ai2-adapt-dev/tulu_v3.9_wildchat_100k
收藏Hugging Face2024-10-30 更新2024-12-14 收录
下载链接:
https://hf-mirror.com/datasets/ai2-adapt-dev/tulu_v3.9_wildchat_100k
下载链接
链接失效反馈官方服务:
资源简介:
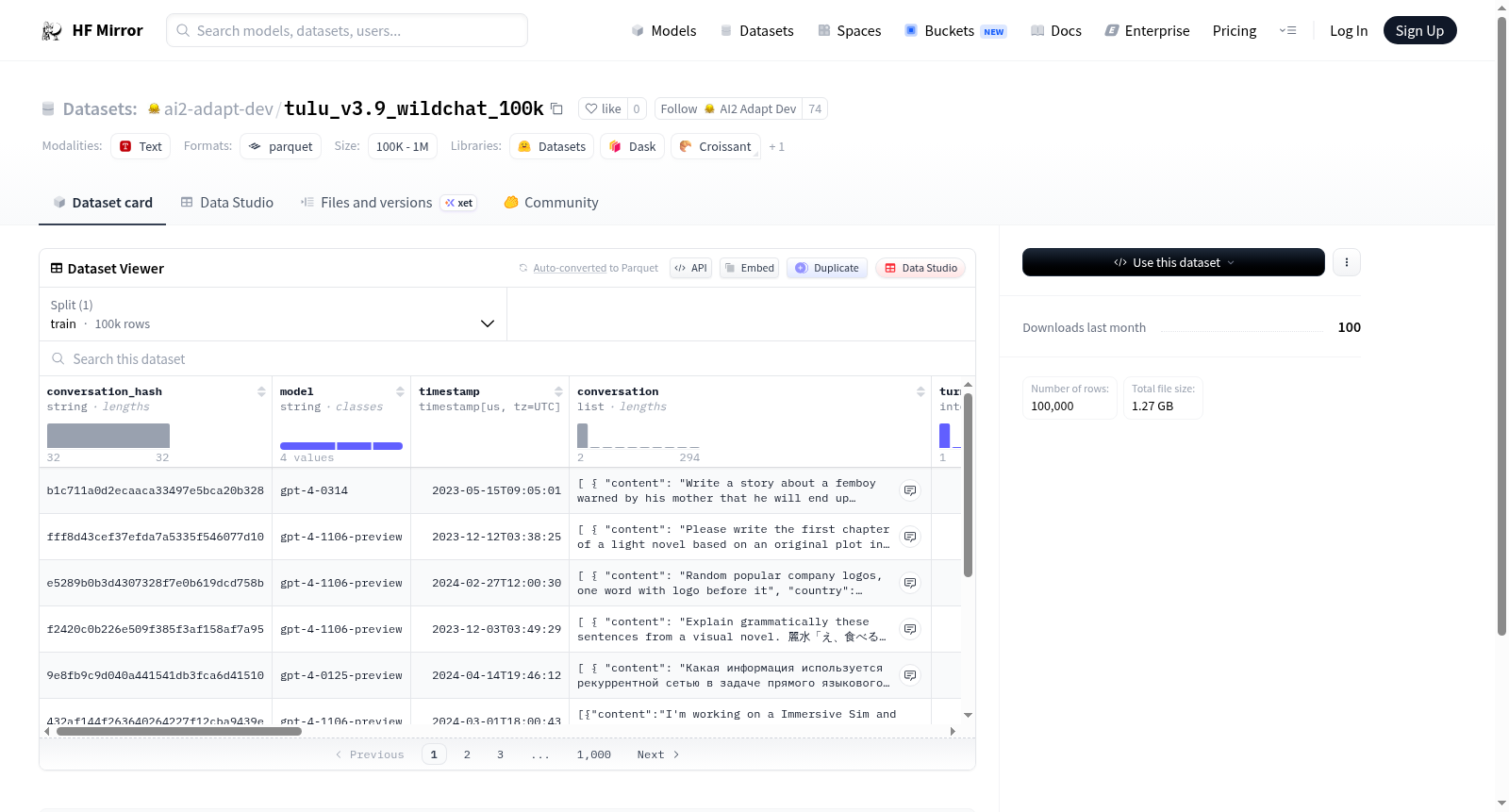
该数据集包含对话数据,每个对话包含多个特征,如对话哈希值、使用的模型、时间戳、对话内容、语言、国家、IP地址哈希、用户代理信息、消息内容、角色、状态、毒性标记、对话轮次等。此外,数据集还包括OpenAI和Detoxify的审核结果,用于标记对话中的不当内容。数据集包含100,000个训练样本,总大小约为2.41GB。
This dataset contains conversational data, with each conversation including multiple features such as conversation hash, model used, timestamp, conversation content, language, country, hashed IP address, user agent information, message content, role, state, toxicity markers, turn count, etc. Additionally, the dataset includes moderation results from OpenAI and Detoxify to flag inappropriate content in conversations. The dataset contains 100,000 training samples with a total size of approximately 2.41GB.
