zaggr-data
收藏Hugging Face2026-04-20 更新2026-04-21 收录
下载链接:
https://huggingface.co/datasets/arsalan-anwari/zaggr-data
下载链接
链接失效反馈官方服务:
资源简介:
荷兰执法实体解析基准数据集是一个专为实体解析和记录链接研究设计的合成基准数据集,模拟了荷兰及欧盟/欧洲经济区执法数据的真实模式。所有数据均为100%合成,不包含任何真实个人、车辆或犯罪历史信息,确保无隐私或法律问题。数据集基于真实世界的数据模式(如荷兰商会注册、人口基础注册、SIS II规范等)生成,并结合荷兰中央统计局(CBS)的真实人口统计数据,注入了多种错误模式以模拟荷兰及跨申根身份数据的特定挑战。
数据集包含三个主要部分:
1. **KvK董事记录**:模拟荷兰商会注册数据,包含公司董事信息,重点处理荷兰名字前缀(如'van', 'de')的变体和地址漂移问题。
2. **SIS II通缉和失踪人员记录**:基于申根信息系统II(SIS II)的模式,处理跨申根别名对、名字顺序差异、罗马化变体和非拉丁脚本别名等挑战。
3. **ANPR车辆通行记录**:模拟荷兰高速公路自动车牌识别(ANPR)数据,主要解决OCR单字符混淆问题(如0与O、1与I等)。
数据集规模从约8,984到50,000条记录不等,每个子集均包含真实匹配对和错误模式标注。未来计划添加更多数据集,如人口注册、刑事记录等。数据文件为UTF-8编码的CSV格式,采用CC BY 4.0许可证发布。
创建时间:
2026-04-20
原始信息汇总
Dutch Law Enforcement Entity Resolution Benchmark 数据集概述
数据集基本信息
- 许可证: CC BY 4.0
- 支持语言: 荷兰语、英语、阿拉伯语、土耳其语
- 标签: 实体解析、记录链接、去重、执法、荷兰、荷兰人名、ANPR、SIS II、合成数据
- 数据集名称: Dutch Law Enforcement Entity Resolution Benchmark
- 规模: 100K < n < 1M
- 任务类别: 其他
数据集简介
这是一个用于实体解析和记录链接研究的合成基准数据集集合,基于真实的荷兰及欧盟/欧洲经济区执法数据模式建模。所有数据均为100%合成,不包含任何真实个人信息。
数据集构成
1. KvK Director Records
- 描述: 基于荷兰商会公司董事注册数据。同一人常注册多家公司,导致姓名变体、格式差异和地址漂移。
- 文件:
phase-01/kvk/kvk_director_flat.csvphase-01/kvk/ground_truth_pairs.csv
- 规模: 约10,000条记录,约3,600对真实匹配对。
- 关键字段:
kvkNummer、voornamen、tussenvoegsel、achternaam、geboortedatum、postcode等。 - 注入的错误模式: 中缀变体、缩写名、大小写和空格不一致、地址漂移。
2. SIS II Wanted and Missing Persons
