anas775/DETECT-AI-Dataset
收藏Hugging Face2026-05-02 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/anas775/DETECT-AI-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
DETECT-AI多模态AI内容检测数据集是一个大规模、多语言的数据集,包含文本、图像、视频和音频四种模态的数据。该数据集每月从19个全球来源收集超过10亿个经过验证的样本,并使用8个专门的AI检测模型进行加权标注。数据集支持包括英语、中文在内的多种语言,规模在10亿到100亿之间。数据集包含AI生成内容、人类内容和不确定内容的标签,主要用于AI内容检测任务。数据集来源广泛,包括BBC、Reuters、Al Jazeera等多个全球来源。数据集采用Pipeline架构进行数据处理,遵循CC-BY-4.0许可协议,可用于研究和商业用途。
The DETECT-AI Multi-Modal AI Content Detection Dataset is a large-scale, multi-language dataset containing four modalities of data: text, image, video, and audio. The dataset collects over 1 billion verified samples per month from 19 global sources and labels them using a weighted ensemble of 8 specialized AI-detection models. The dataset supports multiple languages including English and Chinese, with a size between 1 billion and 10 billion. It includes labels for AI-generated content, human content, and uncertain content, primarily used for AI content detection tasks. The dataset sources are extensive, including BBC, Reuters, Al Jazeera, and other global sources. The dataset employs a Pipeline architecture for data processing and follows the CC-BY-4.0 license, allowing for both research and commercial use.
提供机构:
anas775
搜集汇总
数据集介绍
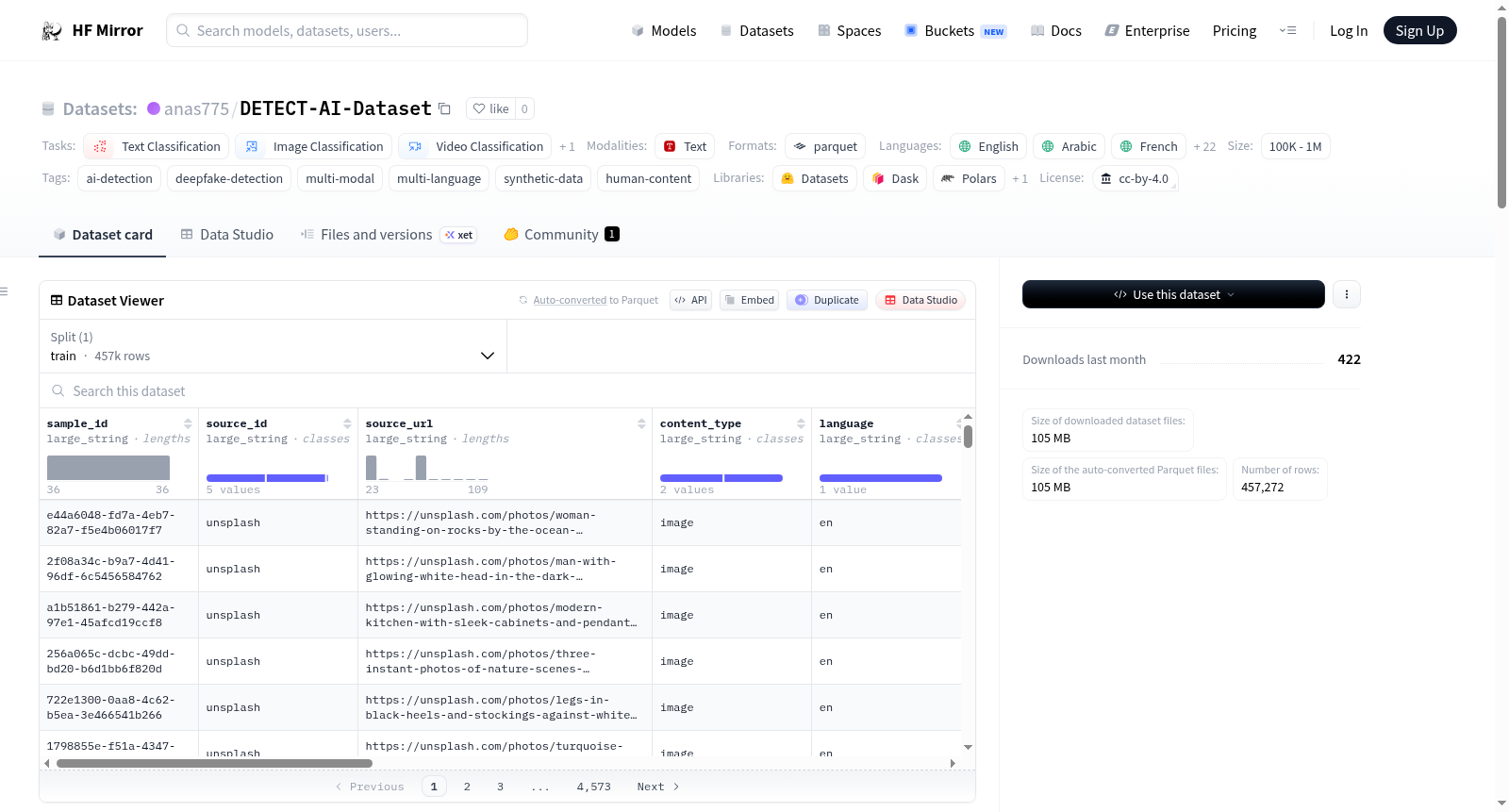
构建方式
在人工智能生成内容日益普及的背景下,DETECT-AI数据集通过一套高度自动化的流水线架构构建而成。该架构依托Cloudflare Workers每五分钟从19个全球来源(如BBC、arXiv、Unsplash、YouTube等)实时抓取文本、图像、视频和音频内容,随后利用GitHub Actions驱动的加权集成模型系统进行标注。标注过程融合了八种专业AI检测模型,依据不同模态分配权重,最终生成包含AI生成、人类创作及不确定类别的多语言样本,并以Parquet格式分片存储,确保数据的高效处理与可扩展性。
