en-document-classification
收藏Hugging Face2026-05-09 更新2026-05-10 收录
下载链接:
https://huggingface.co/datasets/agentlans/en-document-classification
下载链接
链接失效反馈官方服务:
资源简介:
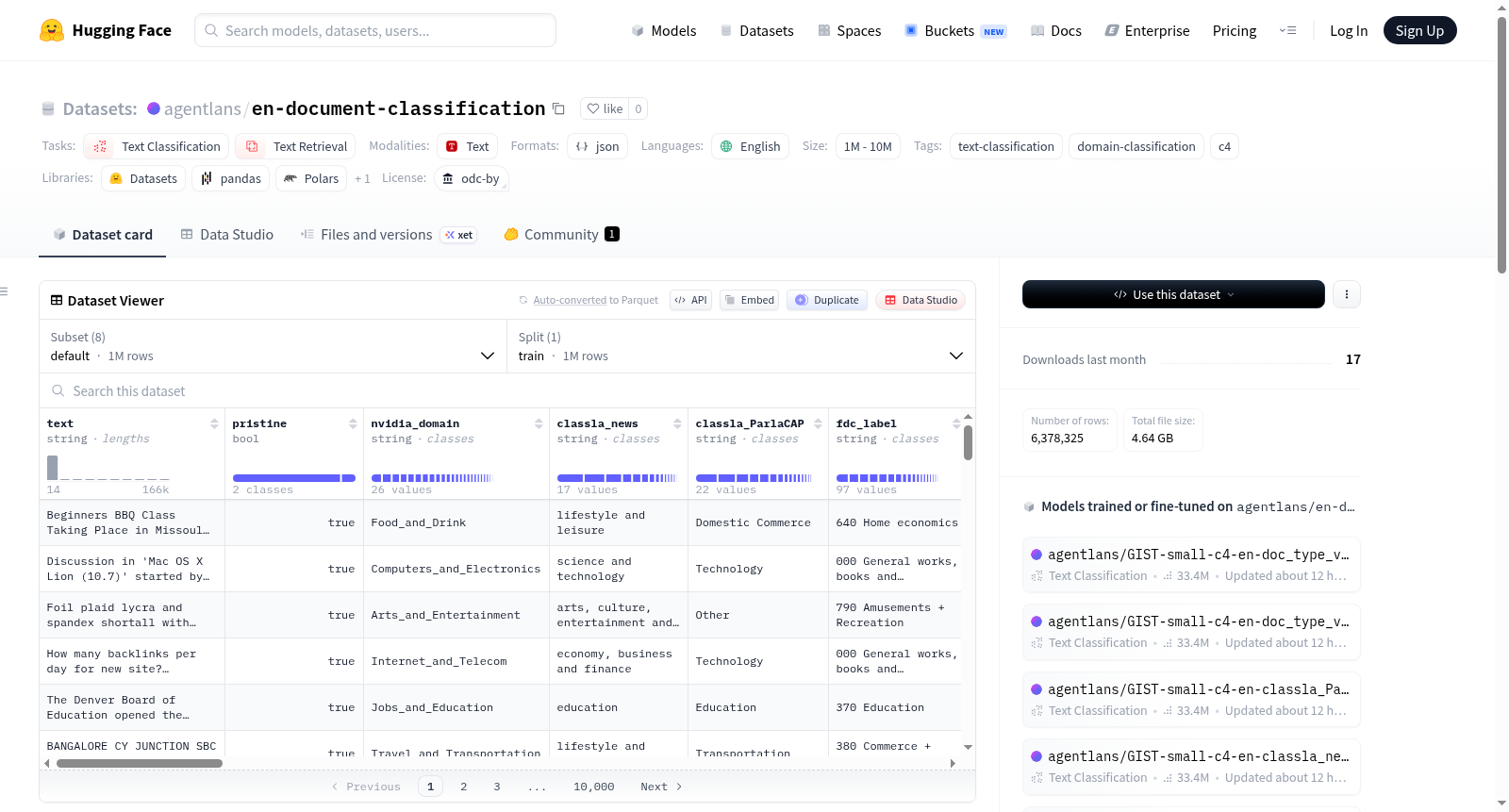
该数据集是从allenai/c4(英文配置)中精选的前100万行数据,并增加了多视角主题注释。它专为研究文档分类、领域适应和大规模网络爬取语料库中的标签噪声的研究人员设计。数据集整合了五个不同分类模型的预测结果,以提供对每个文档内容的全面视角。为确保实用性,数据根据这些变量进行了分层,并按照80/10/10%的比例划分为训练集、验证集和测试集,并根据源分类器组织为特定配置。数据集包含以下分类器的注释列:nvidia/domain-classifier(通用网络领域分类)、classla/multilingual-IPTC-news-topic-classifier(标准化新闻行业主题代码)、classla/ParlaCAP-Topic-Classifier(立法和议会主题类别)、cardiffnlp/tweet-topic-latest-multi(社交媒体风格主题分类)和EssentialAI/eai-distill-0.5b(基于FDC数据和内容分析的分类映射)。数据集还包含一个pristine列,用于指示文档是否结构完整。需要注意的是,数据集存在类别不平衡、银标准标签和标签模糊等局限性。数据集采用Open Data Commons Attribution License (ODC-BY)许可发布。
This dataset is a curated collection of the first 1 million rows from the allenai/c4 (English configuration) corpus, augmented with multi-perspective topic annotations. It is specifically developed for researchers investigating document classification, domain adaptation, and label noise within large-scale web-crawled corpora. The dataset aggregates prediction outputs from five distinct classification models to provide comprehensive multi-perspective insights into the content of each document. To enhance practical utility, the data is stratified according to these annotation variables, split into training, validation, and test sets with an 80/10/10 distribution, and organized into specific configurations based on their source classifiers. The dataset contains annotation columns derived from the following classification models: nvidia/domain-classifier (general web domain classification), classla/multilingual-IPTC-news-topic-classifier (standardized news industry topic codes), classla/ParlaCAP-Topic-Classifier (legislative and parliamentary topic categories), cardiffnlp/tweet-topic-latest-multi (social media-style topic classification), and EssentialAI/eai-distill-0.5b (classification mapping based on FDC data and content analysis). The dataset also includes a `pristine` column that indicates whether a document has a complete, well-formed structure. It is important to note that this dataset carries limitations including class imbalance, silver-standard labels, and label ambiguity. The dataset is released under the Open Data Commons Attribution License (ODC-BY).
