OpenSeeSimE-Fluid-Small
收藏数据集概述
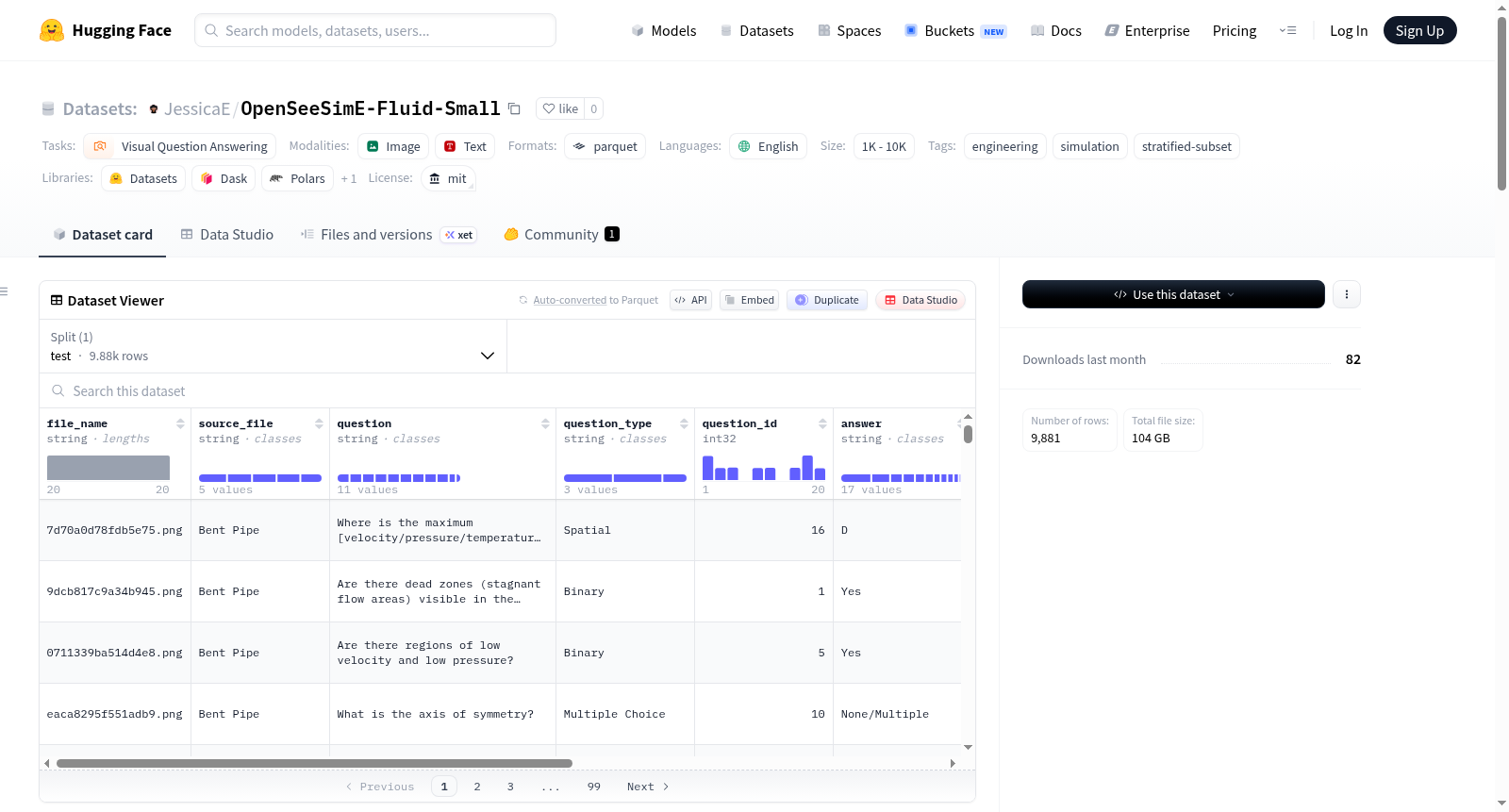
OpenSeeSimE-Fluid-Small 是 cmudrc/OpenSeeSimE-Fluid 的分层 10% 子集,专门用于在降低计算开销的同时评估视觉语言模型,同时保持模拟类型、问题类型、媒体类型和问题 ID 的联合分布。
子集来源
- 父数据集:
cmudrc/OpenSeeSimE-Fluid(共 98,326 行) - 本子集行数:9,881(占父数据集的 10.05%)
- 源模拟类:
Bent Pipe、Converging Nozzle、Heat Exchanger、Heat Sink、Mixing Pipe - Parquet 分片数:19 | 存储大小:约 103.68 GB
- 采样方式:使用
numpy.random.default_rng(42)对每个层进行随机打乱,然后取ceil(n * fraction)行,每个非空层至少贡献 1 行 - 分层键:
(source_file, question_type, media_type, question_id)— 四个字段联合分层 - 嵌套关系:1% 子集是 10% 子集的字面子集(每个分数的随机前缀相同)
数据组成
按 source_file 分布
| source_file | 行数 | 占比 (%) |
|---|---|---|
| Mixing Pipe | 2,070 | 20.95 |
| Heat Exchanger | 2,029 | 20.53 |
| Bent Pipe | 1,976 | 20.00 |
| Converging Nozzle | 1,971 | 19.95 |
| Heat Sink | 1,835 | 18.57 |
按 media_type 分布
| media_type | 行数 |
|---|---|
| image | 4,948 |
| video | 4,933 |
按 (source_file, question_type) 分布
| source_file | 二值 | 多项选择 | 空间 | 总计 |
|---|---|---|---|---|
| Bent Pipe | 792 | 796 | 388 | 1,976 |
| Converging Nozzle | 791 | 789 | 391 | 1,971 |
| Heat Exchanger | 812 | 811 | 406 | 2,029 |
| Heat Sink | 719 | 710 | 406 | 1,835 |
| Mixing Pipe | 828 | 828 | 414 | 2,070 |
特征模式
与父数据集相同,具体字段如下:
python { file_name: str, # 唯一标识符 source_file: str, # 基础模拟模型 question: str, # 问题文本 question_type: str, # Binary, Multiple Choice, Spatial question_id: int, # 问题标识符 (1-20) answer: str, # 真实答案 answer_choices: list[str], # 选项列表 correct_choice_idx: int, # 正确选项索引 image: Image, # PIL图像 (1920x1440),视频行为空 video: Video, # 视频字节,图像行为空 media_type: str, # image 或 video }
预期用途
- 在降低计算成本的前提下,对视觉语言模型在工程模拟问答任务上进行基准评估
- 在运行完整基准测试前,对评估流程进行烟雾测试
- 在存储或带宽受限时进行比较研究
许可
MIT — 与父数据集相同,可免费用于学术和商业用途,需注明出处。
引用
bibtex @article{ezemba2024opensesime, title={OpenSeeSimE: A Large-Scale Benchmark to Assess Vision-Language Model Question Answering Capabilities in Engineering Simulations}, author={Ezemba, Jessica and Pohl, Jason and Tucker, Conrad and McComb, Christopher}, year={2025} }
联系方式
Jessica Ezemba — jezemba@andrew.cmu.edu
卡内基梅隆大学机械工程系