HuggingFaceFW/fineweb-edu
收藏Hugging Face2025-07-11 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/HuggingFaceFW/fineweb-edu
下载链接
链接失效反馈官方服务:
资源简介:
FineWeb-Edu数据集是从FineWeb数据集中筛选出的教育类网页内容,包含1.3万亿个token。通过使用LLama3-70B-Instruct生成的注释训练了一个教育质量分类器,筛选出高质量的教育内容。该数据集旨在为语言模型训练提供高质量的教育数据。
The FineWeb-Edu dataset is a curated subset of educational web content filtered from the FineWeb dataset, containing 1.3 trillion tokens. An educational quality classifier was trained using annotations generated by Llama3-70B-Instruct to screen out high-quality educational content. This dataset aims to provide high-quality educational data for language model training.
提供机构:
HuggingFaceFW
原始信息汇总
数据集概述
基本信息
- 许可证: odc-by
- 任务类别: 文本生成
- 语言: 英语
- 数据集名称: FineWeb-Edu
- 数据大小: 超过1万亿个令牌
数据配置
- 默认配置: 包含所有数据
- 路径:
data/*/*
- 路径:
- 样本配置:
sample-350BT: 约3500亿个gpt2令牌的随机子集- 路径:
sample/350BT/*
- 路径:
sample-100BT: 约1000亿个gpt2令牌的随机子集- 路径:
sample/100BT/*
- 路径:
sample-10BT: 约100亿个gpt2令牌的随机子集- 路径:
sample/10BT/*
- 路径:
- 特定抓取配置:
CC-MAIN-2024-10至CC-MAIN-2013-20等,每个配置对应一个特定的抓取周期- 路径格式:
data/CC-MAIN-(year)-(week number)/*
- 路径格式:
数据集加载
-
使用
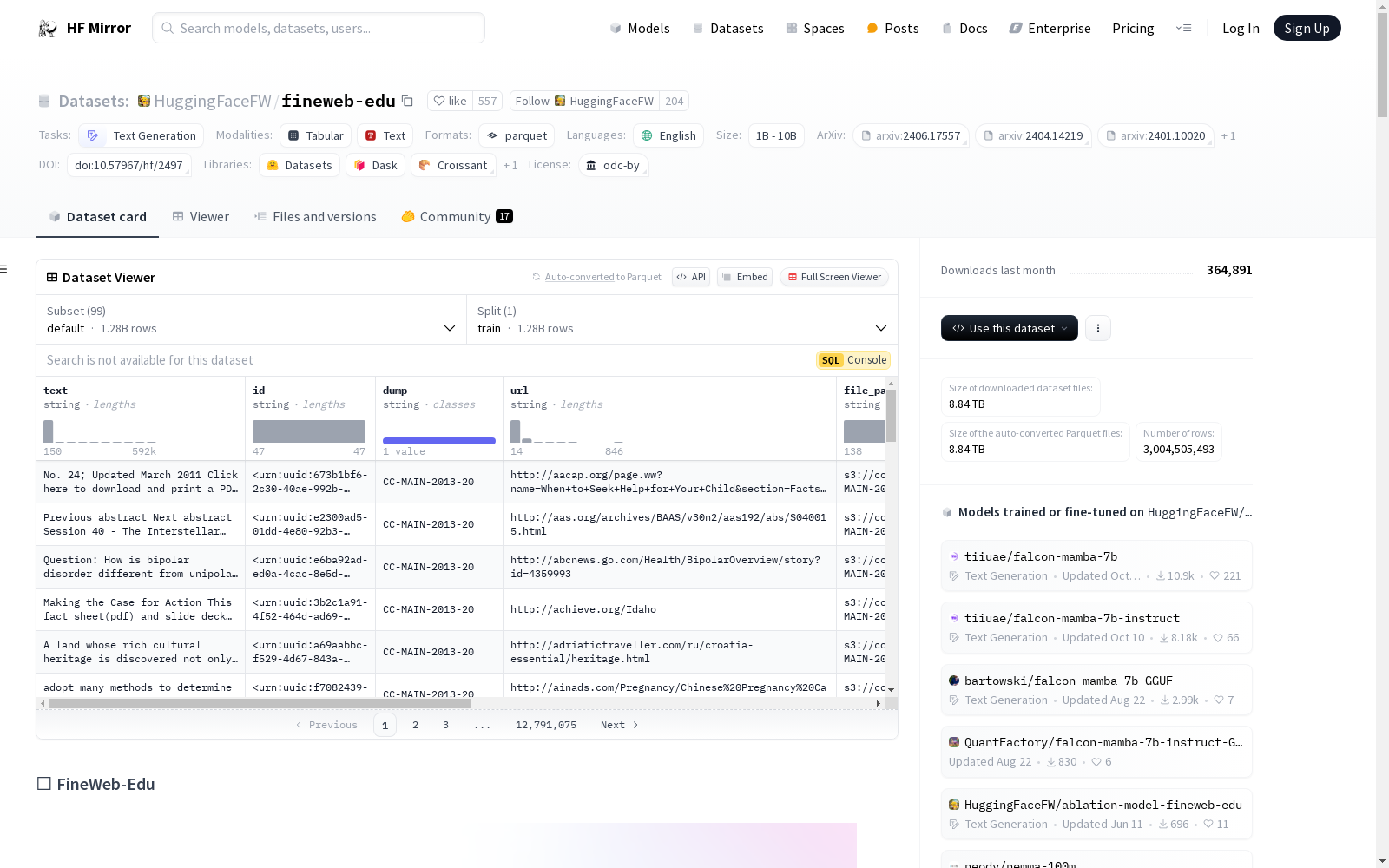
datatrove: python from datatrove.pipeline.readers import ParquetReaderdata_reader = ParquetReader("hf://datasets/HuggingFaceFW/fineweb-edu", glob_pattern="data//.parquet", limit=1000) for document in data_reader(): print(document)
-
使用
datasets: python from datasets import load_dataset fw = load_dataset("HuggingFaceFW/fineweb-edu", name="CC-MAIN-2024-10", split="train", streaming=True)
数据集创建
- 分类器训练: 使用LLama3-70B-Instruct生成的注释训练教育质量分类器
- 过滤和结果: 通过设置阈值3过滤数据,保留1.3万亿个教育令牌
数据集版本