- 描述: 基于申根信息系统II(SIS II)第26条(通缉人员)和第36条(失踪人员)模式的人员记录。核心挑战是跨申根地区的别名匹配。
- 文件:
phase-01/sis/sis_persons.csvphase-01/sis/ground_truth_alias_pairs.csv
- 规模: 约8,984条记录,约3,984对真实匹配对。
- 关键字段:
sis_id、categorie、voornamen、achternaam、alias_namen、geboortedatum、nationaliteit等。 - 注入的错误模式: 姓名顺序颠倒、罗马化变体、估计出生日期、非拉丁文字别名。
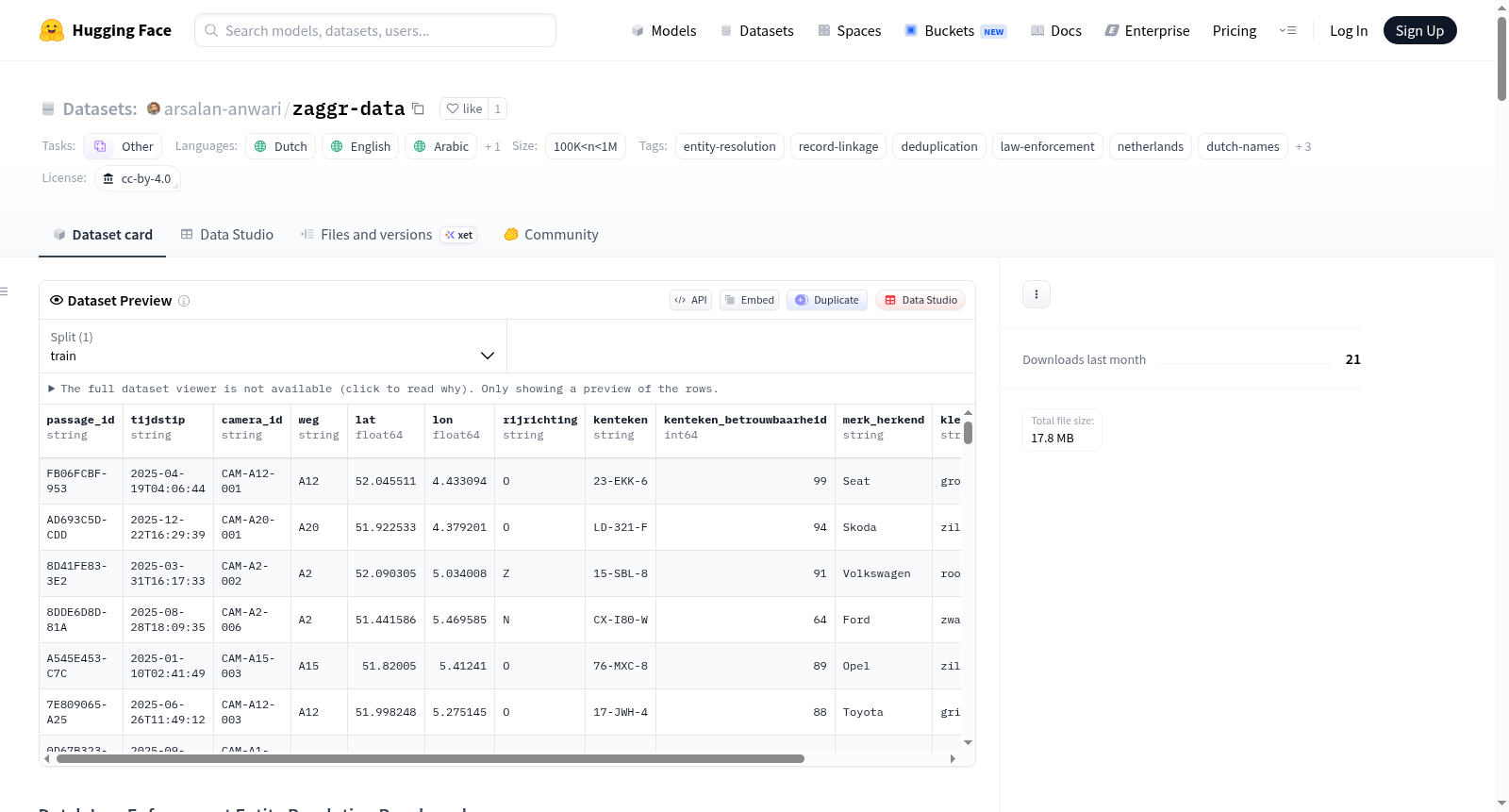
3. ANPR Vehicle Passages
- 描述: 基于荷兰自动车牌识别摄像头数据的高速公路通行事件。主要挑战是单字符OCR混淆。
- 文件:
phase-01/anpr/anpr_passages.csvphase-01/anpr/ground_truth_vehicle_pairs.csv
- 规模: 约50,000条记录,约2,490对真实匹配对。
- 关键字段:
passage_id、tijdstip、camera_id、kenteken、kenteken_betrouwbaarheid、snelheid_kmh等。 - 注入的OCR混淆对:
0<->O、1<->I、8<->B、5<->S、2<->Z。
数据生成特点
- 模式来源: 基于真实世界模式(如荷兰商会注册、人口登记、SIS II规范、荷兰ANPR数据流)。
- 人口统计分布: 使用荷兰中央统计局(CBS)的真实人口统计数据。
- 姓名分布构成:
- 荷兰语: ~55%
- 摩洛哥/阿拉伯语: ~20%
- 土耳其语: ~12%
- 其他: ~13%
文件格式
所有文件均为UTF-8编码的CSV格式,包含标题行。真实匹配文件均包含is_match列和match_type列。
许可证与引用
- 许可证: CC BY 4.0 (https://creativecommons.org/licenses/by/4.0/)
- 引用方式: Dutch Law Enforcement Entity Resolution Benchmark (synthetic), arsalan-anwari, 2025
搜集汇总
数据集介绍
构建方式
在执法数据实体解析研究领域,荷兰执法实体解析基准数据集采用了一种创新的合成生成方法。该数据集严格遵循荷兰及欧盟执法系统的真实数据模式,例如荷兰商会注册、人口基础登记以及申根信息系统规范。生成过程融合了荷兰中央统计局提供的真实人口统计分布,并系统性地植入了多种典型错误模式,包括姓名变体、光学字符识别混淆、罗马化差异以及估计出生日期,从而精确模拟了跨申根身份数据匹配中的实际挑战。
特点
本数据集的核心特征在于其高度仿真的复杂性与多样性。它专门针对荷兰语境下的独特挑战进行了设计,涵盖了荷兰姓名中缀的复杂变体、多元文化背景下的姓名拼写差异、跨成员国记录中的姓名顺序转换,以及自动车牌识别系统中典型的字符混淆模式。数据构成反映了荷兰当前的人口统计特征,并包含了非拉丁文字别名,为实体解析算法在处理真实世界、多源异构的执法数据时提供了全面而严谨的测试基准。
使用方法