创建时间:
2026-05-08
原始信息汇总
数据集概述
en-document-classification 是一个英文文档分类数据集,源自 allenai/c4 数据集的英文子集,精选了前 100万行 数据,并补充了多视角的主题标注。该数据集旨在支持文档分类、领域自适应以及大规模网络爬取语料中的标签噪声研究。
核心特征
- 语言:英文
- 许可证:ODC-BY(Open Data Commons Attribution License)
- 任务类别:文本分类、文本检索
- 标签:文本分类、领域分类、C4
数据划分与配置
数据集按照 80/10/10% 的比例划分为训练集、验证集和测试集,并根据来源分类器组织为多个配置(config)。每个配置文件均包含对应的数据文件(JSONL 格式,使用 ZST 压缩)。
| 配置名称 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| default | all.jsonl.zst | - | - |
| pristine | pristine/train.jsonl.zst | pristine/validation.jsonl.zst | pristine/test.jsonl.zst |
| classla_news | classla_news/train.jsonl.zst | classla_news/validation.jsonl.zst | classla_news/test.jsonl.zst |
| classla_ParlaCAP | classla_ParlaCAP/train.jsonl.zst | classla_ParlaCAP/validation.jsonl.zst | classla_ParlaCAP/test.jsonl.zst |
| doc_type_v1_primary | doc_type_v1_primary/train.jsonl.zst | doc_type_v1_primary/validation.jsonl.zst | doc_type_v1_primary/test.jsonl.zst |
| doc_type_v2_primary | doc_type_v2_primary/train.jsonl.zst | doc_type_v2_primary/validation.jsonl.zst | doc_type_v2_primary/test.jsonl.zst |
| fdc_label | fdc_label/train.jsonl.zst | fdc_label/validation.jsonl.zst | fdc_label/test.jsonl.zst |
| nvidia_domain | nvidia_domain/train.jsonl.zst | nvidia_domain/validation.jsonl.zst | nvidia_domain/test.jsonl.zst |
标注信息
数据集整合了来自五个不同分类模型的预测结果,为每个文档提供多角度的主题标注。各模型及对应的标注列如下:
| 分类器 | 标注列名称 | 描述 |
|---|---|---|
| nvidia/domain-classifier | nvidia_domain | 通用网络领域分类 |
| classla/multilingual-IPTC-news-topic-classifier | classla_news | 标准化新闻行业主题代码 |
| classla/ParlaCAP-Topic-Classifier | classla_ParlaCAP | 立法与议会主题分类 |
| cardiffnlp/tweet-topic-latest-multi | cardiffnlp_tweet | 社交媒体风格主题分类 |
| EssentialAI/eai-distill-0.5b | fdc_label 及其他列 | 基于FDC数据的类别映射与内容分析 |
FDC(自由十进制对应)映射说明:标签源自 EssentialAI/eai-distill-0.5b 模型的预测,分类号被截断至最接近的10的倍数,并映射至官方FDC类别。
质量指标
- pristine 列:一个布尔标志,基于EAI分类器生成的数据,用于指示文档结构是否完整或可能缺失内容/上下文。
- 配置划分:数据集按配置分区(例如 classla_ParlaCAP),允许用户加载基于特定模型输出分层后的数据。
局限性与偏差
- 类别不平衡:各类别之间存在显著的分布偏移,反映了C4语料库中主题的自然频率。
- 银标准标签:所有标签均由模型生成(银标准),源分类器中的错误或偏差会反映在该数据集中。
