nferruz/UR50_2021_04
收藏Hugging Face2022-07-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/nferruz/UR50_2021_04
下载链接
链接失效反馈官方服务:
资源简介:
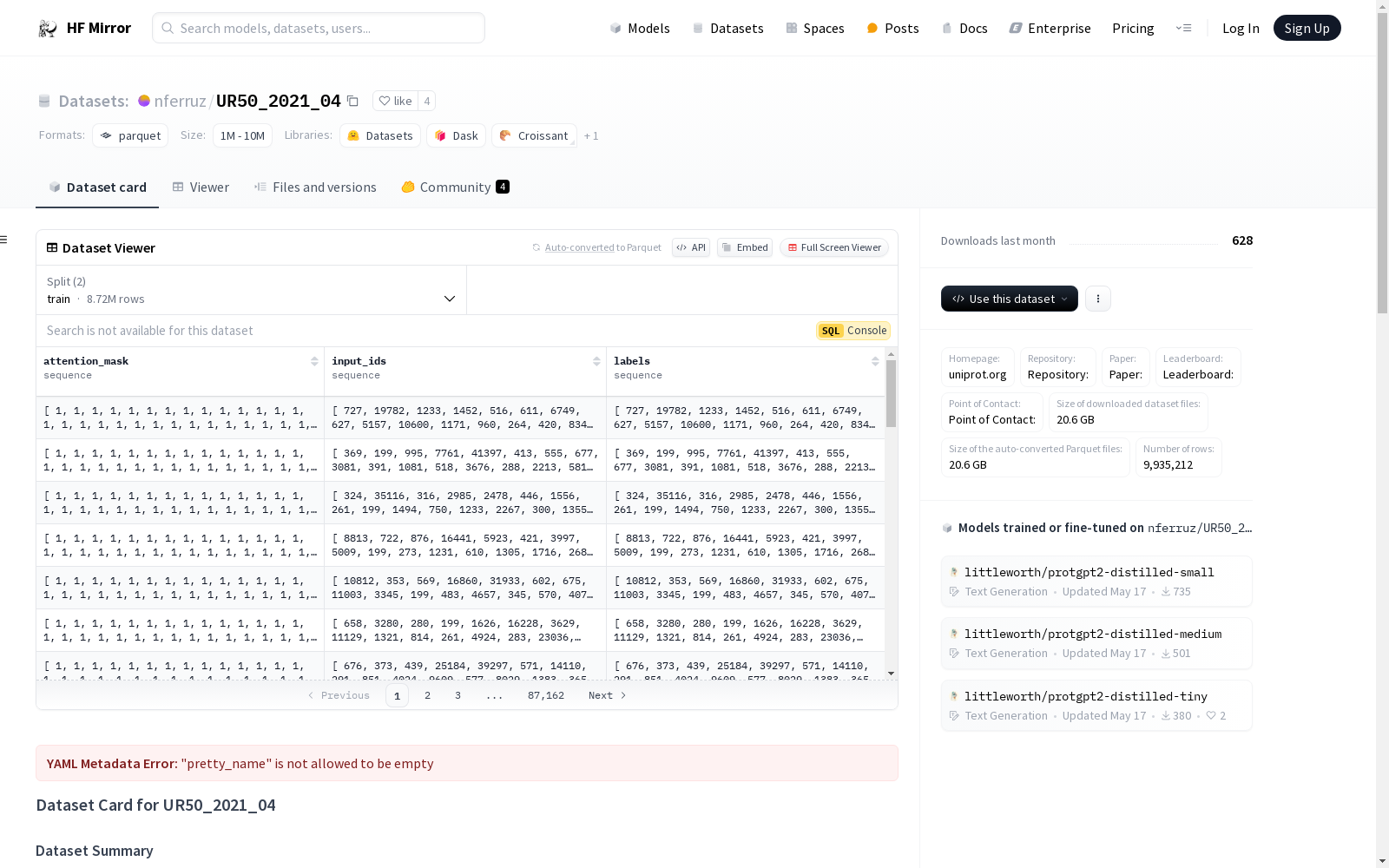
UR50_2021_04数据集是一个生物数据集,来源于Uniprot数据库,包含4800万个蛋白质序列。该数据集适用于训练蛋白质语言模型。数据集被分为训练集和验证集,比例为90/10。在数据集的创建过程中,FASTA头被替换为<endoftext>标签,并使用BPE进行分词。
The UR50_2021_04 dataset is a biological dataset derived from the UniProt database, containing 48 million protein sequences. This dataset is suitable for training protein language models. The dataset is split into training and validation sets at a 90:10 ratio. During the dataset creation process, FASTA headers were replaced with the <endoftext> tag, and tokenization was performed using BPE.
