survey_social_value_th2025
收藏Hugging Face2025-03-26 更新2025-03-27 收录
下载链接:
https://huggingface.co/datasets/scb10x/survey_social_value_th2025
下载链接
链接失效反馈官方服务:
资源简介:
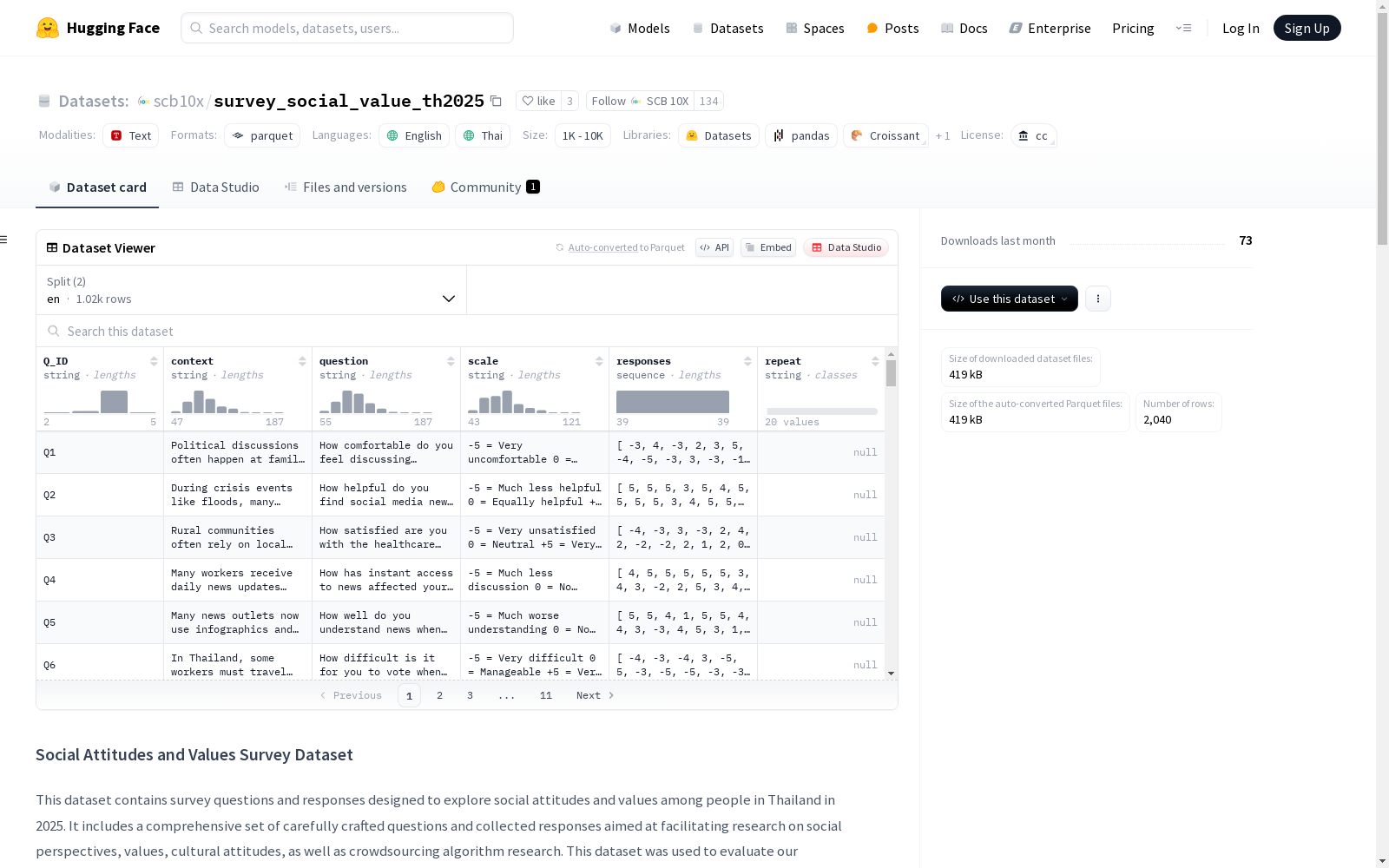
这是一个关于泰国人在2025年社会态度和价值观的调查数据集。数据集包含了精心设计的调查问题和收集到的响应,旨在促进对社会观点、价值观、文化态度以及众包算法研究的研究。数据集共有1,020个示例(其中20个问题重复用于质量控制),以英语(使用与泰国文化相关的内容)构建后翻译成泰语供泰国受访者回答。数据集分为两个部分:英语(en)和泰语(th)。每个数据点包括问题ID、上下文信息、问题、量表描述、39名工人的响应列表以及是否重复问题标识。
创建时间:
2025-03-14
原始信息汇总
数据集概述:Social Attitudes and Values Survey Dataset
数据集基本信息
- 数据集名称:Social Attitudes and Values Survey Dataset
- 数据集地址:https://huggingface.co/datasets/scb10x/survey_social_value_th2025
- 许可证:Creative Commons Attribution 4.0 International (CC BY 4.0)
- 语言:英语 (en)、泰语 (th)
- 大小分类:1K<n<10K
数据集结构
- 总大小:~1.7 MB
- 下载大小:~420 KB
- 示例数量:1,020
- 受访者数量:39
数据拆分
- 英语 (en):1,020 个示例
- 泰语 (th):1,020 个示例(翻译版本)
特征
Q_ID(string):每个问题的唯一标识符。context(string):每个问题提供的上下文信息。question(string):调查问题。scale(string):11点量表中-5、0、+5点的描述。responses(整数列表):从39名工作者收集的响应。repeat(string):指示问题是否重复用于质量控制。
数据集创建过程
问题生成
- 主题选择:从Pew Research Center获取420个初始主题,通过Claude 3.5 Sonnet模型评估,保留301个主题。
- 问题生成:每个主题生成10个调查问题,共3,010个初始问题。
- 问题细化:评估清晰度、相关性、准确性和量表描述的中立性,最终保留1,000个独特问题。
数据标注与收集
- 工作者标注:40名泰国标注者参与,通过Google Forms回答1,020个问题(1,000个独特问题+20个重复问题)。
- 质量控制:
- 限制零分响应低于10%。
- 包含重复问题以评估响应一致性。
- 排除不符合质量指南的标注者数据。
使用与应用
适用于以下研究领域:
- 众包算法
- 跨文化研究统计分析、意见挖掘等
引用
bibtex @inproceedings{your_paper_citation, title={Your Paper Title}, author={Authors}, booktitle={Conference or Journal}, year={Year} }
致谢
感谢Adisai Na-Thalang和Chanakan Wittayasakpan协助从受访者收集数据。
许可
本数据集采用Creative Commons Attribution 4.0 International (CC BY 4.0)许可。
搜集汇总
数据集介绍
构建方式
