medmentions-ner
收藏Hugging Face2025-08-12 更新2025-08-13 收录
下载链接:
https://huggingface.co/datasets/geraldamasi/medmentions-ner
下载链接
链接失效反馈官方服务:
资源简介:
MedMentions BioNER数据集是一个定制的预处理版本,专门用于生物医学命名实体识别(NER)任务。该数据集基于MedMentions数据集,包含128种来自UMLS语义类型的实体类别,采用BIO标注方案。数据集以英文为主要语言,分为训练集、验证集和测试集,比例分别为80%、10%和10%。每个句子由一系列单词和对应的BIO标签组成。
The MedMentions BioNER dataset is a customized preprocessed version specifically designed for biomedical named entity recognition (NER) tasks. Derived from the original MedMentions dataset, it includes 128 entity categories from UMLS semantic types and adopts the BIO annotation scheme. Taking English as its primary language, the dataset is split into training, validation and test sets with a ratio of 80%, 10% and 10% respectively. Each sentence consists of a sequence of words and their corresponding BIO tags.
创建时间:
2025-08-06
原始信息汇总
MedMentions BioNER (Custom Processed) 数据集概述
数据集基本信息
- 任务类型: 生物医学命名实体识别(NER)
- 数据来源: MedMentions
- 语言: 英语
- 实体类型: 128个基于UMLS语义类型的实体类别
- 标注格式: BIO标记方案
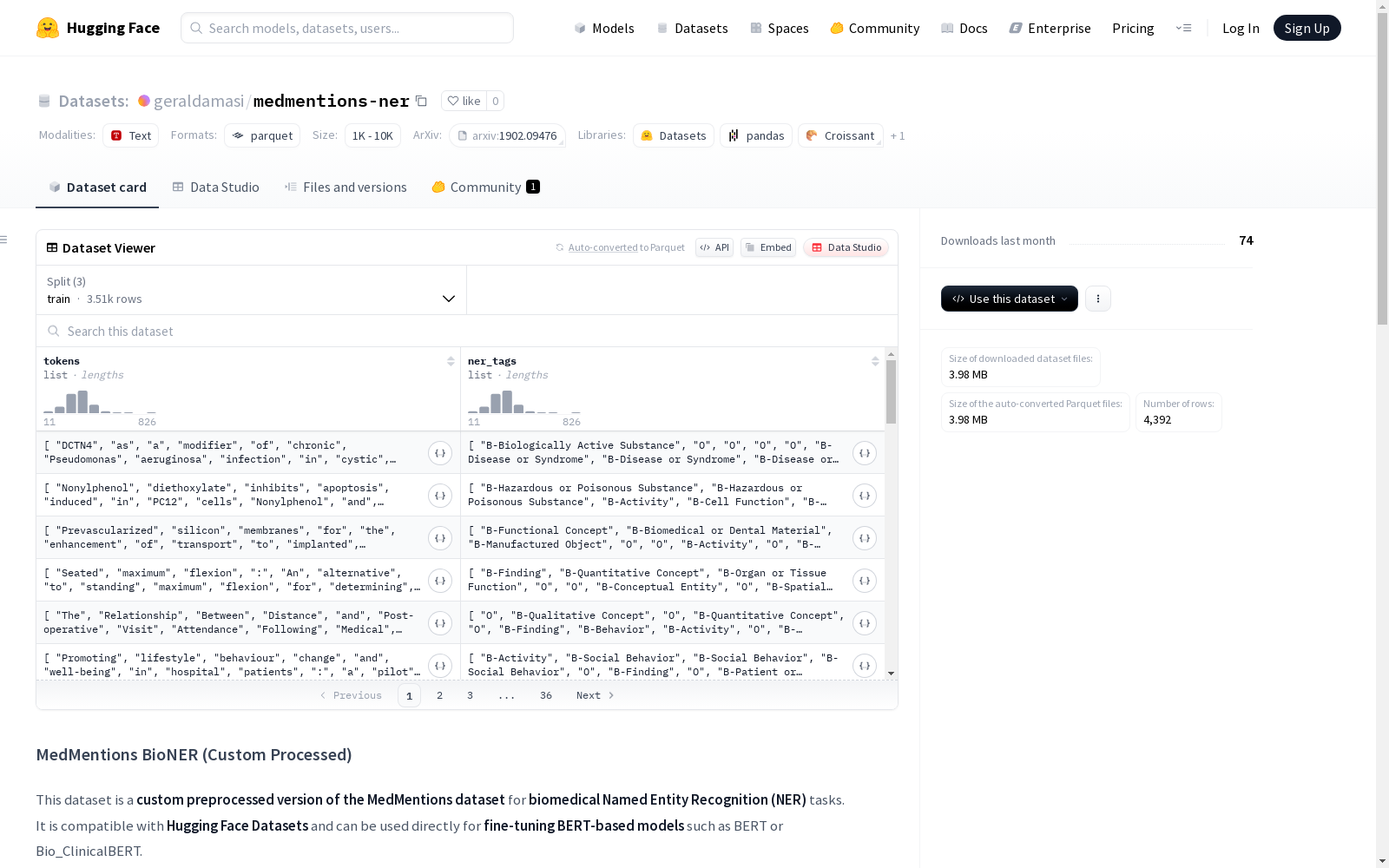
数据集结构
-
特征列:
tokens: 句子中的单词列表ner_tags: 每个单词对应的BIO格式标签列表
-
数据划分:
train: 3513个样本(80%)validation: 439个样本(10%)test: 440个样本(10%)
数据示例
json { "tokens": ["DCTN4", "as", "a", "modifier", "of", "chronic", "Pseudomonas", "aeruginosa", "infection"], "ner_tags": ["B-Biologically Active Substance", "O", "O", "O", "O", "B-Disease or Syndrome", "B-Disease or Syndrome", "B-Disease or Syndrome", "B-Disease or Syndrome"] }
技术规格
- 总大小: 25,924,360字节
- 下载大小: 3,982,978字节
- 兼容性: 可直接用于Hugging Face Datasets,适合微调BERT类模型(如BERT或Bio_ClinicalBERT)
引用信息
bibtex @article{medmentions, title={MedMentions: A Large Biomedical Annotated Corpus with UMLS Concepts}, author={Mohan, Sunil and Li, Donghui}, journal={arXiv preprint arXiv:1902.09476}, year={2019} }