提供机构:
ai2-adapt-dev
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量对话数据的稀缺性一直是制约模型性能提升的瓶颈。ai2-adapt-dev/tulu_v3.9_wildchat_100k数据集正是为应对这一挑战而构建,其从WildChat平台采集了十万条真实用户与模型的多轮交互记录。每条对话均包含完整的消息序列、参与者角色、时间戳及地理元数据,并经过严格的去重与脱敏处理,通过哈希化用户IP和标记涉密内容来保障隐私合规。数据集的构建还融入了多层次的安全审核机制,借助OpenAI审核与Detoxify工具对每条消息的毒性、仇恨言论、色情内容等维度进行量化评分与标记,从而为模型的安全对齐研究提供精细化标注基础。
特点
该数据集最显著的特点在于其生态真实性,所有对话均源自无约束的自然交互场景,涵盖了从日常闲聊到技术讨论的广泛主题,并保留了多语言、多国家的地理分布特征。每条记录不仅包含原始对话内容,还附带了详尽的元数据,如用户代理信息、语言标签以及基于哈希的匿名标识符,便于进行对话行为分析。尤为突出的是,数据集内置了双重安全审核结果——OpenAI审核的18个类别标记与Detoxify的7项毒性指标,配合布尔型的毒性与涉密标签,使得研究者能够精准筛选出安全或敏感样本,为构建负责任的人工智能系统提供了坚实的数据基础。
使用方法
该数据集以HuggingFace Datasets库的标准格式发布,用户可通过简单的API调用直接加载训练集,无需额外的预处理工作。每条数据已按对话结构组织为messages字段,包含角色与内容的键值对,可直接用于监督式微调或指令微调流程。研究者可利用openai_moderation与detoxify_moderation字段中的分类分数和标记,依据研究需求构建自定义的过滤策略,例如排除高毒性样本或仅保留特定语言子集。此外,conversation字段保留了原始对话的完整结构化信息,包括每条消息的国家、语言、状态等属性,为多轮对话建模、跨文化语言分析以及对话安全评估等任务提供了即用型的数据接口。
背景与挑战
背景概述
随着大型语言模型在开放域对话系统中的广泛应用,如何获取高质量、多样化的真实用户交互数据成为了研究热点。在此背景下,由艾伦人工智能研究院(AI2)主导的Adapt团队于2024年构建了Tulu V3.9 WildChat 100K数据集,旨在捕捉无约束环境下用户与模型之间的自然对话流。该数据集从WildChat平台采集了10万条经过脱敏处理的对话记录,涵盖多语种、多轮交互及丰富的元数据(如地理位置、用户代理信息等),为研究对话安全性、用户行为模式及模型对齐提供了前所未有的真实场景资源。其发布显著推动了对话系统在鲁棒性评估与伦理约束方面的研究进程。
当前挑战
该数据集面临的核心挑战集中在三个方面。首先,在领域问题层面,真实对话中广泛存在的毒性内容、越狱攻击及隐私泄露风险,要求研究者开发更精细的审核机制与安全对齐策略。其次,构建过程中遭遇了多源异构数据的标准化难题,包括不同语言、文化背景下的表达差异,以及用户代理信息、时间戳等非结构化数据的清洗与整合。最后,数据集的时效性挑战尤为突出——随着模型迭代与用户行为演变,2024年采集的对话模式可能迅速过时,亟需建立持续更新机制以保持其作为基准测试的代表性。
常用场景
经典使用场景
在大型语言模型(LLM)对齐与安全研究的蓬勃浪潮中,ai2-adapt-dev/tulu_v3.9_wildchat_100k 数据集凭借其独特的野生产出对话(wild chat)架构,成为探究模型在无约束多轮交互中行为模式的理想载体。该数据集汇聚了十万条真实用户与模型的对话轨迹,每条样本均经过精细的毒性标记、OpenAI审核分类及Detoxify毒性评分等多维标注,为研究者提供了剖析模型在自然对话中涌现的偏见、攻击性及不当内容的宝贵窗口。经典的使用场景聚焦于对话安全评估与偏好对齐微调,例如利用其丰富的毒性标签与对话上下文,训练能够识别并规避有害输出的安全守卫模型,或作为监督信号构建更符合人类价值观的奖励模型,进而在RLHF(基于人类反馈的强化学习)框架下优化LLM的交互表现。
解决学术问题
该数据集精准回应了当前学术领域中关于大模型安全对齐与行为可控性的核心挑战。传统对齐数据集多依赖人工构造的假设性场景,难以捕捉真实部署环境下用户与模型间复杂、动态且往往出乎意料的交互风险。tulu_v3.9_wildchat_100k 通过收录来自WildChat平台的自然对话流,系统性地解决了两个关键学术问题:其一,如何量化并分类模型在无预设话题限制下的毒性输出分布,为建立多维度的安全评估基准提供实证基础;其二,如何利用真实世界的长尾对话数据(涵盖跨语言、跨文化及多种用户代理行为)来提升对齐方法的泛化能力。其意义在于弥合了实验室对齐与野外部署之间的鸿沟,使研究者得以从海量真实交互中提炼出模型失效的典型模式,推动了对齐理论从理想化设定向复杂现实场景的实质性跨越。
衍生相关工作
该数据集已催生出一系列具有深远影响的学术与工程衍生工作。在模型训练方面,基于其对话结构与毒性标注,研究者开发了如WildGuard等专门针对野外对话的安全指令微调方法,显著提升了模型在非受控环境下的有害内容拒绝能力。在评估基准领域,WildChat数据集的子集被整合进SafetyBench和Do-Not-Answer等综合性安全测试框架,成为衡量LLM对齐水平的标准测试床。此外,数据集中丰富的元数据(如国家、语言、用户代理)激发了跨文化对话分析与多语种毒性检测的研究方向,衍生出如PolyToxicity等针对语言多样性的安全模型。这些工作共同构成了一个从数据驱动到模型优化再到评估闭环的生态,持续推动着大模型安全对齐技术的迭代与深化。
以上内容由遇见数据集搜集并总结生成