在社会科学研究领域,survey_social_value_th2025数据集的构建采用了多阶段严谨流程。研究团队首先从皮尤研究中心筛选420个初始主题,通过Claude 3.5 Sonnet模型评估后保留301个优质主题。基于这些主题,模型生成了3,010个初始问题,经过清晰度、相关性、准确性等多维度筛选,最终保留1,000个核心问题。数据采集阶段招募了40名泰国标注者,通过谷歌表单收集对1,020个问题的回答(含20个重复问题用于质量控制)。
特点
该数据集展现了独特的多维度特征设计。每个数据点包含问题ID、上下文背景、具体问题、11分量表描述以及39位标注者的响应序列。特别值得注意的是,数据集提供英语和泰语双语版本,其中泰语版本为实际调查所用译文。问题设计采用-5至+5的11点量表,并附有各极端值的文字描述,为研究者提供了丰富的语义信息。重复问题的设置则为数据质量评估提供了可靠依据。
使用方法
该数据集为跨学科研究提供了重要资源。在算法研究领域,适用于众包算法开发与评估;在社会科学方向,支持泰国社会价值观的统计分析、意见挖掘等研究。使用时可分别加载英语或泰语版本,通过Q_ID实现问题匹配。响应数据可直接用于一致性分析,重复问题字段则便于进行数据质量验证。研究引用时需遵循CC BY 4.0许可协议,并按规定格式标注原始论文。
背景与挑战
背景概述
survey_social_value_th2025数据集由泰国研究团队于2025年创建,旨在探究泰国社会态度与价值观的演变趋势。该数据集基于Pew Research Center的420个初始主题,通过Claude 3.5 Sonnet模型生成并筛选出1000个具有文化敏感性的调查问题。研究团队招募39名泰国受访者,采用11点量表(-5至+5)收集了涵盖社会观念、文化态度等维度的1020条有效数据。作为东南亚地区首个系统性的社会价值观调查数据集,其为跨文化研究、意见挖掘及众包算法开发提供了重要基准。
当前挑战
该数据集面临双重挑战:在研究层面,如何准确捕捉快速变迁的社会价值观动态特征成为核心难题,特别是量表设计中需平衡文化特异性与跨文化可比性;在构建层面,问题生成阶段需克服机器生成内容的文化适应性障碍,而数据收集过程中则面临受访者应答偏差控制(如零分响应限制)与标注一致性验证(通过20%重复问题)等操作挑战。此外,从40名初始受访者中剔除无效数据的质量控制过程也凸显了众包标注在社会科学研究中的方法论困境。
常用场景
经典使用场景
在社会科学研究领域,survey_social_value_th2025数据集为探索泰国社会态度与价值观提供了丰富的数据支持。该数据集通过精心设计的调查问题和收集的响应,广泛应用于社会视角、文化态度以及众包算法研究。研究者可利用该数据集进行大规模的社会调查分析,深入理解泰国社会在2025年的价值观变迁。
衍生相关工作
该数据集衍生了多项经典研究,特别是在众包算法和社会科学交叉领域。例如,研究者利用该数据集开发了新的众包数据质量控制算法,显著提高了调查数据的可靠性。此外,基于该数据集的跨文化研究也为理解泰国与其他国家的社会价值观差异提供了重要参考。
数据集最近研究
最新研究方向
近年来,随着全球化进程的加速和社会价值观的多元化,对跨文化社会态度和价值观念的研究日益受到学术界关注。survey_social_value_th2025数据集作为聚焦泰国社会价值观的前沿研究资源,其最新研究方向主要集中在两大领域:一方面,该数据集被广泛应用于众包算法优化研究,通过分析39名标注者对重复问题的响应模式,为提升众包数据质量评估模型提供了宝贵实验数据;另一方面,数据集独特的双语结构和文化适应性设计,使其成为跨文化比较研究的重要工具,特别是在东南亚社会价值观演变、人工智能伦理观念形成等热点议题中展现出独特价值。该数据集精心设计的11级量表体系和严格的质量控制流程,为社会科学量化研究提供了方法论参考,其应用已延伸至舆情分析、文化心理学等多个交叉学科领域。
以上内容由遇见数据集搜集并总结生成


