twinkle-ai/tw-drug-labels-vision
收藏Hugging Face2026-05-03 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/twinkle-ai/tw-drug-labels-vision
下载链接
链接失效反馈官方服务:
资源简介:
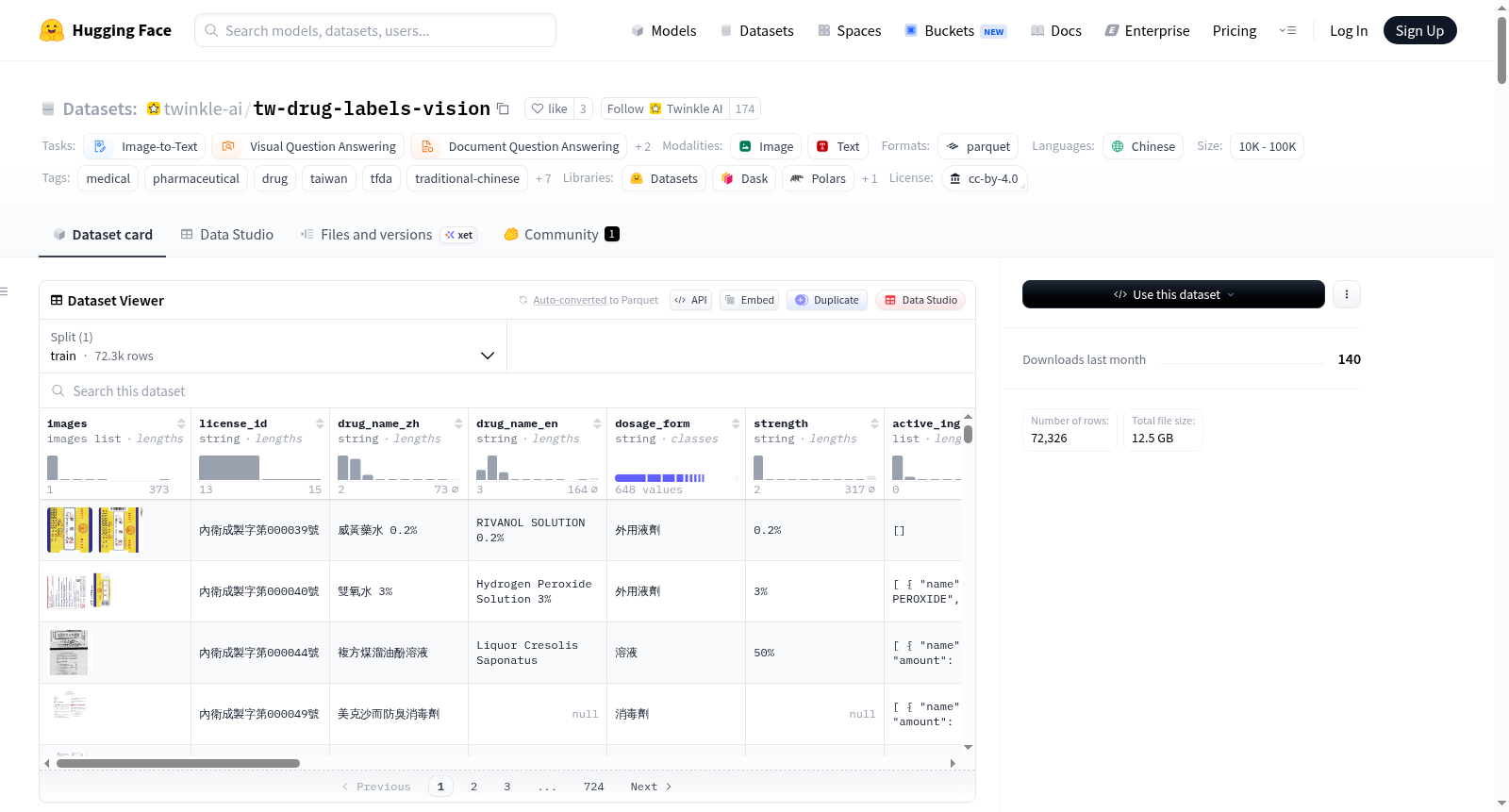
tw-drug-labels-vision 是一份涵盖台湾食品药物管理署(TFDA)核发之44,663笔药品仿单/外盒的繁体中文多模态数据集。每一笔纪录同时包含PDF全部页面的渲染图(WebP多页)以及一份依统一17栏JSON Schema抽取自原始药品标示文件的结构化资料,可直接用于语言模型微调、视觉语言模型训练、文件问答、药品知识检索、繁体中文医药NLP任务之素材。
tw-drug-labels-vision is a Traditional Chinese multimodal dataset covering 44,663 drug leaflets/cartons approved by the Taiwan Food and Drug Administration (TFDA). Each record includes rendered images of all pages of the PDF (multi-page WebP) and structured data extracted from the original drug labeling documents according to a unified 17-field JSON Schema. It can be directly used for language model fine-tuning, vision-language model training, document question answering, drug knowledge retrieval, and Traditional Chinese medical NLP tasks.