搜集汇总
数据集介绍
构建方式
MedMentions NER数据集是基于MedMentions原始语料库精心构建的生物医学命名实体识别资源。该数据集采用专业标注流程,从PubMed摘要中提取文本片段,并由领域专家根据统一医学语言系统(UMLS)的128种语义类型进行实体标注。标注过程严格遵循BIO标注方案,确保实体边界的精确划分。数据经过标准化处理后被划分为训练集(80%)、验证集(10%)和测试集(10%)三个部分,为模型开发提供完整的评估框架。
特点
该数据集最显著的特点是覆盖了广泛的生物医学实体类型,包含从分子物质到临床诊断的128种UMLS语义类别。每个样本由token序列和对应的BIO标签序列组成,支持序列标注任务的端到端训练。数据来源于真实的生物医学文献,具有专业性强、语义复杂度高的特点。特别值得注意的是,该版本经过定制化预处理,与Hugging Face生态系统完美兼容,可直接用于BERT等预训练模型的微调。
使用方法
研究人员可通过Hugging Face Datasets库直接加载该数据集,其标准化的接口设计支持开箱即用的模型训练。典型使用流程包括:使用AutoTokenizer对文本进行编码,将BIO标签转换为数字ID,然后输入BERT类模型进行微调。数据集内置的训练-验证-测试划分方案便于进行模型性能评估。对于生物医学领域的迁移学习研究,建议结合Bio_ClinicalBERT等专业预训练模型,以充分利用领域特定的语义表示。
背景与挑战
背景概述
MedMentions-NER数据集由Sunil Mohan和Donghui Li于2019年创建,旨在推动生物医学命名实体识别(NER)领域的研究。该数据集基于统一医学语言系统(UMLS)的128个语义类型,构建了一个大规模的生物医学标注语料库。作为生物医学自然语言处理的重要资源,MedMentions-NER为研究人员提供了丰富的实体标注信息,显著提升了生物医学文本挖掘的精度和效率。该数据集的发布填补了生物医学领域高质量标注数据的空白,对临床决策支持系统和生物医学知识图谱构建产生了深远影响。
当前挑战
MedMentions-NER数据集面临的核心挑战在于生物医学文本的复杂性和多样性。生物医学术语具有高度的专业性和多义性,使得实体边界的确定和类别标注变得尤为困难。数据构建过程中,研究人员需要处理大量非结构化文本,并确保标注的一致性和准确性。此外,UMLS语义类型的广泛覆盖虽然提升了数据集的全面性,但也增加了标注的复杂度和时间成本。这些挑战要求标注者具备专业的生物医学知识,并采用严格的标注规范,以保证数据集的质量和可靠性。
常用场景
经典使用场景
在生物医学文本挖掘领域,medmentions-ner数据集被广泛用于训练和评估命名实体识别(NER)模型。该数据集包含丰富的生物医学术语和实体标注,特别适合用于研究如何从复杂的医学文献中自动识别和分类生物医学实体。研究人员通常利用该数据集来测试深度学习模型在生物医学NER任务上的性能,尤其是在处理多类别实体识别时的表现。
衍生相关工作
medmentions-ner数据集衍生了许多经典工作,尤其是在生物医学NER模型的优化和应用方面。例如,研究人员利用该数据集开发了基于BERT和Bio_ClinicalBERT的预训练模型,显著提升了生物医学实体识别的准确率。此外,该数据集还被用于研究跨领域实体识别和迁移学习,推动了生物医学自然语言处理技术的进步。
数据集最近研究
最新研究方向
在生物医学信息抽取领域,MedMentions-ner数据集作为基于UMLS语义类型的标注资源,近期研究聚焦于多模态实体识别与跨领域知识迁移。随着预训练语言模型在生物医学文本处理中的深入应用,该数据集被广泛用于探索领域自适应方法,特别是在临床术语消歧和罕见疾病实体链接方面表现出显著价值。研究者们正尝试将图神经网络与注意力机制相结合,以解决生物医学实体间的长距离依赖问题,同时该数据集也为评估大语言模型在细粒度医学概念识别中的零样本能力提供了基准平台。
以上内容由遇见数据集搜集并总结生成