提供机构:
nferruz
原始信息汇总
数据集概述
数据集名称
- 名称: UR50_2021_04
数据集描述
- 摘要: The Uniref50 (UR50) dataset version 2021/04 是一个生物学数据集,来源于Uniprot数据库。
- 支持的任务: 包含4800万蛋白质序列,适用于训练蛋白质语言模型。
- 语言: 蛋白质
数据集结构
- 数据实例: 未详细说明
- 数据字段: 未详细说明
- 数据分割: 训练集和验证集
数据集创建
- 筛选理由: 使用<endoftext>标签替换FASTA头部,并使用BPE进行数据集的tokenization,进一步按90/10的比例随机分割为训练集和验证集。
- 源数据:
- 数据收集和标准化: 未详细说明
- 源语言生产者: UniProt
- 注释:
- 注释过程: UniProt包含注释,但本数据集未使用任何标签/注释。
- 注释者: 未详细说明
使用数据集的考虑
- 社会影响: 未详细说明
- 偏见讨论: 未详细说明
- 其他已知限制: 未详细说明
附加信息
- 数据集管理者: 未详细说明
- 许可信息: 未详细说明
- 引用信息: 未详细说明
- 贡献: 感谢UniProt对数据集的整理。
搜集汇总
数据集介绍
构建方式
UR50_2021_04数据集源自于Uniprot数据库,专门针对蛋白质序列进行了处理与优化。该数据集通过将原始FASTA格式的蛋白质序列头替换为<endoftext>标签,并采用BPE(Byte Pair Encoding)算法进行分词处理,进一步将数据划分为训练集和验证集,比例为90/10。这一构建过程确保了数据集在蛋白质语言模型训练中的高效性和适用性。
特点
UR50_2021_04数据集的核心特点在于其大规模的蛋白质序列数据,包含4800万条蛋白质序列,为蛋白质语言模型的训练提供了丰富的资源。此外,数据集的构建过程中未使用任何标签或注释,保持了数据的原始性和多样性,使其在生物信息学和蛋白质研究领域具有广泛的应用潜力。
使用方法
该数据集主要用于训练蛋白质语言模型,用户可以通过加载数据集并使用BPE分词后的序列进行模型训练。数据集已预先划分为训练集和验证集,用户可根据需要直接使用这些划分进行模型调优和评估。此外,由于数据集未包含任何注释信息,用户在使用时需自行定义任务和标签,以适应特定的研究需求。
背景与挑战
背景概述
UR50_2021_04数据集是由UniProt数据库提供的生物信息学数据集,专门用于蛋白质序列分析。该数据集发布于2021年4月,包含了4800万条蛋白质序列,旨在支持蛋白质语言模型的训练。主要研究人员或机构为UniProt,这是一个广泛认可的蛋白质序列和功能信息数据库。UR50_2021_04的核心研究问题集中在如何有效利用大规模蛋白质序列数据来提升蛋白质语言模型的性能,这对于生物信息学和蛋白质科学领域具有重要意义,尤其是在蛋白质功能预测和结构分析方面。
当前挑战
UR50_2021_04数据集在构建过程中面临的主要挑战包括数据的高维性和复杂性。蛋白质序列的多样性和长度变化使得数据预处理和特征提取变得复杂。此外,尽管UniProt数据库提供了丰富的蛋白质信息,但该数据集并未使用任何标签或注释,这增加了模型训练的难度,因为模型需要从无监督的数据中学习有用的表示。另一个挑战是数据集的规模,处理和存储如此大规模的数据对计算资源和算法效率提出了高要求。
常用场景
经典使用场景
在生物信息学领域,nferruz/UR50_2021_04数据集以其丰富的蛋白质序列信息,成为训练蛋白质语言模型的经典资源。该数据集包含了4800万条蛋白质序列,通过BPE(Byte Pair Encoding)技术进行分词处理,并划分为训练集和验证集,比例为90/10。这一划分方式为模型训练提供了充足的样本,使得模型能够在蛋白质序列的表示学习中取得优异表现。
解决学术问题
该数据集解决了蛋白质序列表示学习中的关键问题,尤其是在蛋白质语言模型的训练过程中,提供了大规模、高质量的蛋白质序列数据。通过使用该数据集,研究者能够更好地捕捉蛋白质序列中的复杂模式和结构信息,从而提升模型在蛋白质功能预测、结构预测等任务中的表现。这对于推动生物信息学领域的研究具有重要意义。
衍生相关工作
基于nferruz/UR50_2021_04数据集,研究者们开发了多种蛋白质语言模型,如ProtBERT和ESM等,这些模型在蛋白质序列的表示学习中表现出色。此外,该数据集还激发了大量关于蛋白质序列分析和功能预测的研究工作,推动了生物信息学领域的技术进步。这些衍生工作不仅提升了蛋白质研究的深度和广度,还为相关领域的实际应用提供了强有力的支持。
以上内容由遇见数据集搜集并总结生成


