Multimodal-Fatima/cvasnlp_sample_test_augmented
收藏Hugging Face2023-06-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Multimodal-Fatima/cvasnlp_sample_test_augmented
下载链接
链接失效反馈官方服务:
资源简介:
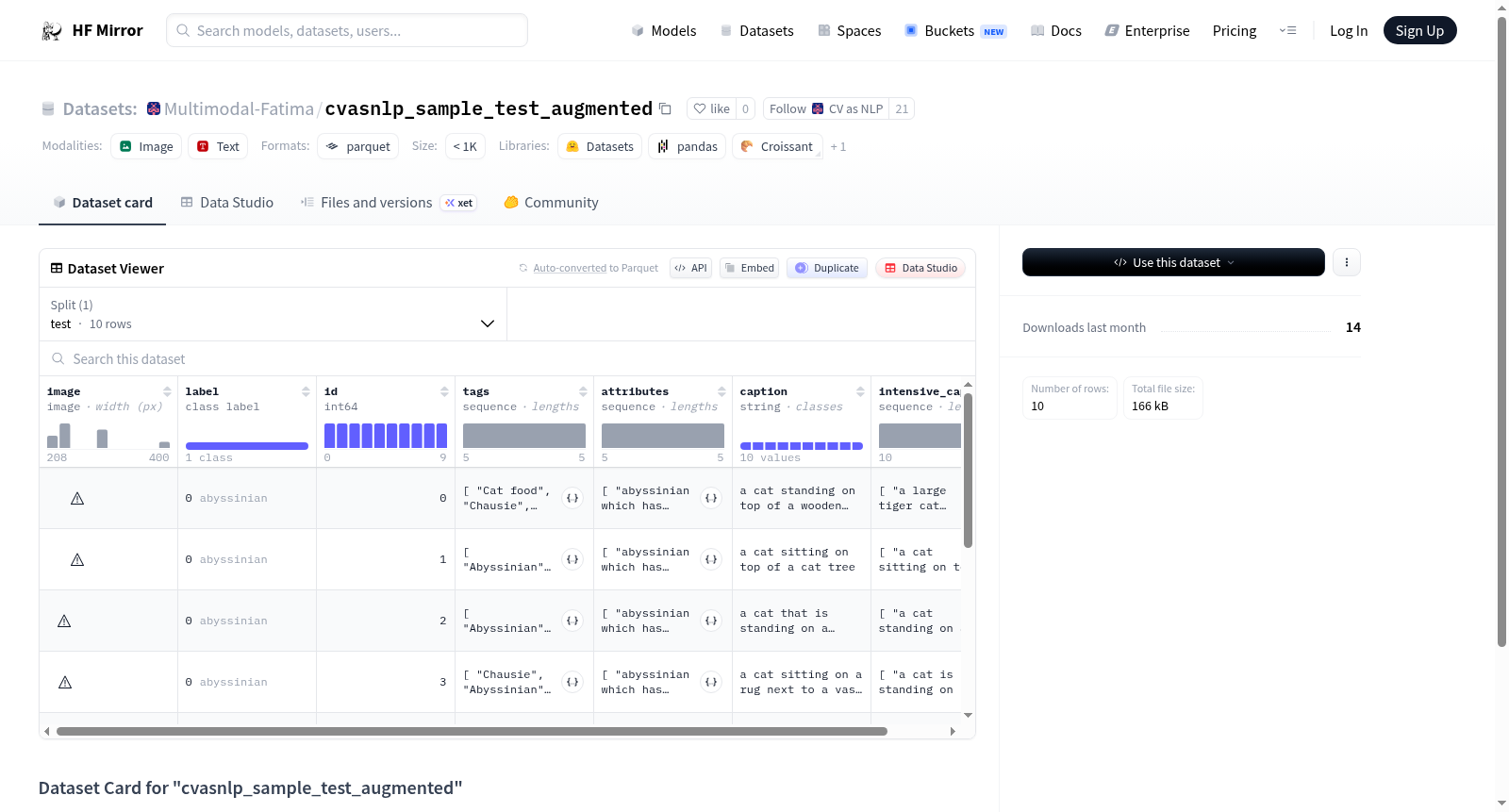
该数据集包含图像及其对应的标签、ID、标签、属性、标题和详细标题。标签部分详细列出了37种不同的类别,主要涉及猫和狗的品种。数据集分为一个测试集,包含10个样本,总大小为183727字节。
该数据集包含图像及其对应的标签、ID、标签、属性、标题和详细标题。标签部分详细列出了37种不同的类别,主要涉及猫和狗的品种。数据集分为一个测试集,包含10个样本,总大小为183727字节。
提供机构:
Multimodal-Fatima
原始信息汇总
数据集概述
数据集名称
cvasnlp_sample_test_augmented
数据集特征
- image: 图像数据
- label: 分类标签,包含以下类别:
- 0: abyssinian
- 1: american bulldog
- 2: american pit bull terrier
- 3: basset hound
- 4: beagle
- 5: bengal
- 6: birman
- 7: bombay
- 8: boxer
- 9: british shorthair
- 10: chihuahua
- 11: egyptian mau
- 12: english cocker spaniel
- 13: english setter
- 14: german shorthaired
- 15: great pyrenees
- 16: havanese
- 17: japanese chin
- 18: keeshond
- 19: leonberger
- 20: maine coon
- 21: miniature pinscher
- 22: newfoundland
- 23: persian
- 24: pomeranian
- 25: pug
- 26: ragdoll
- 27: russian blue
- 28: saint bernard
- 29: samoyed
- 30: scottish terrier
- 31: shiba inu
- 32: siamese
- 33: sphynx
- 34: staffordshire bull terrier
- 35: wheaten terrier
- 36: yorkshire terrier
- id: 整数类型
- tags: 字符串序列
- attributes: 字符串序列
- caption: 字符串类型
- intensive_captions: 字符串序列
数据集分割
- test:
- 数据量: 183727.0 字节
- 示例数量: 10
数据集大小
- 下载大小: 162139 字节
- 数据集大小: 183727.0 字节
搜集汇总
数据集介绍
构建方式
在计算机视觉与自然语言处理的交叉领域,数据集的构建需兼顾图像与文本的协同标注。本数据集通过精选涵盖37个不同品种的猫狗图像,为每幅图像赋予精细的类别标签,并辅以多层次的文本描述,包括常规标注、属性序列及密集描述。其构建过程注重样本的多样性与标注的丰富性,旨在为多模态学习任务提供结构化的测试基准。