提供机构:
twinkle-ai
搜集汇总
数据集介绍
构建方式
本數據集源於臺灣食品藥物管理署(TFDA)公開的藥品許可證查詢系統。建構歷經三階段:首先,依據官方Excel清單中的PDF網址,並行下載原始藥品仿單與外盒文件;其次,運用PyMuPDF將每份PDF的各頁面渲染為WebP格式圖檔;最後,採用光學字符識別(OCR)技術提取文字,並由大型語言模型依照預先定義的17欄統一格式進行結構化抽取,嚴格要求不臆造缺漏欄位,並執行文字清洗與映射,最終產出44,663筆同時包含多頁圖像與結構化JSON的記錄。
特点
此數據集獨具雙模態特性,每筆記錄皆包含原始PDF所有頁面的WebP渲染圖像,以及經LLM精煉的17個標準化文字欄位,涵蓋藥品許可證字號、中英文品名、成分、適應症等核心資訊。其顯著特點在於圖文並茂,既保留了文件原始視覺版面,又提供了機器可讀的結構化數據。此外,數據集內含22,704筆仿單與21,959筆外盒,仿單欄位完整性高、臨床知識豐富,而外盒則側重基礎標示,為不同研究需求提供了多樣化的子集選擇。
使用方法
此數據集應用場景廣泛,主要支援視覺語言模型的微調,可將仿單或外盒圖像直接轉換為結構化JSON輸出;亦適用於文件視覺問答任務,以圖像與文字欄位作為真實標籤構建問答對。研究者還可藉助其豐富的繁體中文醫藥文本,進行語言模型的監督式微調,構造藥品問答指令對,或作為檢索增強生成系統的知識庫。特別建議在訓練臨床知識模型時優先選用仿單子集,以獲得較完整的藥物資訊,並應將文字欄位視為輔助標註,以原始圖像為事實基準進行驗證。
背景与挑战
背景概述
在繁體中文醫藥領域,高品質的多模態結構化資料長期匱乏,制約了視覺語言模型與自然語言處理技術在藥品資訊自動化抽取與臨床輔助決策中的發展。為填補這一空白,Liang Hsun Huang與Teemo Chuang於2026年基於臺灣食品藥物管理署(TFDA)公開的藥品許可證查詢系統,創建了tw-drug-labels-vision資料集。該資料集涵蓋44,663筆藥品仿單與外盒的多模態記錄,每筆資料同時包含PDF頁面的WebP渲染圖與依統一17欄JSON Schema抽取的結構化文字,可直接應用於視覺語言模型微調、文件問答、藥品知識檢索及繁體中文醫藥自然語言處理任務,為該領域的研究提供了規模可觀且格式統一的開放資源。
当前挑战
該資料集所應對的領域問題在於藥品標示文件(仿單與外盒)多以PDF圖檔形式存在,缺乏機器可讀的結構化資訊,導致下游模型訓練與知識檢索困難重重。資料構建過程中的挑戰尤為突出:第一,原始PDF源自印刷或掃描影像,光學字元辨識(OCR)階段容易產生字符錯誤,尤其對於化學名與規格數字等關鍵資訊,且誤差會傳遞至後續結構化結果;第二,外盒資料天然稀疏,僅包含基礎欄位,臨床相關欄位多為空值,需在使用時嚴格區分仿單與外盒子集;第三,部分仿單包含多個URL,當前版本僅擷取第一份PDF,導致頁面不完整;第四,擷取值來自即時TFDA公開內容,存在許可證變更或失效的時效性風險,不適用於即時藥政查詢;第五,大型語言模型在欄位邊界判定上存在主觀偏差(如將兒童禁忌歸入警語),需下游任務自行理解灰色地帶。
常用场景
经典使用场景
在醫藥資訊處理領域,tw-drug-labels-vision 資料集最經典的使用場景首推視覺語言模型(VLM)的微調訓練。該資料集提供逾四萬筆臺灣食品藥物管理署核發的藥品仿單與外盒之完整頁面渲染圖,並附有依統一17欄JSON Schema抽取的結構化資訊,研究者可藉由給定仿單圖檔,讓模型學習直接輸出對應的藥品許可證字號、中英文藥名、主成分、適應症、用法用量等關鍵欄位,實現從影像到結構化JSON的端到端生成。此外,該資料集亦廣泛應用於文件視覺問答(DocVQA),以圖檔搭配結構化文字作為真實標註,構建細粒度的藥品知識問答對,驅動模型在繁中醫藥場景下進行精準的文件理解與資訊提取。
解决学术问题
該資料集的誕生有效填補了繁體中文醫藥領域高品質結構化多模態數據稀缺的學術空白。過往研究者若要進行藥品仿單的資訊抽取、知識圖譜構建或問答系統開發,往往需耗費大量人力進行PDF解析與人工標註,tw-drug-labels-vision 透過標準化的OCR與LLM結構化抽取流程,一次性提供圖文並茂的44,663筆紀錄,使學界得以系統性地探討OCR誤差傳遞對下游任務的影響、多頁文件聚合理解、以及跨欄位知識推理等核心問題。其統一的schema與嚴謹的清洗規則(如缺漏填null、禁止模型臆造)為後續的繁中醫藥NLP與VLM研究建立了可重複驗證的基準,顯著降低了該領域的數據獲取門檻。
衍生相关工作
該資料集的發布已催生多項具有影響力的衍生學術工作。在模型層面,研究者以 tw-drug-labels-vision 為訓練素材,微調大型語言模型與視覺語言模型,發展出專注於繁體中文藥品問答的指令微調數據集(instruction-tuning dataset),透過過濾source_type=leaflet子集並設定答案最小長度,顯著提升模型在適應症、用法用量等臨床欄位上的生成品質。在知識工程層面,該資料集的結構化欄位被用作藥品知識圖譜的構建基石,透過藥名與主成分的對應關係,鏈結至國際藥物資料庫如DrugBank與PubMed,實現跨語言與跨來源的藥品資訊融合。此外,亦有研究以其OCR文字與結構化結果作為新式文件解析模型的評估基準,推進繁中醫藥領域的光學字符識別與版面理解技術。
以上内容由遇见数据集搜集并总结生成


