cvqa
收藏Hugging Face2024-11-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/neulab/cvqa
下载链接
链接失效反馈官方服务:
资源简介:
CVQA是一个多语言、文化多样性的视觉问答基准数据集,包含来自33个国家和地区语言对的9000多个问题。问题以本地语言和英语两种形式呈现,并分为10个不同的类别。数据集设计用于测试集,包含图像、问题、翻译问题、选项、翻译选项、标签、类别、图像类型、图像来源和许可证等字段。数据集的创建涉及问题制定和验证两个步骤,由熟练的注释者手工制作问题,并经过另一注释者的验证。注释者主要是母语者,且在相应国家居住超过16年。数据集的每个问题都有其自己的许可证,所有数据可用于研究目的,但并非所有条目都允许商业使用。
CVQA is a multilingual, culturally diverse Visual Question Answering (VQA) benchmark dataset containing over 9,000 questions spanning language pairs from 33 countries and regions. Each question is provided in both its native language and English, and is categorized into 10 distinct categories. This dataset is designed for evaluation and testing purposes, and includes fields such as image, question, translated question, option, translated option, label, category, image type, image source, and license. The development of the dataset involves two core stages: question formulation and validation. Questions are manually crafted by skilled annotators, and then verified by a separate annotator. The annotators are primarily native speakers who have resided in their respective countries for more than 16 years. Each question in the dataset has its own individual license. All data is available for research purposes, but not all entries permit commercial utilization.
提供机构:
NeuLab @ LTI/CMU创建时间:
2024-11-01
原始信息汇总
CVQA数据集概述
数据集基本信息
- 名称: CVQA
- 语言: 包含33个国家和地区语言对
- 规模: 1K<n<10K
- 任务类别: 问答
- 数据集大小: 4778972036.042字节
- 下载大小: 4952302684字节
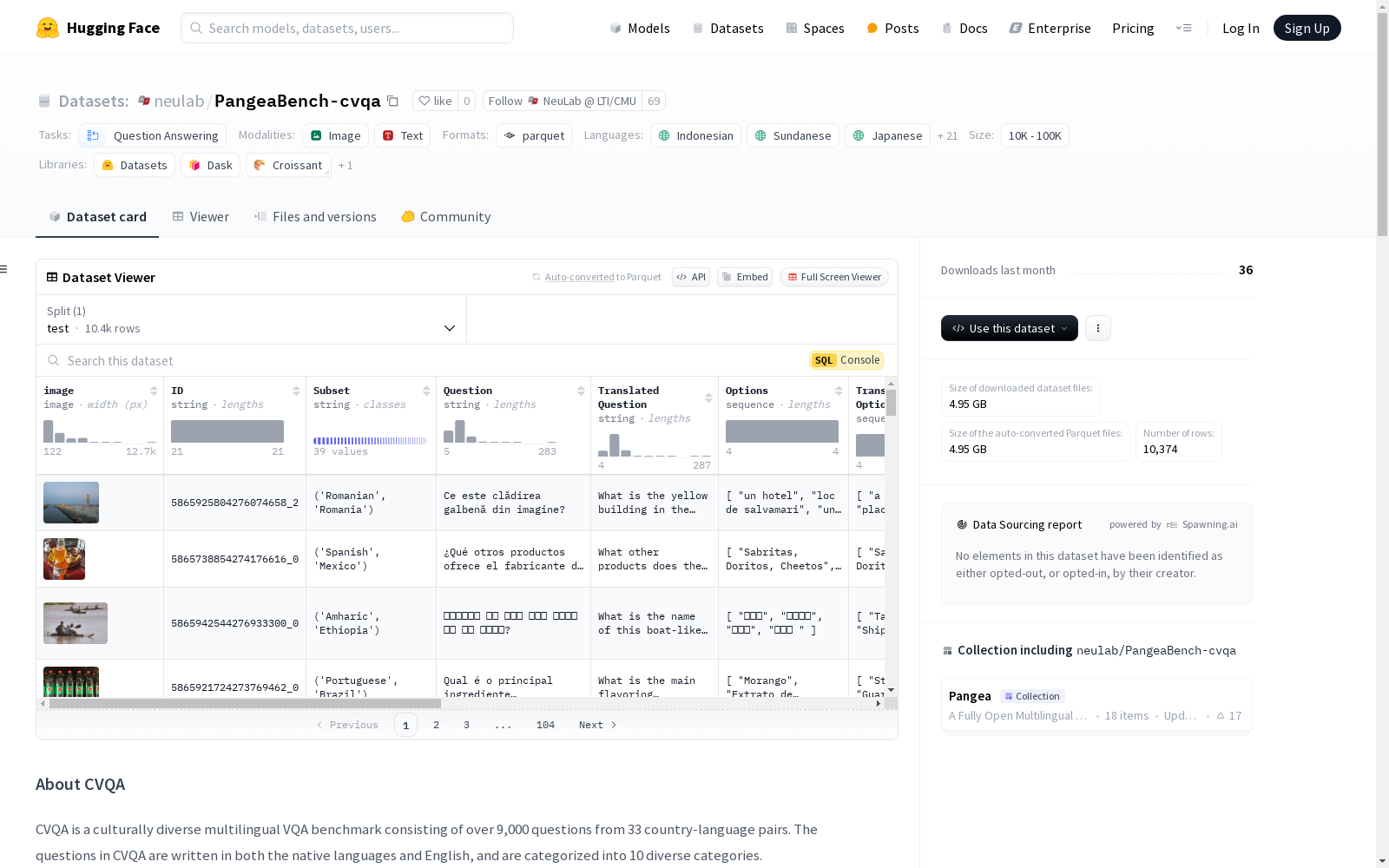
数据集结构
特征
- image: 图像,数据类型为image
- ID: 唯一ID,数据类型为string
- Subset: 语言-国家对,数据类型为string
- Question: 本地语言的问题,数据类型为string
- Translated Question: 英文翻译的问题,数据类型为string
- Options: 本地语言的答案选项列表,数据类型为sequence
- Translated Options: 英文翻译的答案选项列表,数据类型为sequence
- Label: 标签,数据类型为int64,值始终为-1
- Category: 样本类别,数据类型为string
- Image Type: 图像类型,数据类型为string,值为
Self或External - Image Source: 图像来源,数据类型为string
