twitter-sentiment-analysis
收藏Hugging Face2025-10-30 更新2025-10-31 收录
下载链接:
https://huggingface.co/datasets/bdstar/twitter-sentiment-analysis
下载链接
链接失效反馈官方服务:
资源简介:
Twitter情感分析数据集是一个经过精炼和合并的Twitter文本情感数据集,提供了干净且平衡的数据,适用于情感分类,包含三个情感类别:积极、消极和中立。数据集分为训练集、测试集和验证集,可用于训练、评估和基准测试NLP模型进行Twitter情感分析和其他社交媒体文本分类任务。
Twitter Sentiment Analysis Dataset is a refined and consolidated Twitter text sentiment dataset that provides clean and balanced data suitable for sentiment classification. It includes three sentiment categories: positive, negative, and neutral. The dataset is split into training, test, and validation sets, which can be used to train, evaluate, and benchmark NLP models for Twitter sentiment analysis and other social media text classification tasks.
创建时间:
2025-10-30
原始信息汇总
Twitter Sentiment Analysis 数据集概述
基本信息
- 数据集名称: twitter-sentiment-analysis
- 维护者: Md Abdullah Al Mamun
- 创建年份: 2025
- 许可证: MIT
- 语言: 英语
- 任务类别: 文本分类、标记分类
- 数据规模: 10M-100M
- 文件格式: JSON / Parquet / Pandas / Polars / Croissant
数据集描述
这是一个经过精炼和合并的Twitter文本情感数据集,提供干净且平衡的三分类情感分类数据,情感类别包括:正面(positive)、负面(negative)和中性(neutral)。
数据统计
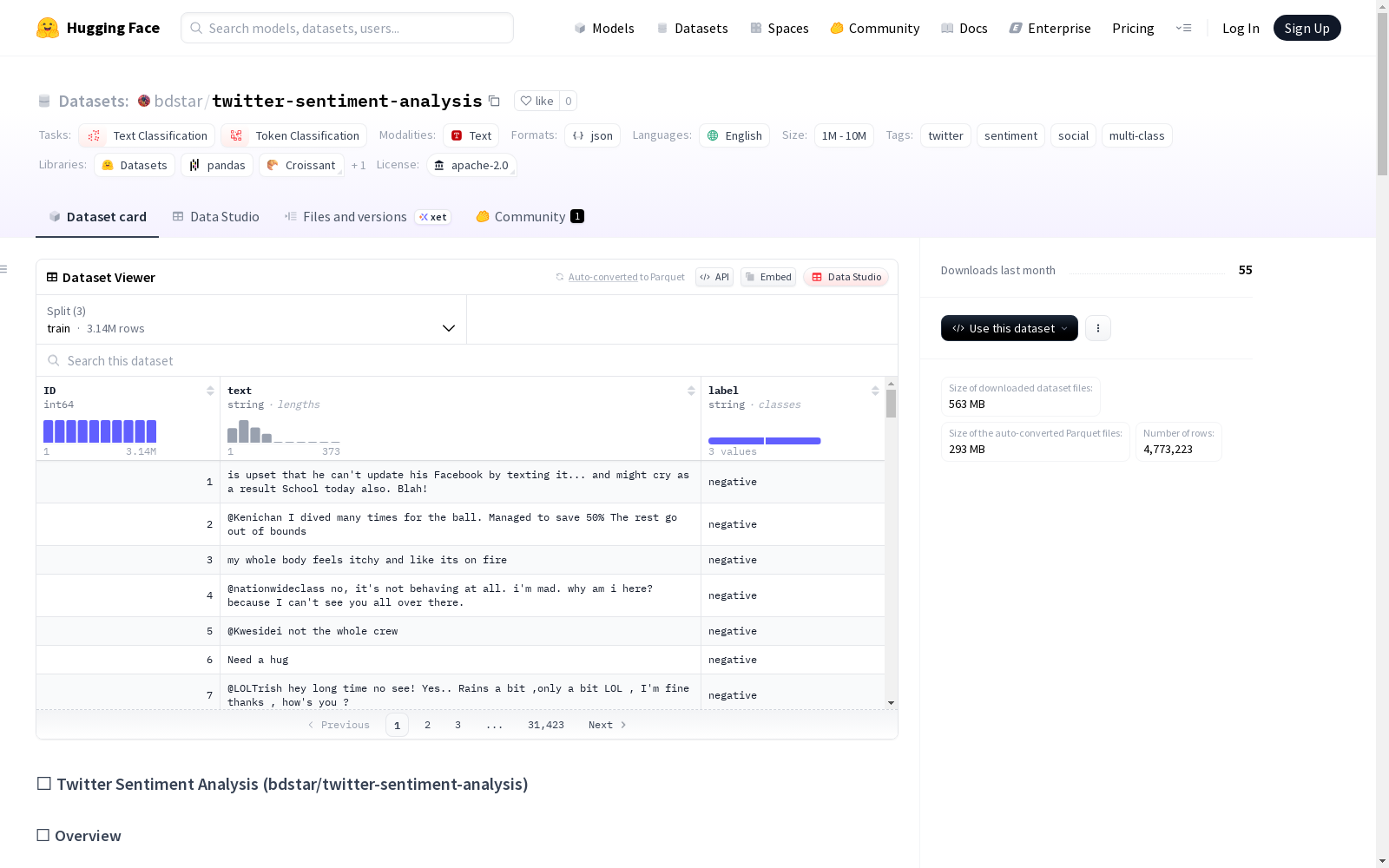
- 总行数: 4,773,225
- 列数: 3
- 数据分割: 训练集、测试集、验证集
数据分割详情
训练集
- 来源: Twitter Sentiment Dataset (3M labeled rows)
- 行数: 3,142,209
- 文件大小: 361 MB
- 标签分布:
- 正面: 1,571,104 (50.0%)
- 负面: 1,571,105 (50.0%)
测试集
- 来源: Sentiment140 Dataset
- 行数: 1,600,001
- 文件大小: 198 MB
- 标签分布:
- 正面: 800,000 (50.0%)
- 负面: 800,001 (50.0%)
验证集
- 来源: MTEB Tweet Sentiment Extraction
- 行数: 31,015
- 文件大小: 3.45 MB
- 标签分布:
- 中性: 12,561 (40.5%)
- 正面: 9,676 (31.2%)
- 负面: 8,778 (28.3%)
数据结构
| 列名 | 类型 | 描述 |
|---|---|---|
| ID | 整数 | 每行的自增唯一标识符 |
| text | 字符串 | 推文文本内容 |
| label | 字符串 | 情感类别(positive/negative/neutral) |
应用场景
- Twitter情感分析
- 社交媒体文本分类
- NLP模型训练与评估
- 模型基准测试
引用信息
