FINQA
收藏arXiv2022-05-07 更新2024-06-21 收录
下载链接:
https://github.com/czyssrs/FinQA
下载链接
链接失效反馈官方服务:
资源简介:
FINQA是一个由金融专家基于S&P 500公司盈利报告构建的大型数据集,包含8281个金融问答对及其数值推理过程。该数据集旨在自动化分析大量金融文档,解决金融领域中复杂的数值推理和异构表示理解问题。FINQA不仅包含问答对,还提供了详细的推理程序,确保完全可解释性。该数据集的应用领域主要集中在金融分析,帮助专业人士如分析师或投资者进行高质量、及时的决策。
FINQA is a large-scale dataset constructed by financial experts based on the earnings reports of S&P 500 companies, containing 8,281 financial question-answer pairs and their corresponding numerical reasoning processes. This dataset aims to automate the analysis of massive financial documents, addressing the challenges of complex numerical reasoning and heterogeneous representation understanding in the financial domain. In addition to the question-answer pairs, FINQA also provides detailed reasoning procedures to ensure full interpretability. Its main application scenarios focus on financial analysis, assisting professionals such as analysts and investors in making high-quality and timely decisions.
提供机构:
加州大学圣巴巴拉分校
创建时间:
2021-09-01
搜集汇总
数据集介绍
构建方式
在金融文本分析领域,FINQA数据集的构建体现了严谨的专家驱动范式。其核心数据源选自标准普尔500公司公开的收益报告,并基于FinTabNet数据集进行筛选,仅保留包含单一表格且结构规范的报告页面。构建过程由十一位具备专业资质的金融专家主导,他们针对每份报告撰写需要数值推理的深度问题,并同步标注解答所需的推理程序与支撑事实。整个标注流程通过定制化平台实施,确保了问题在财务分析层面的意义与程序在数学和表格操作上的正确性,最终形成了8,281对高质量问答数据。
特点
FINQA数据集的核心特点在于其专注于金融领域的复杂数值推理,并融合了多模态信息理解。该数据集的问题设计深刻反映了真实财务分析场景,要求模型同时处理结构化表格与非结构化文本中的异质信息,并执行多步骤的数值运算,如比率计算、跨年度比较及表格聚合等。尤为突出的是,数据集为每个问题提供了可执行的、符号化的黄金推理程序,这为模型的推理过程提供了完整的可解释性基础,同时也设立了严格的程序准确性评估标准。其问题覆盖了纯文本、纯表格及混合信息源三种场景,对模型的综合理解与推理能力提出了全面挑战。
使用方法