- License: 图像对应的许可证,数据类型为string
数据实例
- test分割包含10374个样本
数据集创建
数据来源
- 图像来源可以是现有的外部图像或贡献者自己的图像
- 外部图像保留原始许可证,贡献者的图像根据贡献者的决定进行许可
数据标注
- 数据创建包括问题制定和验证两个步骤
- 标注者需要编写一个问题,包含一个正确答案和三个干扰项
- 问题必须与图像相关,且具有文化特色
- 另一个标注者负责检查和验证图像和问题是否符合指南
标注者
- 标注者需要是相关语言的流利使用者,并熟悉相关文化
- 标注者主要是母语使用者,约89%的标注者在相应国家居住超过16年
许可证信息
- 每个问题都有自己的许可证
- 所有数据可用于研究目的,但并非每个条目都允许商业使用
搜集汇总
数据集介绍
构建方式
CVQA数据集的构建过程体现了跨文化协作的深度与广度。该数据集由MBZUAI研究团队主导,通过多国语言对的形式,收集了来自33个国家和地区的超过9,000个问题。数据的核心来源包括外部图像和贡献者自有的图像,确保了图像的多样性与真实性。问题的设计由母语为当地语言的注释者手工完成,每个问题均包含一个正确答案和三个干扰项,且问题需具备文化敏感性。在数据验证阶段,另一组注释者对图像和问题进行了严格审查,确保其符合指导原则。
特点
CVQA数据集以其文化多样性和多语言特性著称,涵盖了33种语言对,问题以本地语言和英语双语呈现,并分为10个不同的类别。每个数据样本包含图像、问题、选项及其翻译,以及图像来源和许可信息。特别值得注意的是,数据集中的问题设计注重文化背景,避免了敏感信息和易于泄露答案的文本。此外,图像的来源多样化,既有外部图像,也有贡献者自有的图像,且每张图像均附有明确的许可信息,确保了数据的合法性与透明度。
使用方法
CVQA数据集主要作为测试集使用,旨在评估模型在跨文化视觉问答任务中的表现。用户可以通过提交模型预测结果至指定的评估平台进行性能测试。数据集的结构清晰,每个样本包含图像、问题、选项及其翻译等字段,便于模型进行多语言和跨文化的理解与推理。使用该数据集时,需注意每个问题的许可信息,确保在研究和商业用途中的合规性。通过CVQA,研究者能够深入探索模型在不同文化背景下的泛化能力与适应性。
背景与挑战
背景概述
CVQA数据集是由MBZUAI研究团队主导构建的一个跨文化多语言视觉问答基准测试集,旨在评估模型在不同文化和语言背景下的表现。该数据集包含来自33个国家-语言对的9000多个问题,问题以本地语言和英语双语形式呈现,并分为10个不同的类别。CVQA的创建标志着视觉问答领域向多语言和跨文化方向的重要拓展,为研究者在全球化背景下开发更具包容性和适应性的模型提供了宝贵资源。
当前挑战
CVQA数据集面临的挑战主要体现在两个方面:首先,在领域问题层面,如何确保模型能够准确理解和回答具有文化特定性的问题,这要求模型不仅具备视觉理解能力,还需具备跨文化知识;其次,在构建过程中,如何确保数据的高质量和多样性,包括处理多语言翻译的准确性、文化敏感信息的处理,以及图像和问题的版权合规性,都是构建团队需要克服的难题。这些挑战反映了在全球化背景下开发多语言视觉问答系统的复杂性。
常用场景
经典使用场景
CVQA数据集在跨文化多语言视觉问答(VQA)领域具有重要应用。该数据集通过包含33种国家-语言对的9000多个问题,为研究者提供了一个测试模型在多样化文化背景下的表现平台。经典使用场景包括评估模型在处理不同语言和文化背景下的图像理解能力,特别是在多语言环境中的问答准确性。
衍生相关工作
CVQA数据集衍生了一系列相关研究,特别是在多语言和跨文化视觉问答领域。基于该数据集的研究工作包括开发新的多语言VQA模型、改进现有模型的跨文化理解能力,以及探索文化差异对视觉问答系统性能的影响。这些研究进一步推动了多语言VQA技术的发展,并为未来的研究提供了丰富的参考和基础。
数据集最近研究
最新研究方向
在跨文化视觉问答(VQA)领域,CVQA数据集以其多语言和多元文化的特性,成为研究热点之一。该数据集涵盖了33种国家-语言对的9000多个问题,涉及10个不同类别,为模型在跨文化理解能力上的评估提供了重要基准。近年来,研究者们致力于通过CVQA探索多模态模型在处理文化差异和语言多样性时的表现,尤其是在图像与文本的跨模态对齐、文化背景知识的融入等方面。随着全球化进程的加速,CVQA在推动多语言和多文化人工智能应用中的重要性日益凸显,为跨文化沟通、教育技术以及本地化服务等领域提供了新的研究视角和技术支持。
以上内容由遇见数据集搜集并总结生成