- 标签歧义:网络文档常涉及多个领域(例如,一个个人博客可能同时讨论地缘政治和烹饪),单标签分配可能过度简化这些文档。
搜集汇总
数据集介绍
构建方式
本数据集源自大规模网络爬取语料库allenai/c4的英文子集,精心遴选出前一百万行数据,并在此基础上整合了五种不同主题分类模型的预测结果,以提供多维度的注释信息。为确保数据的代表性与均衡性,研究人员依据这些分类变量对数据进行分层抽样,并按照80/10/10的比例划分为训练集、验证集与测试集。最终,数据集依据源分类器的不同,组织成多个独立配置,例如classla_news与nvidia_domain,便于用户按需加载。
使用方法
研究者可通过HuggingFace Datasets库轻松加载该数据集,根据所需主题注释选择相应配置,如加载classla_ParlaCAP配置以研究议会相关主题。数据集提供标准的训练、验证与测试划分,支持文本分类与检索任务。在应用时,用户应关注类别分布不均与银标准标签的潜在偏差,并可结合pristine标志筛选高质量样本,以提升模型训练的可靠性。
背景与挑战
背景概述
随着互联网上海量文本数据的爆炸式增长,如何高效地对文档进行自动分类与主题标注成为自然语言处理领域的重要研究课题。en-document-classification数据集由研究团队于近期构建,基于Common Crawl语料库的C4子集(英文配置),精选前100万行数据,并融合了五种不同分类模型的预测结果,为文档分类、领域自适应以及标签噪声分析提供了多视角的标注资源。该数据集以开源许可ODC-BY发布,推动了跨领域文档理解研究的发展,为大规模网络爬取文本的细粒度分类提供了标准化基准。
当前挑战
该数据集面临多维度挑战。在领域问题层面,文档分类需处理类别不平衡问题——C4语料库中主题分布的自然差异导致某些类别样本稀少,影响模型泛化能力;同时,网络文档常涉及多领域交叉(如兼顾地缘政治与烹饪的个人博客),单标签分配难以准确描述其复杂语义。在构建过程中,所有标签均为模型生成的银标准,源头分类器的误差与偏见会被直接继承;此外,来自不同分类器的多视角标注之间存在分歧,如何协调异构标签以构建一致且鲁棒的分类体系仍是核心挑战。
常用场景
经典使用场景
在自然语言处理领域,文档分类是一项基础而关键的任务,其核心在于将非结构化的文本数据精准映射至预定义的类别体系中。en-document-classification数据集作为从大规模网络爬取语料C4中精心筛选的百万级子集,为文档分类研究提供了极具代表性的基准资源。该数据集整合了来自五个不同分类模型的预测结果,涵盖了通用网页领域分类、新闻行业主题编码、立法议会主题分类等多元视角,使其特别适用于多标签分类、主题建模及跨领域迁移学习等经典场景。研究者可借助其丰富的标注信息,在统一的实验框架下验证不同分类架构的性能,并深入探究文本表征的泛化能力。
解决学术问题
在学术研究中,海量网络文本的分类常面临标注噪声大、类别分布不均以及标签纯度不足等严峻挑战。en-document-classification数据集通过引入多模型协同的银标准标注策略,有效缓解了单一分类器带来的系统性偏差,为研究标注质量评估与噪声标签鲁棒学习提供了理想的数据基础。其分层的配置设计(如pristine质量标志)使得科研人员能够系统分析文档结构完整性对分类效果的影响。此外,该数据集揭示了网络语料中广泛存在的类别重叠问题,推动了针对单标签分配简化性的批判性思考,进而催生了多标签分类与模糊语义处理方向的深度探索,对提升文本分类方法论的科学性具有重要学术价值。
实际应用
在工业界与互联网服务中,文档分类技术是海量信息治理与智能内容管理的核心支柱。en-document-classification数据集因其源自真实网络爬取语料C4,且覆盖多种文档类型与来源,可被直接用于构建内容过滤系统、个性化信息推荐引擎以及自动化知识图谱构建管道。例如,基于nvidia_domain标注的通用领域分类结果,可开发高效的网页主题筛选工具;借助classla_news的新闻主题编码,能够实现新闻聚合平台的自动归类。该数据集的多视角标注结构同时支持跨模态内容理解,为搜索引擎优化、社交媒体舆情监控以及数字图书馆的智能分类等实际任务提供了可复用的训练资源与评测基准。
数据集最近研究
最新研究方向
该数据集聚焦于大规模网页语料库中文档分类的前沿探索,尤其关注多视角主题标注与标签噪声的应对策略。通过整合来自不同领域(如新闻、议会内容、社交媒体)的五种分类器预测结果,它推动了跨领域迁移学习与多标签分类研究。其基于C4数据集的精选子集与银标准标注策略,为研究数据质量对模型性能的影响提供了宝贵资源。当前,该数据集在工业级文本理解、领域自适应、以及法律与新闻文本的自动化分类中具有关键意义,助力更鲁棒的文档解析与信息检索系统开发。
以上内容由遇见数据集搜集并总结生成