特点
该数据集的核心特征在于其多模态数据的深度融合,不仅包含高分辨率的动物图像,还整合了类别标签、属性标签、常规描述与密集描述等多重文本信息。这种设计使得数据集能够支持从图像分类到细粒度视觉描述生成等多种任务。数据集中涵盖的品种范围广泛,从阿比西尼亚猫到约克夏梗犬,确保了样本的多样性与代表性,为模型评估提供了坚实的基准。
使用方法
在应用层面,本数据集适用于多模态机器学习模型的训练与评估,特别是在视觉语言理解与生成任务中。研究人员可加载图像与对应的文本字段,利用其丰富的标注信息进行监督学习或零样本评估。数据集以标准化的分割形式提供,便于直接集成至现有训练流程,支持图像分类、属性识别、图像描述生成等下游任务的性能验证。
背景与挑战
背景概述
在计算机视觉与自然语言处理融合的跨模态研究浪潮中,Multimodal-Fatima/cvasnlp_sample_test_augmented数据集应运而生。该数据集由Multimodal-Fatima团队构建,旨在应对细粒度视觉分类与图像描述生成的双重挑战。其核心研究问题聚焦于如何通过丰富的多模态标注——包括图像、类别标签、属性标签及密集描述——来提升模型对特定对象(如猫狗品种)的识别与理解能力。此类数据集的构建,为推进细粒度视觉-语言联合建模提供了关键资源,对促进自动驾驶、智能医疗等领域的多模态应用具有潜在影响力。
当前挑战
该数据集致力于解决细粒度视觉分类与图像描述生成这一复杂领域问题,其挑战在于模型需精准区分外观高度相似的类别(如不同犬种或猫种),并生成与视觉细节高度一致的文本描述。在构建过程中,挑战同样显著:一是获取大规模、高质量的细粒度标注数据成本高昂,需要领域专家进行精确识别;二是确保多模态标注(如密集描述与属性标签)之间的一致性与完整性,避免标注噪声;三是数据增强策略需在扩充样本多样性的同时,保持原始数据的语义真实性,这对技术方法提出了较高要求。
常用场景
经典使用场景
在计算机视觉与自然语言处理的交叉领域,Multimodal-Fatima/cvasnlp_sample_test_augmented数据集以其丰富的多模态标注结构,为细粒度图像分类任务提供了经典范例。该数据集整合了图像、标签、属性描述及密集字幕,使得研究者能够深入探索视觉特征与文本语义之间的关联性,尤其在宠物品种识别这类需要精细视觉辨别的场景中,成为评估模型跨模态理解能力的基准工具。
衍生相关工作
围绕该数据集,已衍生出一系列经典研究工作,主要集中在多模态预训练模型的微调与评估上。例如,基于CLIP、ALIGN等架构的跨模态检索模型常利用此类数据进行领域适应性训练,以提升细粒度分类性能。同时,它在视觉语言导航的仿真环境构建、以及少样本学习策略的验证中也扮演重要角色,促进了如ViLBERT、UNITER等模型在具体垂直领域的应用与优化。
数据集最近研究
最新研究方向
在计算机视觉与自然语言处理的交叉领域,多模态数据集正成为推动智能系统发展的核心资源。Multimodal-Fatima/cvasnlp_sample_test_augmented数据集以其丰富的图像标注和细粒度分类标签,为宠物识别与描述任务提供了关键基准。当前研究聚焦于利用该数据集探索视觉-语言联合建模的前沿方法,特别是在零样本学习与少样本场景下的泛化能力提升。随着生成式人工智能的兴起,该数据集被广泛应用于图像描述生成、属性推理及跨模态检索等热点方向,显著促进了多模态理解技术在智能宠物护理、动物保护等实际场景中的落地应用。其精细的类别划分与密集标注结构,为模型可解释性与鲁棒性研究提供了重要支撑,推动了领域向更高效、更人性化的交互系统演进。
以上内容由遇见数据集搜集并总结生成


