LT_Summarisation_Corpus
收藏Hugging Face2026-05-16 更新2026-05-17 收录
下载链接:
https://huggingface.co/datasets/VytautoDidziojoUniversitetas/LT_Summarisation_Corpus
下载链接
链接失效反馈官方服务:
资源简介:
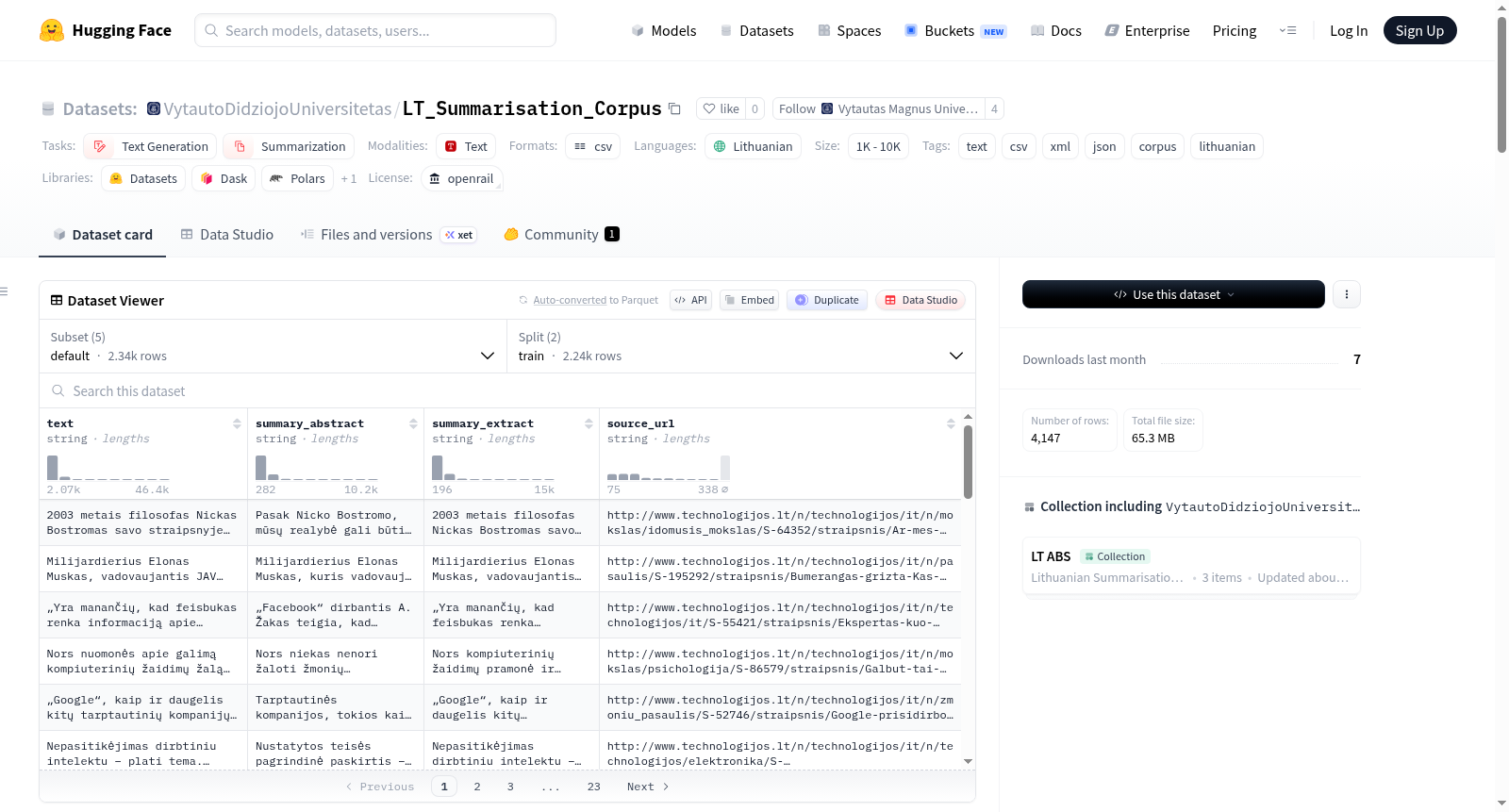
立陶宛语摘要语料库是一个专门为立陶宛语自然语言处理任务设计的数据集,尤其侧重于文本摘要。该语料库包含2340个立陶宛语文本样本,每个样本都配有人工撰写的抽象摘要和抽取式摘要。数据覆盖四个专业领域:信息技术(IT)、法律、医学和新闻媒体,旨在支持技术性和通用性语域的摘要系统开发与评估。数据集以CSV、JSON和XML格式提供,总大小约为21 MB,包含训练集(2251个样本)和测试集(100个样本)。主要数据字段包括原文(`text`)、抽象摘要(`summary_abstract`)、抽取式摘要(`summary_extract`)以及领域类型(`type`)。数据来源于多个权威渠道,如IT博客、学术论文、法律信息系统、法院案例、匿名医疗文档以及新闻网站。语料库总词数超过170万,摘要词数总计约85万。该数据集适用于文本生成、摘要、语言建模、语法风格校正、语义搜索等多种NLP任务。数据集采用NewGenLTU OpenRAIL-D许可证发布,允许负责任的开放使用,但明确禁止用于歧视、武器开发、自动决策影响个人、虚假信息等用途。需要注意的是,语料库中新闻文本和文档占主导(分别约52%和38%),可能使下游模型偏向这些语域。本数据集由维陶塔斯·马格努斯大学和维尔纽斯大学在欧盟NextGenerationEU及立陶宛“新世代立陶宛”计划资助下创建。
创建时间:
2026-05-16
原始信息汇总
数据集概述:立陶宛语摘要语料库
基本信息
- 数据集名称:Lithuanian Summarisation Corpus(立陶宛语摘要语料库)
- 语言:立陶宛语(lt)
- 许可证:NewGenLTU OpenRAIL-D
- 数据集大小:1M 至 30M 条记录
- 数据格式:CSV、JSON、XML
- 总文件大小:21 MB(训练集 20.3 MB,测试集 0.7 MB)
- 总文本数量:2,340 篇(训练集 2,251 篇,测试集 100 篇)
数据集构成
该语料库包含立陶宛语文本及其人工编写的抽象式摘要和抽取式摘要,涵盖四个主题领域:
| 领域 | 描述 | 来源 |
|---|---|---|
| IT(信息技术) | 信息技术文章 | IT 博客、学生学士/硕士论文、VU IT 研究期刊 |
| 法律(teisė) | 法律文档 | 立陶宛法院信息系统、法律登记册、最高法院判例、法律出版物 |
| 医学(medicina) | 医学文本 | 国家数据局提供的匿名化药房文件、医生诊断 |
| 媒体(žiniasklaida) | 新闻文章 | lrt.lt 新闻网站 |
数据分布
| 文本类型 | 文本词数 | 抽象式摘要词数 | 抽取式摘要词数 | 文本数量 |
|---|---|---|---|---|