研究人员可利用该数据集进行实体解析与记录链接算法的开发与评估。数据集以CSV格式提供,包含结构化的记录文件及明确标注了匹配关系与错误类型的真实对应文件。使用者可分别加载商会董事记录、申根系统人员记录或自动车牌识别通行记录,通过对比算法输出与基准真实值,系统评估算法在处理姓名变体、跨脚本别名及光学字符识别错误等方面的性能,从而推动该领域方法学的进步。
背景与挑战
背景概述
在实体解析与记录链接研究领域,现有基准数据集如DBLP-ACM、Febrl和Cora往往难以反映特定语言文化背景下的数据复杂性。为此,荷兰执法实体解析基准数据集应运而生,由研究人员arsalan-anwari于2025年创建,并基于荷兰与欧盟/欧洲经济区执法数据模式构建。该数据集旨在解决荷兰及申根区身份数据中特有的挑战,如荷兰姓名中的介词变体、多文化姓名拼写差异以及自动车牌识别系统中的光学字符识别错误。通过结合荷兰中央统计局的人口统计分布与真实世界数据模式,该数据集为执法、移民和跨域身份管理等领域的研究提供了高度仿真的合成数据基础,推动了实体解析技术在复杂多语言环境中的发展。
当前挑战
该数据集致力于应对实体解析领域中的核心挑战,即在多源异构数据中准确识别同一实体。具体而言,挑战体现在荷兰姓名复杂性上,如介词“van der”的省略或缩写变体,以及多文化姓名拼写变异,例如阿拉伯语姓名“Mohammed”的不同罗马化形式。构建过程中的挑战包括模拟真实错误模式,如申根信息系统二中不同成员国录入姓名时的顺序差异与非拉丁文字别名并存,以及自动车牌识别系统中由光学字符识别导致的字符混淆,如数字“0”与字母“O”的替换。这些挑战要求算法不仅处理模糊匹配,还需适应跨语言、跨脚本的实体对齐问题。
常用场景
经典使用场景
在实体解析与记录链接研究领域,荷兰执法实体解析基准数据集为模拟真实执法数据挑战提供了标准化测试平台。该数据集基于荷兰及欧盟执法数据模式构建,包含公司董事注册、申根信息系统人员记录及自动车牌识别通行事件等子集,通过注入荷兰姓名复杂性、跨文化拼写变异及OCR错误等模式,精准复现了执法环境中身份数据匹配的典型难点。研究者可借此评估算法在姓名前缀省略、日期估计及字符混淆等场景下的鲁棒性,推动实体解析技术向实际应用靠拢。
实际应用
在执法与公共安全领域,该数据集为身份验证、犯罪网络分析及跨境信息共享系统提供了关键的训练与验证资源。执法机构可利用其开发的模型,在申根信息系统内高效匹配不同成员国录入的嫌疑人别名,或在自动车牌识别系统中纠正因光学字符识别产生的车牌误读,从而提升案件侦破效率与情报准确性。此外,数据集模拟的人口统计特征与错误模式,也有助于优化荷兰人口登记、金融交易监控等民用系统的数据质量管理流程。
衍生相关工作
围绕该数据集,已衍生出一系列专注于跨文化实体解析与执法数据链接的经典研究。例如,学者们利用其复杂的姓名变体与日期估计模式,开发了基于注意力机制的神经网络模型,以处理荷兰-摩洛哥姓名中的罗马化差异。另有工作专注于结合规则与学习的混合方法,以解决车牌字符混淆问题。这些研究不仅推动了记录链接算法在噪声环境下的进步,也为后续构建更全面的合成执法数据基准(如涵盖电信记录或金融交易报告)奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