特点
DETECT-AI数据集的核心特征在于其多模态与多语言的广泛覆盖。数据集每月收录超过十亿条经过验证的样本,涵盖文本、图像、视频和音频四种内容形式,并支持包括英语、中文、阿拉伯语等二十余种语言。其标注体系基于集成模型的置信度阈值,将样本精确划分为AI生成、人类创作及不确定三类,同时提供详细的元数据如模型分数、来源信息和时间戳。这种结构不仅增强了数据集的多样性与代表性,也为跨模态AI检测研究提供了丰富的实验基础。
使用方法
为有效利用DETECT-AI数据集,研究者可依据文件夹结构按需访问不同模态与语言的分片数据。文本数据以Parquet文件存储于对应语言目录,图像与视频则包含元数据及提取的帧、人脸与纹理掩码。使用时应参考schema_v1.json中的字段定义,结合final_confidence与label字段进行模型训练或评估,并可利用model_scores进行深入分析。数据集遵循CC-BY-4.0许可,允许研究与商业应用,但需按要求进行署名引用。
背景与挑战
背景概述
随着生成式人工智能技术的飞速发展,多模态合成内容在文本、图像、音频和视频领域的泛滥,对数字内容的真实性与可信度构成了严峻挑战。DETECT-AI多模态人工智能内容检测数据集应运而生,由全球研究团队通过自动化流水线构建,旨在提供大规模、多语言、多模态的基准数据,以支持AI生成内容的检测与鉴别研究。该数据集每月从19个国际权威来源采集超过10亿条经过验证的样本,覆盖多种内容类型与语言,其核心研究问题聚焦于如何有效区分人工智能生成内容与人类创作内容,对推动数字媒体取证、信息安全及伦理治理等领域具有深远影响力。
当前挑战
该数据集致力于解决多模态AI内容检测这一复杂领域问题,其核心挑战在于如何准确识别不同模态(如文本、图像、音频、视频)中高度逼真的合成内容,尤其是在生成模型不断演进、合成质量持续提升的背景下。在构建过程中,挑战同样显著:首先,需要从多样化的全球来源实时爬取与处理海量数据,并确保数据质量与代表性;其次,依赖集成多个专用检测模型进行自动化标注,但模型间的性能差异与置信度阈值设定可能引入标注噪声;此外,多语言支持与跨模态的数据对齐也增加了技术复杂性。
常用场景
经典使用场景
在人工智能生成内容日益普及的背景下,DETECT-AI数据集为多模态AI检测任务提供了关键支撑。该数据集通过整合文本、图像、视频和音频四种模态的数十亿条标注样本,成为训练和评估深度伪造检测模型的核心资源。研究者利用其跨语言、多源头的特性,能够构建鲁棒的分类器,以区分AI生成内容与人类原创内容,尤其在应对新兴生成模型如GPT、Stable Diffusion等带来的挑战时,数据集的高覆盖度和实时更新机制确保了模型的前沿性能。
解决学术问题
DETECT-AI数据集有效解决了多模态合成内容检测中的若干学术难题。它通过加权集成八个专用AI检测模型,提供了大规模、高置信度的标注数据,缓解了传统方法中标注噪声和样本偏差问题。该数据集支持跨模态联合学习研究,促进了模型在异构数据上的泛化能力,同时其多语言覆盖有助于探索文化语境对检测性能的影响。这些贡献推动了可信人工智能领域的发展,为内容真实性验证提供了标准化基准。
衍生相关工作
基于DETECT-AI数据集,学术界衍生出多项经典研究工作。例如,跨模态注意力网络被提出以融合文本与视觉特征,提升混合内容检测精度;多语言检测框架利用数据集的19种语言样本,实现了低资源语言的合成内容识别。此外,研究人员开发了增量学习算法,以适应数据集持续更新的特性,确保模型对新兴生成技术的快速响应。这些工作不仅推动了检测技术的进步,也为数据集本身的迭代优化提供了反馈循环。
以上内容由遇见数据集搜集并总结生成