| IT | 344,710 | 65,403 | 89,131 | 689 |
| 法律 | 668,276 | 155,893 | 224,446 | 533 |
| 医学 | 371,611 | 64,980 | 89,570 | 550 |
| 媒体 | 354,012 | 66,315 | 91,714 | 568 |
| 总计 | 1,738,609 | 352,591 | 494,861 | 2,340 |
主要字段
text:原始文本(字符串)summary_abstract:抽象式摘要(字符串)summary_extract:抽取式摘要(字符串)type:文本所属领域类型(字符串)
数据配置文件
数据集提供以下配置,每个配置包含训练集和测试集:
- default:所有领域数据,训练集为
csv/train/*.csv,测试集为csv/test/*.csv - it:仅信息技术领域,训练集
csv/train/it.csv,测试集csv/test/it.csv - teisė:仅法律领域
- medicina:仅医学领域
- žiniasklaida:仅媒体领域
预期用途
该数据集适用于以下立陶宛语 NLP 和 AI 任务:
- 文本生成
- 文本摘要
- 语言建模
- 语法与风格校正
- 语义搜索
- 文本分析
- 虚拟助手
- 其他语言技术应用
限制与偏差
- 语料库中新闻门户文本占 52%、法律文档占 38%,这可能导致下游模型偏向这些领域和语体。
- 开发者已尽力清洗数据、减少 OCR 错误和重复内容,但用户应知晓上述领域分布偏差。
引用信息
请引用为: Vytautas Magnus University and Vilnius University. 2026. Abstract Corpora for Artificial Intelligence. Hugging Face. https://huggingface.co/datasets/VytautoDidziojoUniversitetas/LT_Summarisation_Corpus
搜集汇总
数据集介绍
构建方式
LT_Summarisation_Corpus是一个专为立陶宛语文本摘要任务设计的高质量数据集,其构建过程严谨且系统。该数据集涵盖了信息技术、法律、医学和媒体四个核心领域,总计包含2340篇立陶宛语文本。每篇文本均附有人工撰写的抽象式和抽取式两种摘要,确保了摘要的多样性与准确性。数据来源广泛,包括技术博客、学术论文、法院信息系统、匿名化医疗记录以及新闻门户网站。数据集以CSV、JSON和XML三种格式提供,并按照领域划分为训练集和测试集,便于研究者灵活使用。
特点
该数据集的核心特点在于其多领域覆盖与双摘要模式。四个领域的文本在字数分布上各具特色,法律领域文本长度最长,而IT领域文本数量最多。抽象式摘要提炼核心语义,抽取式摘要保留原文关键句子,这种设计为训练不同类型的摘要模型提供了丰富资源。数据集规模适中,总文件大小约21MB,易于处理。此外,数据经过严格清洗以减少噪声和重复,但需注意新闻与法律文本占比过高,可能导致模型对这些领域产生偏好。
使用方法