FINQA数据集主要用于训练和评估面向金融领域的数值推理问答模型。典型的使用方法遵循检索-生成的两阶段框架:首先,模型需要从冗长的财务报告中检索出与问题相关的支撑事实(文本句子或表格行);随后,基于检索到的上下文信息,模型需生成一个由预定义操作(如加、减、乘、除、表格聚合等)序列构成的可执行程序,并通过执行该程序得到最终答案。评估时,不仅关注最终答案的执行准确率,也通过比较生成程序与黄金程序的符号等价性来评估推理路径的准确性。该数据集适用于研究领域自适应预训练、复杂程序生成、以及金融文档的多模态理解等前沿方向。
背景与挑战
背景概述
FINQA数据集由加州大学圣塔芭芭拉分校联合摩根大通、宾夕法尼亚州立大学及卡内基梅隆大学的研究团队于2021年推出,旨在推动金融领域数值推理的自动化研究。该数据集聚焦于深度分析企业财务报告,通过专家标注的问答对及可解释推理程序,解决了传统自然语言处理模型在复杂金融文档理解上的局限性。其核心研究问题在于如何从异构的表格与文本数据中提取信息,并执行多步骤数值计算以回答专业财务问题,为金融自然语言处理领域提供了首个大规模、高难度的基准资源,显著促进了领域专用模型的发展。
当前挑战
FINQA数据集面临的挑战主要体现在两大维度:其一,在领域问题层面,金融数值推理需克服异构数据融合、复杂多步计算及专业术语理解的难题,例如模型必须同时解析表格中的结构化数据与文本中的描述性信息,并执行如比率计算、跨年度比较等高级运算;其二,在构建过程中,数据筛选需排除财务报告中不适宜推理的复杂嵌套表格,而标注工作则依赖具备CPA、MBA等资质的金融专家,以确保问题的专业性与推理路径的准确性,这导致了较高的标注成本与严格的质控要求。
常用场景
经典使用场景
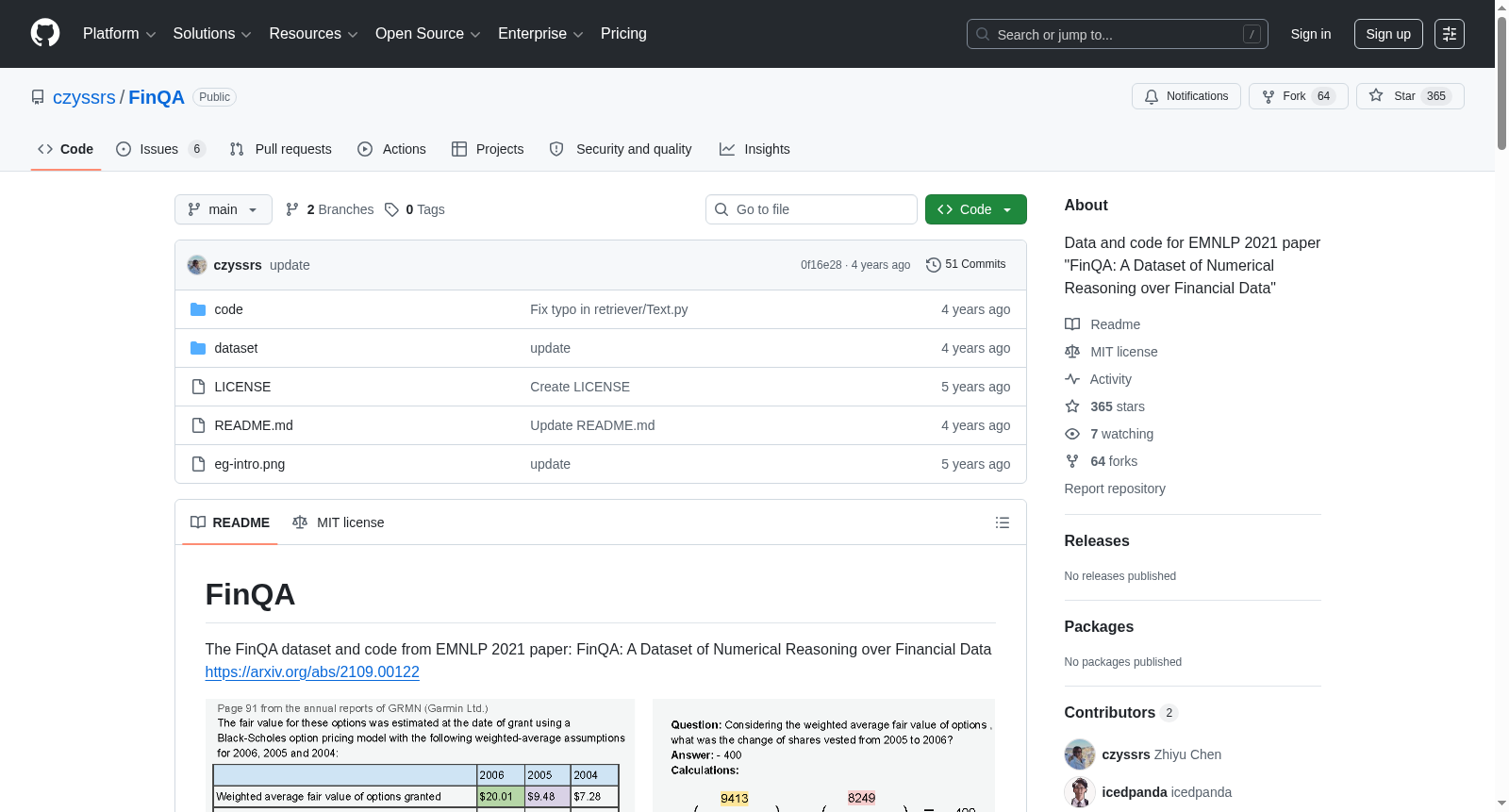
在金融自然语言处理领域,FINQA数据集为复杂数值推理任务提供了基准测试平台。该数据集的核心应用场景在于训练和评估模型对财务报告进行深度分析的能力,特别是要求系统从异构数据源(结构化表格与非结构化文本)中提取关键信息,并执行多步骤的数值计算。例如,模型需要理解“考虑期权的加权平均公允价值,2005年至2006年已归属股份的变化是多少?”这类问题,通过检索表格中的加权平均公允价值数据与文本中的股份总公允价值,执行除法与减法运算得出答案。这种场景模拟了金融分析师在实际工作中整合跨模态财务信息、进行比率计算与趋势分析的典型流程,为自动化财务问答系统的研发奠定了数据基础。
实际应用
FINQA数据集的实际应用价值主要体现在金融科技与智能投研领域。基于该数据集训练的模型可辅助金融机构自动化处理海量财务报告,快速提取关键财务指标(如利润率变化、税务状况净变动、股份价值计算等),从而提升投资分析与风险评估的效率。例如,在投行或会计师事务所,此类系统能够帮助分析师实时监控多家上市公司的财务健康状况,自动生成量化洞察,减少人工查阅报表的时间成本与主观误差。此外,该系统也可集成至智能客服或财务教育平台,为普通投资者提供易懂的财务数据解读,增强金融信息的普及性与透明度。
衍生相关工作
FINQA数据集的发布催生了一系列围绕金融数值推理的衍生研究工作。在模型架构方面,研究者提出了如FinQANet等检索-生成框架,结合预训练语言模型(如BERT、RoBERTa)与程序生成机制,为后续的神经符号推理模型提供了基线。同时,该数据集激发了领域专用预训练模型的探索,例如针对金融语料优化的语言模型,以提升对专业术语与数值关系的理解。在任务扩展上,后续工作开始关注更复杂的表格布局(如嵌套结构)、多文档推理以及实时财务流数据处理,进一步推动自动化财务分析向更深层次的决策支持系统演进。这些衍生工作共同丰富了金融自然语言处理的技术生态,促进了学术界与工业界在可解释AI与专业领域应用上的交叉创新。
以上内容由遇见数据集搜集并总结生成


