erhwenkuo/poetry-chinese-zhtw
收藏Hugging Face2023-10-16 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/erhwenkuo/poetry-chinese-zhtw
下载链接
链接失效反馈官方服务:
资源简介:
中文古典文集資料庫收集了約 5.5 萬首唐詩、26 萬首宋詩、2.1 萬首宋詞和其他古典文集。詩人包括唐宋兩朝近 1.4 萬古詩人,和兩宋時期 1.5 千古詞人。資料集涵蓋了五代十國、唐、宋、元、清等朝代的詩歌和詞作,具體包括花間集、南唐二主詞、全唐詩、全宋詞、元曲和納蘭性德詩集。每個數據條目包含作者、作品名稱、文章內容和作品所屬的朝代。
The Chinese classical literature dataset contains approximately 55,000 Tang poems, 260,000 Song poems, 21,000 Song lyrics, and other classical literature works. The poets include nearly 14,000 ancient poets from the Tang and Song dynasties, and 1,500 ancient lyricists from the Song period. The dataset includes works from the Five Dynasties and Ten Kingdoms such as Hua Jian Ji and Nan Tang Er Zhu Ci, Tang Dynastys Quan Tang Shi, Song Dynastys Quan Song Ci, Yuan Dynastys Yuan qu, and Qing Dynastys Na Lan Xing De Shi Ji. The dataset structure includes fields such as author, title, text, and category, facilitating model training and usage.
提供机构:
erhwenkuo
原始信息汇总
数据集卡片 "poetry-chinese-zhtw"
数据集摘要
中文古典文集数据库收集了约 5.5 万首唐诗、26 万首宋诗、2.1 万首宋词和其他古典文集。诗人包括唐宋两朝近 1.4 万古诗人和两宋时期 1.5 千古词人。
- 五代十国 - 收录"花间集"与"南唐二主词"
- 唐 - 收录"全唐诗"(是清康熙四十四年,康熙皇帝主导下,搜集罗唐诗的收藏「得诗 48,900 余首,诗人 2,200 人」)。
- 宋 - 收录"全宋词"(由唐圭璋编著,孔凡礼补辑,共收录宋代词人 1,330 家,词作 21,116 首)。
- 元 - 收录元曲 11,057 篇,曲家 233 人。
- 清 - 收录"纳兰性德诗集"
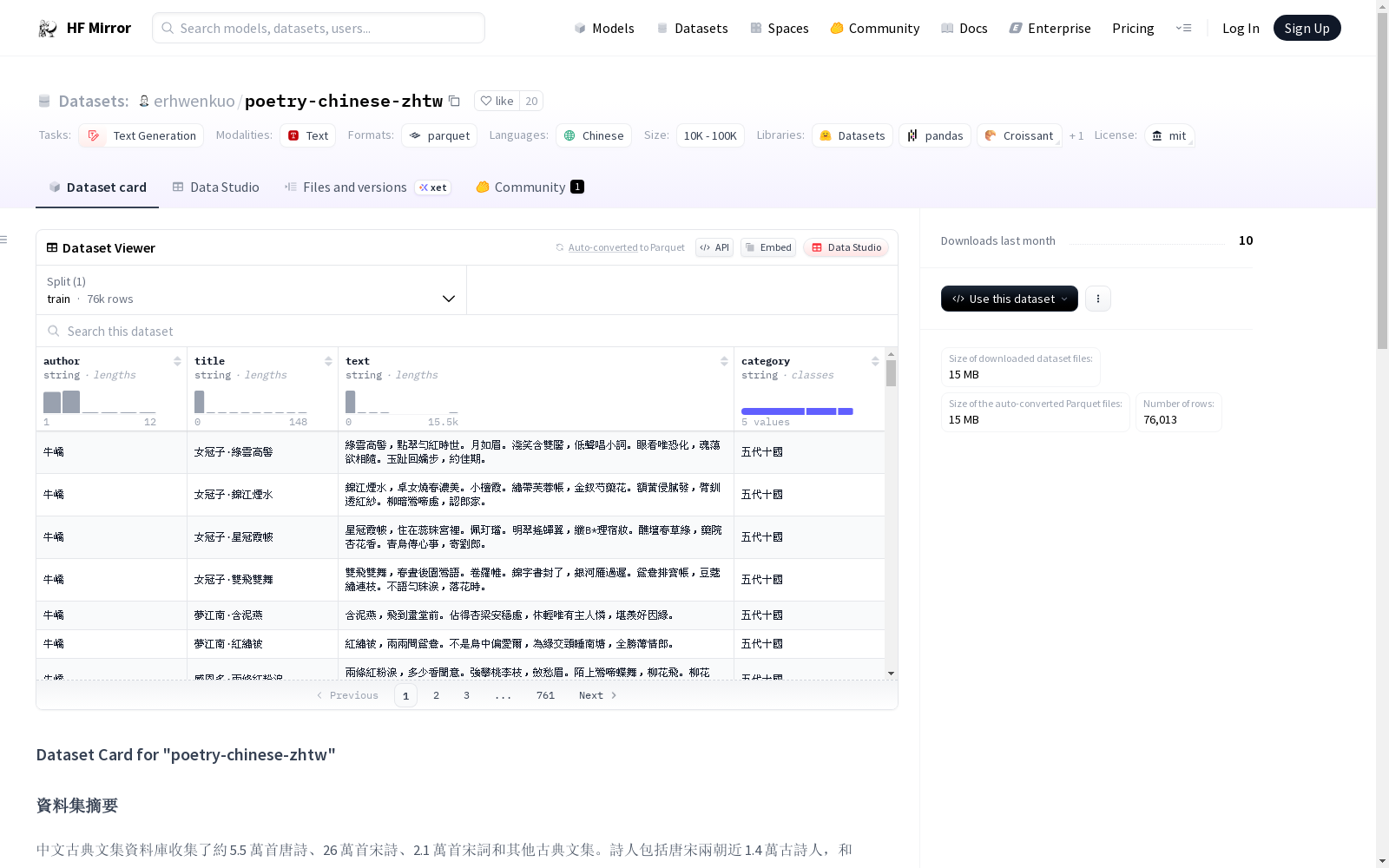
数据集结构
