FOMO-MRI/FOMO260K
收藏Hugging Face2026-05-06 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/FOMO-MRI/FOMO260K
下载链接
链接失效反馈官方服务:
资源简介:
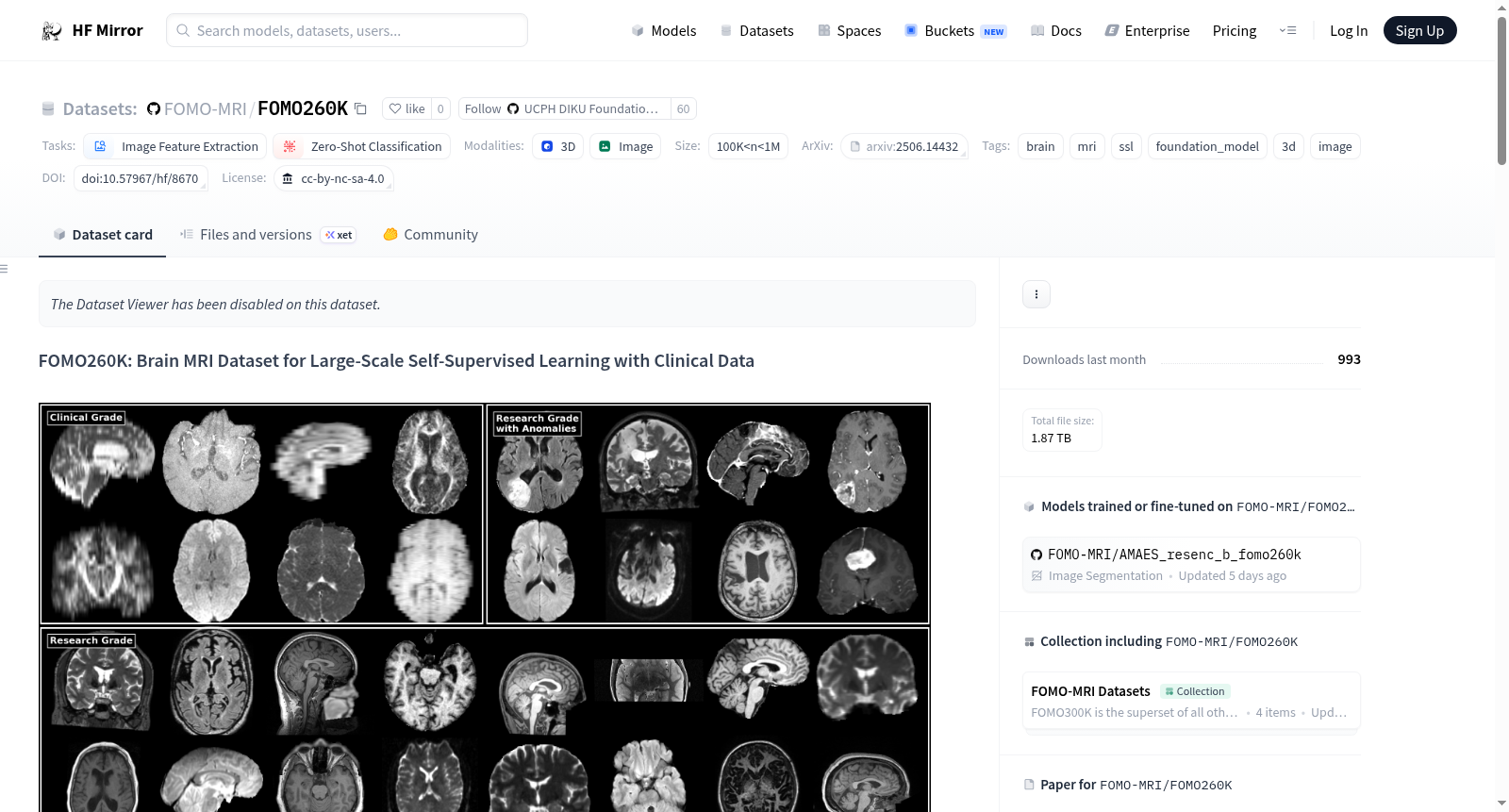
FOMO260K是一个大规模的大脑MRI扫描数据集,包括临床和研究级扫描,涵盖了多种序列,如T1、MPRAGE、T2、T2*、FLAIR、SWI、T1c、PD、DWI、ADC等。数据集包含55,378名受试者、77,589次会话和260,927次扫描。该数据集是OpenMind和FOMO45K的超集。数据以NIfTI文件格式提供,并遵循略微修改的BIDS格式。数据集还包括参与者信息、文件映射和MRI采集信息等元数据文件。
FOMO260K is a large-scale dataset of brain MRI scans, including both clinical and research-grade scans. The dataset includes a wide range of sequences, including T1, MPRAGE, T2, T2*, FLAIR, SWI, T1c, PD, DWI, ADC, and more. The dataset consists of 55,378 subjects, 77,589 sessions, and 260,927 scans. It is a superset of both OpenMind and FOMO45K. The data is provided as NIfTI-files and follows a slightly modified version of the BIDS format. The dataset includes metadata files such as participants.tsv, mapping.tsv, and mri_info.tsv.
