Malaysian-Translation
收藏Hugging Face2025-09-01 更新2025-09-02 收录
下载链接:
https://huggingface.co/datasets/mesolitica/Malaysian-Translation
下载链接
链接失效反馈官方服务:
资源简介:
这是一个用于训练翻译模型的带噪声的翻译数据集,包含两个训练阶段。第一阶段的数据噪声较多,第二阶段的数据相对更干净。
提供机构:
Mesolitica
创建时间:
2025-08-31
原始信息汇总
Malaysian-Translation 数据集概述
数据集简介
Malaysian-Translation 是一个用于训练翻译模型的噪声翻译数据集,包含两个训练阶段:第一阶段噪声较多,第二阶段相对更干净。
配置详情
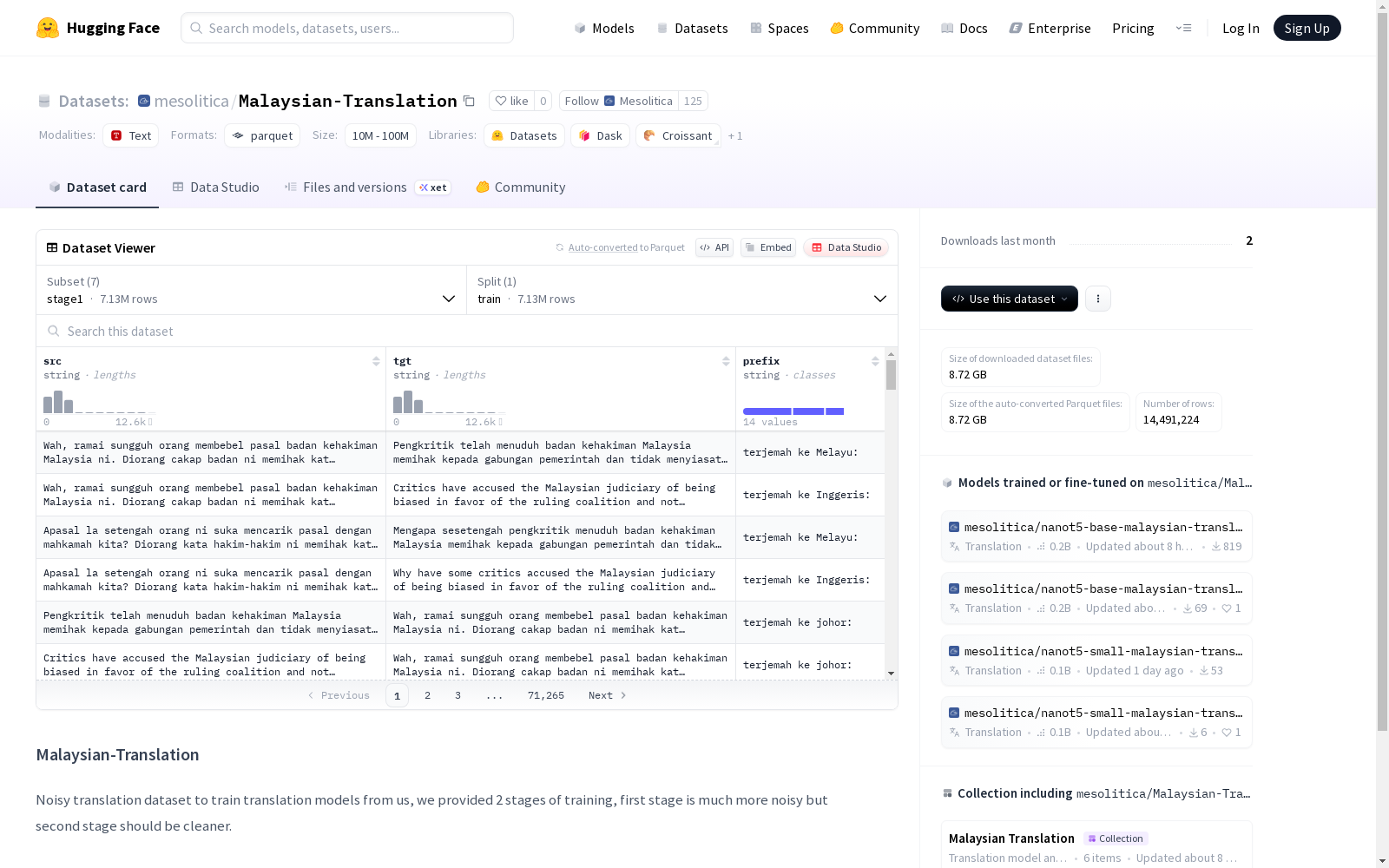
stage1
- 特征列:src(源文本)、tgt(目标文本)、prefix(前缀)
- 训练集样本数量:7,126,486
- 训练集大小:15,959,868,443 字节
- 下载大小:5,125,388,569 字节
stage2-coding
- 特征列:src(源文本)、tgt(目标文本)、prefix(前缀)
- 训练集样本数量:528,958
- 训练集大小:1,746,112,908 字节
- 下载大小:698,081,808 字节
stage2-coding-blocks
- 特征列:src(源文本)、tgt(目标文本)、prefix(前缀)
- 训练集样本数量:305,906
- 训练集大小:399,609,336 字节
- 下载大小:128,998,575 字节
stage2-coding-blocks-dialects
- 特征列:src(源文本)、tgt(目标文本)、prefix(前缀)
- 训练集样本数量:61,124
- 训练集大小:113,878,168 字节
- 下载大小:23,146,881 字节
stage2-coding-blocks-jawi
- 特征列:src(源文本)、tgt(目标文本)、prefix(前缀)
- 训练集样本数量:36,314
- 训练集大小:78,490,788 字节
- 下载大小:15,708,265 字节
stage2-part1
- 特征列:src(源文本)、tgt(目标文本)、prefix(前缀)
- 训练集样本数量:174,202
- 训练集大小:546,435,822 字节
- 下载大小:176,441,582 字节
stage2-part2
- 特征列:src(源文本)、tgt(目标文本)、prefix(前缀)
- 训练集样本数量:6,258,234
- 训练集大小:5,579,591,700 字节
- 下载大小:2,556,262,490 字节
数据特征
所有配置均包含相同的三个文本特征列:源文本(src)、目标文本(tgt)和前缀(prefix),数据类型均为字符串。
数据访问
