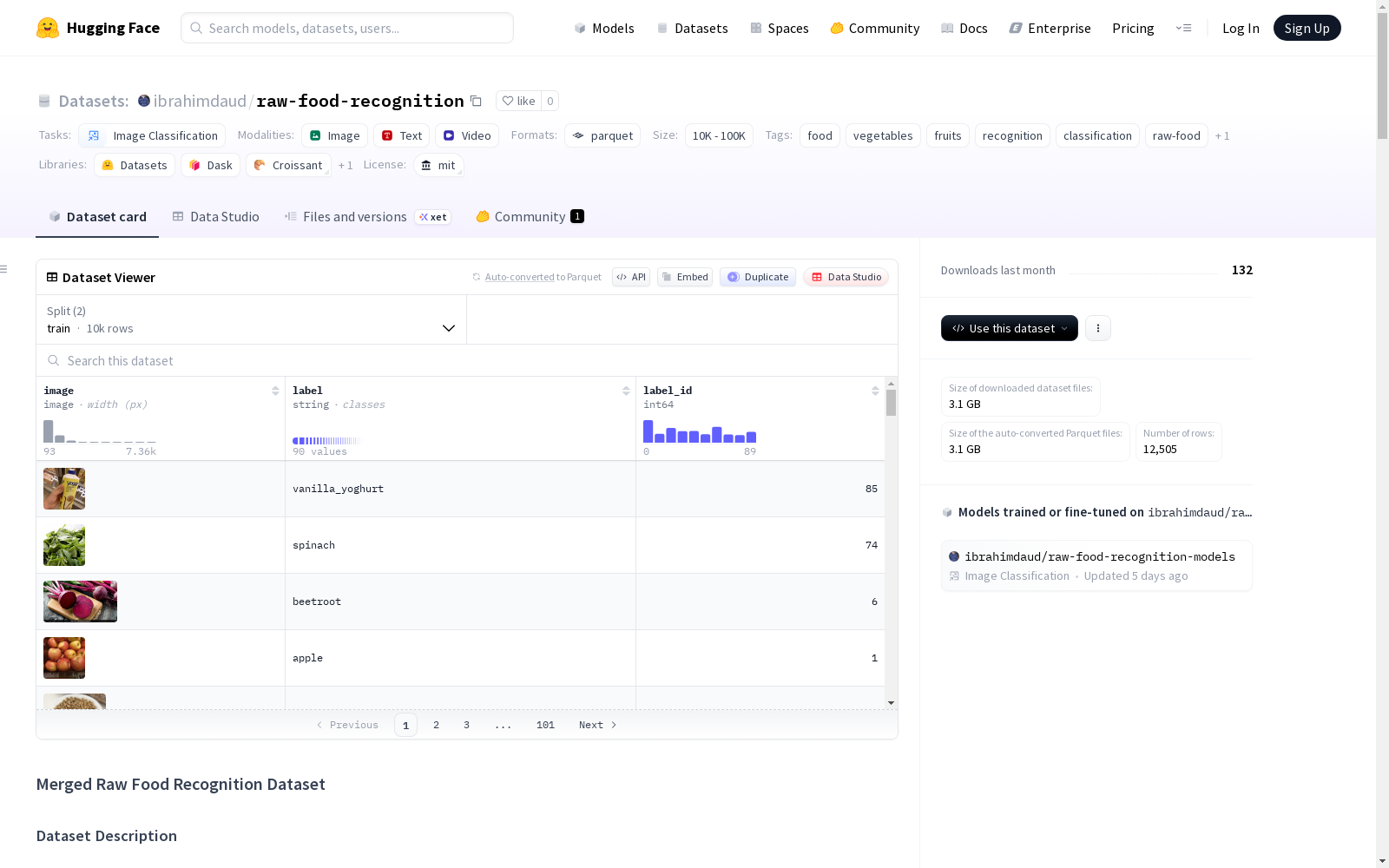
数据集统计
- 总类别数:90+ 种食物类别
- 总图像数:约 15,000+ 张图像
- 训练/验证集划分:80/20 比例
- 图像格式:JPEG/PNG
- 图像分辨率:可变(通常为 224x224 或更高)
数据集结构
数据集按训练和验证划分进行组织:
- 训练集:80% 的数据(约 12,000 张图像)
- 验证集:20% 的数据(约 3,000 张图像)
每个样本包含:
image:食物项目的 PIL 图像对象label:表示食物类别的字符串标签(例如 "apple"、"banana"、"carrot")label_id:与标签对应的整数 ID(0 到 num_classes-1)
源数据集
此合并数据集结合了以下三个来源的图像:
- Food and Vegetables Dataset
- 来源:https://huggingface.co/datasets/SunnyAgarwal4274/Food_and_Vegetables
- 描述:用于分类任务的食物和蔬菜图像集合
- Fruit and Vegetable Image Recognition Dataset
- 来源:https://huggingface.co/datasets/Nattakarn/fruit-and-vegetable-image-recognition
- 描述:专注于水果和蔬菜识别的数据集
- Grocery Store Dataset
- 来源:https://www.kaggle.com/datasets/validmodel/grocery-store-dataset/data
- 描述:包含各种食品项目的综合杂货店产品数据集
合并过程
数据集采用以下方法合并:
- 数据收集
- 标签标准化
- 去重
- 类别整合
- 分层划分
- 格式转换
食物类别
数据集包含以下类别(示例):
- 水果:苹果、香蕉、橙子、草莓、葡萄、芒果、猕猴桃、西瓜等
- 蔬菜:胡萝卜、番茄、土豆、洋葱、西兰花、花椰菜、菠菜等
- 乳制品:牛奶、酸奶(各种口味)、酸奶油等
- 饮料:苹果汁、橙汁、葡萄柚汁、豆奶、燕麦奶等
- 特色物品:各种葫芦(葫芦、苦瓜、棱角丝瓜)、异国水果(火龙果、百香果)等
使用方式
数据集可通过 Hugging Face datasets 库加载,并提供了与 PyTorch 和 TensorFlow/Keras 框架结合使用的示例代码。
数据集特征
- 多样性:来自多个来源的图像确保了光照、背景和图像质量的多样性
- 类别平衡:分层划分保持了训练/验证集中的类别分布
- 真实世界可变性:包含食物外观、成熟度和呈现方式的自然变化
- 教育重点:专门为学习和研究目的而策划
- Parquet 格式:数据以 Parquet 格式存储,以实现高效存储和快速加载
限制与注意事项
- 类别不平衡:某些食物类别的样本可能多于其他类别
- 图像质量:图像来自不同来源,质量和分辨率各异
- 标签变体:某些食品项目保留了多个标签变体(例如 "yogurt" 与 "yoghurt")以维持数据集多样性
- 教育目的:本数据集仅用于教育用途
许可
本数据集仅用于教育目的。请参考原始源数据集以了解其各自的许可和使用条款。
更新
- 2024年:初始版本,包含 90+ 种食物类别,并以 Parquet 格式提供 80/20 的训练/验证集划分