json { "author": "杜甫", "title": "月", "text": "天上秋期近,人间月影清。入河蟾不没,捣药兔长生。只益丹心苦,能添白发明。干戈知满地,休照国西营。", "category": "唐" }
数据字段
author: (string) 作者title: (string) 作品名称text: (string) 文章内容category: (string) 作品的朝代
许可信息
搜集汇总
数据集介绍
构建方式
該數據集的构建採用了對中文古典文集進行整合與清洗的方式,從原始的[chinese-poetry: 最全中文诗歌古典文集数据库]中匯集了包括唐詩、宋詩、宋詞以及元曲等在内的大量古典文學作品,並利用OpenCC進行簡繁轉換以適應不同的文本處理需求,最終通過Huggingface Datasets框架構建而成。
特点
該數據集的特色在於其涵蓋了從唐至清時期的豐富詩歌資源,包括近5.5萬首唐詩、26萬首宋詩等,並對應了詩人、作品名稱、文本內容以及作品朝代等維度的信息。此外,數據集遵循MIT許可,保證了使用的自由度。
使用方法
使用此數據集時,用户可通過Huggingface提供的load_dataset函數加載數據集,並選擇所需的split(如train),便可獲得相應的數據。數據以JSON格式存儲,包含了作者、標題、文本和類別等字段,方便進行後續的文本分析和模型訓練等操作。
背景与挑战
背景概述
在自然语言处理与文学研究领域,诗歌数据的收集与分析具有重要意义。该数据集名为“erhwenkuo/poetry-chinese-zhtw”,是在康熙皇帝主导下搜集整理的唐宋诗词,以及元、清两代的文学作品的基础上构建而成。收录了约5.5万首唐诗、26万首宋诗、2.1万首宋词等,涵盖唐宋两朝近1.4万古诗人和两宋时期1.5千古词人的作品,为研究古代文学和诗词风格提供了丰富的资源。该数据集的创建,不仅保存了古典文学的珍贵资料,也为文学研究者和自然语言处理技术人员提供了文本生成、风格模拟等研究的基础数据。
当前挑战
该数据集在构建过程中面临的挑战包括:一是确保文献资料的完整性与准确性,对历史文献进行数字化处理和简繁转换,保证数据的可靠性;二是数据集的规模庞大,对数据结构的调整、清洗和格式化处理要求高;三是针对诗词特有的韵律和格式,如何有效提取特征并构建适用于机器学习模型的格式,是数据预处理中的关键挑战。此外,该数据集在解决领域问题如文本生成、文学风格分析等方面,还需克服如何更准确捕捉和复现古代文学韵味的难题。
常用场景
经典使用场景
在自然语言处理领域,erhwenkuo/poetry-chinese-zhtw数据集的古典文学作品,常被用于文本生成与风格模仿的研究。其丰富的文本内容,使得研究者能够训练模型以生成具有古风特色的文本,进而用于创作或文本分析。
解决学术问题
该数据集解决了古诗文文本资源匮乏的问题,为研究者和开发者提供了大量的唐宋诗词及古典文献,有助于推动文本挖掘、情感分析、文学风格识别等学术研究的进展,对于深入理解古典文学作品的风格与结构具有显著意义。
衍生相关工作
基于该数据集,衍生出了多项研究工作,包括但不限于风格迁移、文学风格识别、情感分析等。这些研究不仅拓宽了古典文学的研究视角,也为自然语言处理领域带来了新的研究思路和方法论。
以上内容由遇见数据集搜集并总结生成