提供机构:
FOMO-MRI
搜集汇总
数据集介绍
构建方式
FOMO260K是一个大规模脑部磁共振成像数据集,涵盖了临床与研究两大来源的扫描数据。其数据来源于多种机构,整合了T1、MPRAGE、T2、T2*、FLAIR、SWI、T1c、PD、DWI、ADC等多种序列,共计260,927次扫描,来自55,378名受试者与77,589次独立检查。数据集遵循改良版BIDS格式存储,所有数据以NIfTI文件形式组织,并附有参与者信息、原始数据映射及MRI采集参数等元数据表格,便于研究者索引与使用。作为FOMO-MRI系列的一部分,FOMO260K是FOMO300K的开放获取子集,其构建旨在兼顾规模与可访问性,为自监督学习提供丰富而多样的图像素材。
特点
该数据集的核心特点在于其异质性与临床代表性。与同类数据集相比,FOMO260K纳入了更多低分辨率、高切片厚度的临床级扫描,更真实地反映了实际医疗场景中的图像质量与病变多样性。尤其值得一提的是,其在肿瘤类疾病上的数据量显著高于其他公开脑MRI数据集,为针对肿瘤的模型训练提供了宝贵资源。此外,FOMO260K采用宽松的CC-BY-NC-SA许可协议,无需申请即可下载,降低了使用门槛,促进了跨机构、跨领域的合作研究。
使用方法
研究者可通过HuggingFace平台直接访问并下载FOMO260K完整数据。数据以NIfTI格式存储,适配主流医学影像处理工具如NiBabel、ANTsPy和MONAI。建议利用其元数据文件(participants.tsv、mapping.tsv、mri_info.tsv)筛选特定序列、疾病类型或人口学特征的子集,进行下游任务微调或自监督预训练。由于该数据集是FOMO300K的子集,使用时应注意避免与其他FOMO-MRI集合合并,以防数据重复。引用时需标注原始论文,并遵守各组成数据集的归属要求。
背景与挑战
背景概述
FOMO260K是一种大规模脑部MRI数据集,由Stefano Cerri、Asbjørn Munk等研究人员于2026年创建,旨在推动三维磁共振脑影像的自监督学习研究。该数据集整合了来自临床和研究场景的55,378名受试者、77,589次扫描会话及260,927幅扫描图像,覆盖T1、MPRAGE、T2、FLAIR、DWI等多种序列并以NIfTI格式存储。作为OpenMind和FOMO45K的超集,FOMO260K提供了基于CC-BY-NC-SA许可的开放访问,为脑部基础模型与零样本分类任务奠定了大规模、异质性的数据基石,显著增强了医学影像领域对现实临床复杂性的表征能力。
当前挑战
该数据集面临的挑战主要集中于两个层面。在领域问题方面,传统脑部MRI数据集普遍规模小、来源单一,限制了自监督学习模型在异质性临床环境中的泛化能力,而FOMO260K需要通过整合来自不同机构、扫描仪和诊断组的多样化扫描来弥补这一缺口。在构建过程中,数据处理涉及大规模的格式标准化(如BIDS规范适配)、缺失序列信息的元数据标记,以及确保开放许可下不侵犯原始数据使用协议,尤其需要平衡数据开放性与隐私合规要求。此外,不同子数据集(如FOMO50K、FOMO300K)间的去重处理也构成了技术上的复杂性挑战。
常用场景
经典使用场景
FOMO260K作为一项大规模、多序列的三维脑磁共振影像数据集,在自监督学习与医学影像基础模型预训练领域展现出无与伦比的经典应用价值。它汇聚了来自五万余名受试者的逾二十六万次扫描,囊括T1、T2、FLAIR、DWI、ADC等丰富成像序列,覆盖从科研级到临床级的多样化数据质量。这一体量庞大且异质性极高的数据集合,为训练鲁棒性强、泛化能力优异的3D视觉表征模型提供了理想的数据基石,特别适用于无需昂贵标注信息即可从海量未标记脑部MRI中学习深层解剖与病理特征的自监督学习框架,有力推动了医学影像基础模型从理论走向实践的关键步伐。
衍生相关工作
围绕FOMO260K衍生出的一系列经典工作充分彰显了其学术影响力。该数据集本身作为FOMO-MRI系列的核心成员,与FOMO300K、FOMO50K等构成了层次化的开放医学影像资源谱系,为不同权限与预处理需求的研究提供了灵活选择。基于此数据集,研究者们相继提出了多种面向3D医学影像的自监督预训练框架,例如基于掩码图像重建、对比学习与多任务联合学习的模型架构。此外,FOMO260K还催生了关于脑部疾病泛化性诊断、跨中心域适应及临床级数据与科研级数据联合分析等一系列后续研究,极大地丰富了医学影像分析领域的方法论体系,并成为验证新模型性能不可或缺的基准平台。
数据集最近研究
最新研究方向
FOMO260K作为目前公开可获取的规模最大的异质性三维脑部磁共振影像数据集之一,其核心前沿方向聚焦于推动自监督学习与基础模型在医学影像领域的突破性应用。该数据集汇聚了超过55,000名受试者的26万次扫描,涵盖从临床常规序列到科研级成像的多种模态,尤其包含大量临床实践中常见的低分辨率影像与多种神经系统疾病样本,为训练具备强大泛化能力的医学影像基础模型提供了前所未有的数据支撑。在自监督学习框架下,这一异构大数据的涌现有望显著提升模型对复杂病理特征的识别能力,并驱动零样本疾病分类、跨模态特征提取等热点任务的落地,从而加速脑疾病智能诊断与精准医疗的发展进程。
以上内容由遇见数据集搜集并总结生成


