MORABLES
收藏arXiv2025-09-16 更新2025-09-18 收录
下载链接:
https://huggingface.co/datasets/cardiffnlp/Morables
下载链接
链接失效反馈官方服务:
资源简介:
MORABLES是一个由西方文学传统中的寓言和短篇小说组成的人为验证基准,包含709个短故事和寓言及其相应的道德准则。每个条目都包含原始寓言的高质量转录或翻译,以及归属于原始作者或翻译者的道德准则。数据集的主要任务是结构化为多项选择题,针对道德推理,并附有精心设计的干扰项,挑战模型进行更深层次的推理。此外,为了进一步测试模型的鲁棒性,我们还引入了对抗性变种,旨在揭示LLM的漏洞和因数据污染等问题导致的快捷方式。研究表明,虽然更大的模型表现更好,但它们仍然容易受到对抗性操作的影响,并且经常依赖于表面模式而不是真正的道德推理。这种脆弱性导致显著的自我矛盾,最好的模型在道德选择的框架下约有20%的情况下会反驳自己的答案。有趣的是,推理增强模型未能弥补这一差距,这表明规模——而不是推理能力——是主要驱动力。
MORABLES is a human-validated benchmark composed of fables and short stories from the Western literary tradition, containing 709 short stories and fables along with their corresponding moral guidelines. Each entry includes a high-quality transcription or translation of the original fable, as well as moral guidelines attributed to the original author or translator. The core task of this dataset is structured as multiple-choice questions targeting moral reasoning, with carefully designed distractors to challenge models to conduct deeper reasoning. Furthermore, to further test the robustness of models, we have introduced adversarial variants designed to uncover vulnerabilities in LLMs and shortcuts caused by issues such as data contamination. Research has shown that while larger models perform better, they remain vulnerable to adversarial manipulations and often rely on surface-level patterns rather than genuine moral reasoning. This vulnerability leads to significant self-contradictions: even the best models will contradict their own answers in approximately 20% of cases when framed within moral choice scenarios. Interestingly, reasoning-enhanced models failed to bridge this gap, suggesting that model scale—not reasoning ability—is the primary driving factor.
提供机构:
威尼斯卡·福斯卡里大学环境科学、信息学和统计学系
创建时间:
2025-09-16
原始信息汇总
Morables 数据集概述
基本信息
- 许可证:CC BY-NC 4.0
- 任务类别:文本分类、问答
- 语言:英语
- 名称:Moral Fables
- 规模:小于1K