数据集可通过 https://huggingface.co/datasets/mesolitica/Malaysian-Translation 获取。
搜集汇总
数据集介绍
构建方式
在机器翻译领域,高质量双语语料的稀缺性促使研究者探索创新数据构建方法。Malaysian-Translation数据集采用分阶段构建策略,第一阶段整合712万条噪声较多的翻译对,第二阶段通过多维度优化生成688万条清洗数据,特别包含代码块、方言和爪夷文等专项语料,形成层次化的训练体系。
特点
该数据集显著特征体现在其多维度语言覆盖与质量分层结构。不仅包含通用领域翻译对,还专门集成计算机代码、地方方言及传统爪夷文等稀缺资源,每个子集均配备前缀标识符以区分语境。超过1300万条平行句对构成东南亚语言翻译研究中规模最大、类型最丰富的资源之一。
使用方法
实践应用中建议采用分阶段训练范式,首先利用大规模噪声数据建立基础翻译能力,继而采用高质量子集进行精细化调优。研究人员可根据特定需求选择代码翻译、方言处理或文字转换专项数据集,通过前缀控制实现多任务联合训练,有效提升模型在马来西亚语言场景下的泛化性能。
背景与挑战
背景概述
马来西亚翻译数据集由本地研究团队于近期构建,专注于解决马来语与英语之间的机器翻译问题。该数据集通过多阶段构建策略,旨在提升低资源语言对的翻译质量,为东南亚语言处理领域提供重要数据支撑。其大规模平行语料覆盖通用领域和特定方言变体,对促进跨语言文化交流具有显著学术价值。
当前挑战
数据集核心挑战在于处理马来语方言变体(如爪夷文)与通用语之间的语义对齐,以及噪声数据的清洗与标注。构建过程中需解决网络爬取数据的质量不一致性,包括语法错误、口语化表达和代码混合现象,同时需保持不同方言变体间的翻译一致性,这对数据预处理和质量验证提出较高要求。
常用场景
经典使用场景
在机器翻译研究领域,Malaysian-Translation数据集主要用于训练和评估英语与马来语之间的双向翻译模型。该数据集通过分阶段训练策略,首先利用大规模噪声数据提升模型的泛化能力,继而采用清洗后的高质量数据优化翻译精度。这种设计特别适用于处理低资源语言对中的噪声干扰问题,为跨语言语义转换提供了有效的训练范式。
衍生相关工作
基于该数据集衍生的经典工作包括噪声自适应机器翻译框架、多阶段课程学习算法以及低资源语言联合训练模型。这些研究显著提升了马来语翻译在语法一致性、文化特定表达等方面的性能,后续工作进一步扩展至东盟语言族的跨语言迁移学习,形成了区域语言技术研究的重要分支。
数据集最近研究
最新研究方向
在低资源语言机器翻译研究领域,马来西亚语翻译数据集正推动多模态与方言处理的创新探索。该数据集通过分阶段训练架构,为处理噪声数据与纯净语料的平衡提供了新范式,特别是在爪夷文与方言变体的跨文字系统翻译方面展现出独特价值。当前研究聚焦于利用该数据集构建端到端的神经机器翻译模型,结合迁移学习技术提升小语种翻译性能,同时关注其在东南亚多语言文化交流中的实际应用,为一带一路沿线国家的语言技术发展提供重要数据支撑。
以上内容由遇见数据集搜集并总结生成