LT_Summarisation_Corpus适用于多种立陶宛语自然语言处理任务,包括文本生成、摘要、语言建模、语法风格校正、语义搜索及虚拟助手开发。用户可通过Hugging Face的datasets库轻松加载,选择不同的配置名称(如'it'、'teise'、'medicina'或'ziniasklaida')以获取特定领域的数据。数据集提供'text'、'summary_abstract'、'summary_extract'和'type'四个主要字段,便于直接用于训练和评估。使用时需遵守NewGenLTU OpenRAIL-D许可证,禁止用于歧视、军事、虚假信息等不当用途。
背景与挑战
背景概述
立陶宛语作为波罗的海语族的代表性语言,其自然语言处理资源长期匮乏,尤其在文本摘要领域缺乏高质量标注语料。为填补这一空白,维陶塔斯大大学与维尔纽斯大学的研究团队于2026年联合发布了LT_Summarisation_Corpus数据集。该数据集涵盖信息技术、法律、医学与新闻四大领域,包含2340篇立陶宛语文本及其对应的人工撰写的抽象式和抽取式摘要,总词汇量逾170万词。作为“新一代立陶宛”计划资助的核心成果,该数据集不仅为低资源语言的文本生成与摘要研究提供了关键基准,更通过OpenRAIL-D许可协议推动负责任的AI开发,对立陶宛语NLP社区产生了深远影响。
当前挑战
该数据集所面对的挑战首要体现在领域问题的复杂性:立陶宛语形态丰富且语序灵活,使得抽象摘要生成需同时应对词汇稀疏与句法多样性的难题,而法律与医学文本中专业术语的浓缩精度则进一步考验模型的能力。其次在构建过程中,团队面临多重障碍:从公开网站与法院系统爬取法律文档时需处理OCR噪声与格式异构问题;医学数据因隐私法规只能使用国家数据局提供的匿名化样本,导致数据规模受限。此外,新闻文本占比过半的领域分布不均衡可能引入面向下游模型的归纳偏差,需通过领域重采样或特殊训练策略加以缓解。
常用场景
经典使用场景
作为立陶宛语自然语言处理领域的重要资源,LT_Summarisation_Corpus被广泛用于文本摘要任务的训练与评估。数据集涵盖了信息技术、法律、医学和媒体四个专业领域,每条原文均配备人工撰写的生成式摘要和抽取式摘要,使得模型能够在跨领域、多风格的立陶宛语文本中学习抽象与抽取两种摘要生成范式。研究者常利用该数据集进行有监督的序列到序列生成模型训练,或作为零样本与少样本摘要任务的基准测试集,亦可服务于语言模型在低资源语言场景下的泛化能力验证。
实际应用
在实际应用中,该数据集可用于构建面向立陶宛语用户的智能信息处理工具。例如,法律从业者可借助基于该数据训练的摘要系统,快速提取冗长法庭判例或法规文件的核心要义;医学领域则可辅助医生从病历或药品说明中提炼关键信息;媒体机构能够自动生成新闻摘要以提升内容分发效率;IT技术文档的自动摘要也有助于提高技术人员的知识检索速度。这些应用场景显著提升了立陶宛语环境下的信息处理自动化水平。
衍生相关工作
该数据集的发布为立陶宛语自然语言处理领域催生了多项后续研究。基于其多领域特性,研究者已开展领域自适应摘要方法的探索,分析不同语体(如法律条文与新闻报道)对摘要模型性能的影响。此外,数据集中同时提供生成式与抽取式摘要,促使相关工作对比两种范式的优劣,并尝试融合策略。部分工作还以此为基础,拓展至立陶宛语的语法纠错、语义搜索和虚拟助手等任务,形成了以摘要为核心、辐射多任务的语言技术研究生态。
以上内容由遇见数据集搜集并总结生成