- 标签:艺术
数据集配置
- fables_only:包含Morables.json文件
- mcqa:包含mcqa_not_shuffled和mcqa_shuffled两个分割,分别对应MCQA/MCQAMorables.json和MCQA/MCQAMorables_Shuffled.json文件
- binary:包含binary_not_shuffled和binary_shuffled两个分割,分别对应Binary/BinaryMorables.json和Binary/BinaryMorables_Shuffled.json文件
- extracted_info:包含contradictions、tautologies、injected_adjectives、morals_from_adjectives、partial_story_moral、partial_story_moral_first、partial_story_moral_last七个分割
- supporting_info:包含characters_and_features、alternate_story_characters、generated_morals_gpt4o、generated_morals_claude35sonnet、generated_morals_llama33五个分割
- adversarial:包含pre_post_inj_not_shuffled、pre_post_inj_shuffled、adj_inj_not_shuffled、adj_inj_shuffled、adj_inj_char_swap_not_shuffled、adj_inj_char_swap_shuffled、char_swap_not_shuffled、char_swap_shuffled、post_inj_not_shuffled、post_inj_shuffled、pre_inj_not_shuffled、pre_inj_shuffled、pre_post_adj_not_shuffled、pre_post_adj_shuffled、pre_post_char_not_shuffled、pre_post_char_shuffled、pre_post_char_adj_not_shuffled、pre_post_char_adj_shuffled十八个分割
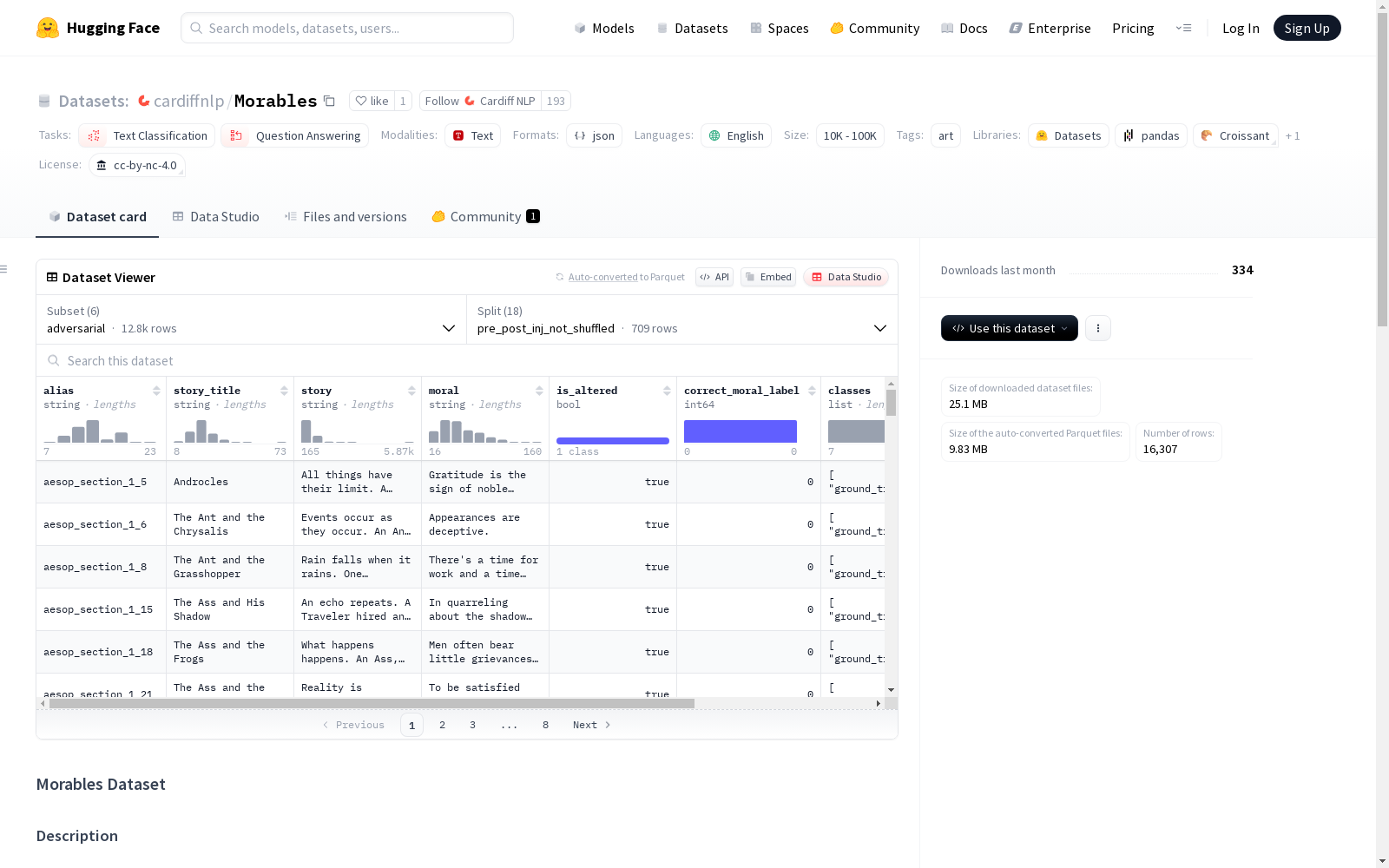
数据集内容
- 文件格式:JSON(字典列表)
- 记录数量:709
- 条目内容:
- alias:寓言唯一ID
- title:寓言标题
- story:寓言内容/短故事
- moral:故事寓意
- 文件列表:
- Morables.json:故事/寓言/寓意三元组
- MCQA/MCQAMorables.json/_Shuffled.json:MCQA基础基准(5选项),包含有序和无序选项版本
- extracted_info/*.json:为创建MCQA基准提取的支持信息
- MCQA/[modification_folder]/MCQAMorables.json/_Shuffled.json:对抗性MCQA变体,包含有序和无序选项版本
- Binary/BinaryMorables.json/_Shuffled.json:二元基准(寓意与对立面),包含有序和无序选项版本
使用方式
可通过🤗 Datasets加载数据集: python from datasets import load_dataset mcqa_dataset = load_dataset("cardiffnlp/Morables", "mcqa", split="mcqa_shuffled")
或直接下载源文件加载: python import json with open("<file_path>.json", encoding="utf-8") as file: data = json.load(file)
引用信息
如需在研究中使用本数据集,请引用主要参考论文:
@inproceedings{marcuzzo2025morables, title={Morables: A Benchmark for Assessing Abstract Moral Reasoning in LLMs with Fables}, author={Marcuzzo, Matteo and Zangari, Alessandro and Albarelli, Andrea and Camacho-Collados, Jose and Pilehvar, Mohammad Taher}, year={2025}, booktitle={Proceedings of EMNLP}, publisher={Association of Computational Linguistics}, }
搜集汇总
数据集介绍
构建方式
MORABLES数据集的构建依托于西方文学传统中的寓言与短篇故事,通过系统化的数据收集与处理流程实现。研究团队从多个开放源获取709对寓言与对应道德教训,涵盖伊索、拉封丹等经典作家的作品。构建过程包括严格的去重处理,利用词交集比和BERTScore等相似度指标确保数据唯一性,并通过人工验证保障质量。核心任务设计为多项选择题形式,每个问题包含一个正确答案和四个精心构造的干扰项,这些干扰项通过角色替换、特征注入等策略生成,以挑战模型的深层推理能力而非表面模式匹配。
特点
MORABLES数据集的核心特点在于其专注于抽象道德推理的评估,通过寓言这一富含叙事深度与道德复杂性的文学形式,为大型语言模型提供了高阶推理能力的测试平台。数据集包含多种变体,如对抗性版本(ADV)通过角色替换、特征注入和同义反复插入等修改,揭示模型对记忆和表面线索的依赖。此外,TF(真/假判断)和NOTO(无正确选项)变体进一步检验模型的一致性与抗干扰能力。数据集的道德教训均源自历史文献,确保了文化真实性与评估的生态效度,同时通过人工标注保障了选项的合理性与挑战性。
使用方法
MORABLES数据集的使用主要围绕多项选择题回答任务展开,模型需从五个选项中选择最符合寓言道德教训的答案。评估时采用标准提示策略,通常提供单示例(one-shot)以优化性能,选项顺序随机化以避免位置偏差。对于对抗性变体,模型需处理经过修改的叙事或选项,测试其鲁棒性。此外,数据集支持自由文本道德生成任务的评估,通过人工评分(1-5级Likert量表)和自动化指标(如BERTScore)衡量生成道德与原始教训的语义对齐程度。使用中需注意模型可能存在的记忆偏差,建议结合多种变体进行全面评估。
背景与挑战
背景概述
MORABLES基准数据集由威尼斯卡福斯卡里大学与卡迪夫大学联合团队于2025年创建,旨在评估大语言模型在抽象道德推理领域的深层理解能力。该数据集从西方文学传统中精选709则寓言与短篇故事,通过人类验证的多选题问答任务形式,聚焦于模型对叙事中隐含道德准则的推断能力。其创新性在于将古典文学与现代自然语言处理技术相结合,为道德推理研究提供了具有文化深度和语义复杂性的评估框架,对推动可解释人工智能与伦理对齐研究具有重要意义。
当前挑战
该数据集核心挑战在于解决道德推理任务中模型对表面模式依赖与真实推理能力缺失的问题,具体表现为模型易受对抗性样本干扰(如角色替换、特征注入和同义反复插入导致性能下降12.3%),以及20%的自相矛盾率。构建过程中的挑战包括:确保历史寓言与道德准则的精确匹配、设计具有语义迷惑性的干扰选项(如基于局部叙事生成的道德陷阱)、克服预训练数据污染导致的记忆偏差,以及通过多轮人工验证消除文化偏见与标注歧义。
常用场景
经典使用场景
在自然语言处理领域,MORABLES数据集被广泛应用于评估大型语言模型在抽象道德推理任务中的表现。该数据集通过精心构建的多选题形式,要求模型从寓言故事中推断出正确的道德寓意,从而检验其深层次语义理解和逻辑推理能力。研究者在模型评估过程中常采用该数据集的标准版本及其对抗变体,以全面分析模型在道德推理任务上的鲁棒性和泛化性能。
解决学术问题
MORABLES数据集有效解决了自然语言推理领域中模型依赖表面启发式而非深层理解的问题。通过提供具有丰富叙事结构和道德深度的寓言故事,该数据集能够揭示模型在抽象推理、语义理解和道德判断方面的真实能力。其对抗性变体进一步暴露了模型在数据污染、位置偏见和记忆依赖等方面的脆弱性,为提升模型推理能力提供了重要研究方向。
衍生相关工作
MORABLES数据集推动了多项相关研究工作的开展,特别是在道德推理评估范式的创新方面。基于该数据集设计的TF(真值判断)和NOTO(无正确选项)变体催生了新的评估方法论,相关研究还探索了模型在自由文本道德生成任务中的表现。这些衍生工作不仅扩展了道德推理评估的维度,还为理解模型推理机制与记忆效应的相互作用提供了新的视角。
以上内容由遇见数据集搜集并总结生成