bibtex @dataset{bdstar2025twitter, title = {Twitter Sentiment Analysis (Refined Dataset)}, author = {Md Abdullah Al Mamun}, year = {2025}, howpublished = {Hugging Face}, url = {https://huggingface.co/datasets/bdstar/twitter-sentiment-analysis} }
搜集汇总
数据集介绍
构建方式
在社交媒体情感分析领域,该数据集通过整合多个权威开源语料构建而成。训练集源自Kaggle平台包含314万条标注记录的Twitter情感数据集,测试集采用Sentiment140项目的160万条平衡数据,验证集则来自MTEB推文情感抽取任务的3.1万条样本。这种多源融合策略既确保了数据规模的扩展性,又通过不同来源的数据分布提升了模型的泛化能力。
使用方法
研究者可通过Hugging Face数据集库直接加载该资源,使用标准接口获取训练、测试与验证三个子集。每个样本包含唯一ID、推文文本和情感标签三列数据,支持JSON、Parquet等多种格式读取。典型应用流程包括:加载数据后分别提取各子集,利用训练集进行模型参数优化,通过验证集调整超参数,最终在平衡分布的测试集上评估模型性能,实现端到端的社交媒体情感分类任务。
背景与挑战
背景概述
社交媒体情感分析作为自然语言处理的重要分支,twitter-sentiment-analysis数据集于2025年由研究者Md Abdullah Al Mamun整合构建。该数据集融合了Twitter Sentiment Dataset、Sentiment140和MTEB Tweet Sentiment Extraction三个权威数据源,形成包含477万余条推文的语料库。其核心研究目标在于解决社交媒体文本的情感极性分类问题,通过精准标注积极、消极与中性三类情感,为情感计算模型提供高质量的基准数据。该数据集的建立显著推进了社交平台舆情监测、用户行为分析等领域的研究进程。
当前挑战
在情感分析领域,该数据集面临的首要挑战在于处理社交媒体文本特有的语言复杂性,包括网络用语、表情符号和多语言混杂现象。数据构建过程中需克服原始数据源的标注不一致问题,特别是中性情感的界定标准差异。此外,推文文本的短小特性与上下文缺失增加了情感判定的难度,而数据时效性要求又使得模型需要持续适应新兴的网络表达方式。这些挑战共同构成了社交媒体情感分析技术发展的关键瓶颈。
常用场景
经典使用场景
在社交媒体情感分析研究领域,该数据集为自然语言处理模型提供了标准化的训练与评估基准。其精心整合的470余万条推文数据,涵盖积极、消极与中性三种情感类别,成为情感分类任务中不可或缺的资源。研究者通过该数据集能够系统性地训练深度学习模型,验证情感识别算法的准确性与鲁棒性,推动文本情感分析技术的持续发展。
解决学术问题
该数据集有效解决了社交媒体文本情感分析中的多类别分类难题。通过提供均衡的三类情感标注数据,为研究社区建立了统一的评估标准。其大规模标注样本显著缓解了传统方法中因数据稀疏导致的模型泛化能力不足问题,同时为跨领域情感迁移学习、领域自适应等前沿研究方向提供了可靠的数据支撑,极大促进了情感计算领域的理论创新。
实际应用
在商业智能与社会舆情监测领域,该数据集展现出广泛的应用价值。企业通过基于此数据集训练的模型,能够实时分析消费者对产品的情感倾向,优化市场营销策略。政府部门则可借助其监测社会舆论动态,及时把握民意走向。金融行业亦能利用情感分析预测市场情绪波动,为投资决策提供数据支持,充分体现了学术研究向实际应用的转化价值。
数据集最近研究
最新研究方向
社交媒体情感分析领域正聚焦于多模态融合与跨领域迁移学习的前沿探索。基于Twitter Sentiment Analysis数据集,研究者们致力于整合文本与图像模态信息,通过预训练语言模型捕捉推特平台特有的网络用语和表情符号语义。在热点事件监测方面,该数据集支撑了突发事件舆论演化分析和品牌声誉动态追踪系统的开发。其超过470万条标注数据为细粒度情感分类提供了坚实基础,推动金融舆情预警和公共卫生政策评估等跨学科应用取得显著进展。
以上内容由遇见数据集搜集并总结生成