- FineWeb-Edu: 1.3万亿个令牌
- FineWeb-Edu-score-2: 5.4万亿个令牌(阈值2)
分类器
搜集汇总
数据集介绍
构建方式
FineWeb-Edu数据集的构建基于FineWeb数据集,通过使用由LLama3-70B-Instruct生成的注释开发的教育质量分类器进行筛选。该分类器对FineWeb中的网页进行评分,保留教育质量较高的网页,最终形成包含1.3万亿标记的教育数据集。此过程涉及对50万样本的评分,并使用Bert-like回归模型进行微调,以实现对教育内容的有效分类。
使用方法
用户可以通过HuggingFace的`datasets`库或`datatrove`工具加载FineWeb-Edu数据集。加载时可以选择特定的配置,如`CC-MAIN-2024-10`或样本子集`sample-10BT`。数据集支持流式加载,便于处理大规模数据。此外,数据集还提供了分类器和训练代码,用户可以进一步定制和优化数据集的使用。
背景与挑战
背景概述
FineWeb-Edu数据集是由HuggingFaceFW团队开发的一个大规模教育内容数据集,包含1.3万亿个标记,源自经过筛选的FineWeb数据集。该数据集的核心研究问题是如何通过合成数据训练的分类器来提升教育内容的筛选质量,从而为大规模语言模型的训练提供更高质量的语料。FineWeb-Edu的创建时间可追溯至2024年,其主要研究人员和机构包括HuggingFaceFW团队,以及使用LLama3-70B-Instruct模型进行注释生成的Meta AI团队。该数据集的发布对教育内容筛选和语言模型训练领域具有重要影响,尤其是在提升模型在教育相关基准测试中的表现方面。
当前挑战
FineWeb-Edu数据集的构建过程中面临的主要挑战包括:首先,如何通过合成数据训练的分类器有效筛选出高质量的教育内容,这一过程需要大量的计算资源和时间,分类器的训练耗费了6000个H100 GPU小时。其次,数据集的筛选标准和阈值设定也是一个关键问题,不同的筛选阈值对模型性能的影响显著,尤其是在知识密集型和推理密集型基准测试中的表现。此外,数据集的构建还需要解决如何平衡教育内容的广度和深度,避免过度偏向某一特定教育层次的问题。这些挑战不仅影响了数据集的质量,也对后续模型的训练和应用提出了更高的要求。
常用场景
经典使用场景
FineWeb-Edu数据集的经典使用场景主要集中在教育内容的生成与优化。通过该数据集,研究者和开发者可以训练出能够生成高质量教育文本的模型,尤其适用于自动生成教材、课程内容或教育问答系统。其丰富的教育资源和高质量的过滤机制,使得模型在教育领域的应用表现尤为突出。
解决学术问题
FineWeb-Edu数据集解决了大规模教育数据筛选与质量提升的学术难题。传统的教育数据集往往包含大量噪声和低质量内容,而该数据集通过先进的分类器和合成数据技术,有效过滤出高质量的教育内容,显著提升了模型在教育相关任务中的表现。这一创新为教育领域的自然语言处理研究提供了新的方向。
实际应用
FineWeb-Edu数据集在实际应用中具有广泛的前景,尤其在教育科技领域。它可以用于构建智能教育助手、自动生成个性化学习材料、以及开发教育问答系统等。通过该数据集训练的模型能够更好地理解和生成教育内容,从而提升学习体验和教学效果。
数据集最近研究
最新研究方向
近年来,FineWeb-Edu数据集在教育内容过滤和分类领域取得了显著进展。通过利用合成数据训练的教育质量分类器,该数据集成功筛选出高质量的教育网页内容,显著提升了模型在教育相关基准测试中的表现。这一研究方向不仅推动了大规模语言模型训练数据的精细化处理,还为教育领域的智能化应用提供了有力支持。此外,FineWeb-Edu的发布也促进了教育内容分类技术的开放共享,为相关领域的研究者提供了宝贵的资源和工具。
以上内容由遇见数据集搜集并总结生成


