cmm-math
收藏Hugging Face2024-09-08 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/ecnu-icalk/cmm-math
下载链接
链接失效反馈资源简介:
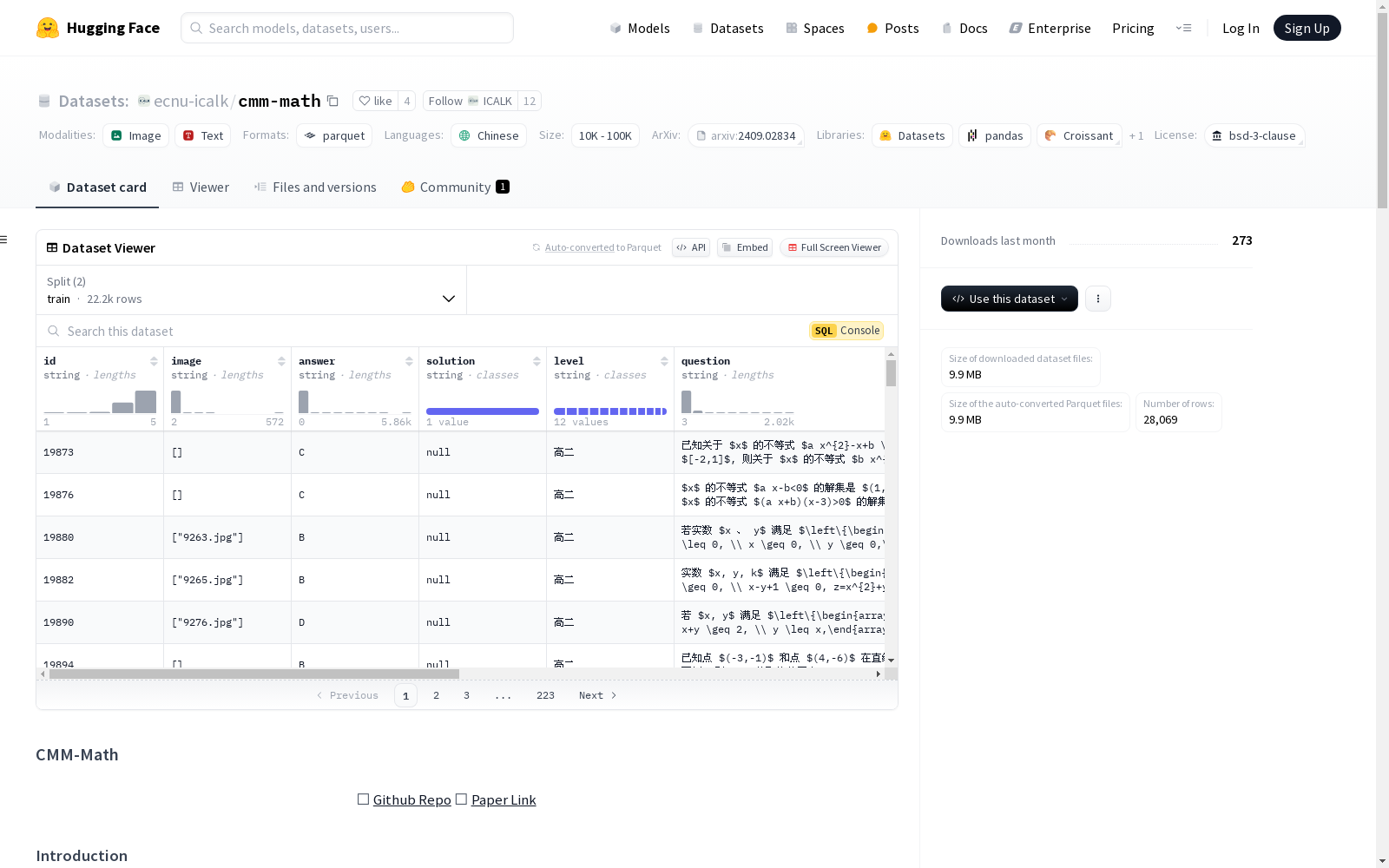
CMM-Math是一个中文多模态数学数据集,包含超过28,000个高质量样本,涵盖从小学到高中的12个年级,问题类型多样,包括选择题、填空题等,并附有详细的解答。数据集中的问题可能包含视觉上下文,使其更具挑战性。数据集分为训练部分和评估部分,分别包含22,000多个训练样本和5,000多个评估样本。
CMM-Math is a Chinese multimodal mathematics dataset containing over 28,000 high-quality samples. It covers 12 grade levels from primary school to senior high school, with diverse question types including multiple-choice questions, fill-in-the-blank questions and more, and is accompanied by detailed solutions. Questions in the dataset may contain visual contexts, which makes them more challenging. The dataset is split into training and evaluation subsets, with over 22,000 training samples and more than 5,000 evaluation samples respectively.
创建时间:
2024-09-06
原始信息汇总
CMM-Math 数据集概述
基本信息
- 许可证: BSD-3-Clause
- 语言: 中文
- 任务类型: 文本生成
数据集介绍
- 名称: CMM-Math
- 内容: 一个中文多模态数学数据集,包含基准测试和训练部分,用于评估和增强大型多模态模型(LMMs)的数学推理能力。
- 样本数量: 超过28,000个高质量样本
- 问题类型: 包括多种题型,如选择题、填空题等。
- 适用年级: 涵盖从小学到高中12个年级。
- 特点: 问题或解答中可能包含视觉上下文,增加了数据集的挑战性。
数据集结构
- 训练样本: 22,000+
- 评估样本: 5,000+
相关论文
- 标题: CMM-Math: A Chinese Multimodal Math Dataset To Evaluate and Enhance the Mathematics Reasoning of Large Multimodal Models
- 作者: Liu, Wentao 等
- 发表: arXiv preprint arXiv:2409.02834
示例
- 数据集示例: 包含多个示例图像,展示了不同学科和不同年级的结果。
AI搜集汇总
数据集介绍
构建方式
CMM-Math数据集的构建旨在评估和增强大型多模态模型(LMMs)在数学推理方面的能力。该数据集包含超过28,000个高质量样本,涵盖了中国从小学到高中的12个年级的多种题型(如选择题、填空题等),并配有详细的解答。数据集的视觉上下文可能出现在问题或观点中,增加了数据集的复杂性。通过综合分析,研究人员发现当前最先进的LMMs在CMM-Math数据集上仍面临挑战,表明LMMs的开发仍需进一步改进。
使用方法
CMM-Math数据集的使用方法主要包括模型的训练和评估。研究人员可以利用数据集中的22,000多个训练样本对LMMs进行训练,以提升其在数学推理任务中的表现。随后,使用5,000多个评估样本对模型进行测试,以评估其在不同题型和年级层次上的表现。通过这种方式,研究人员可以全面了解模型的优缺点,并为进一步的模型改进提供依据。
背景与挑战
背景概述
CMM-Math数据集由华东师范大学智能计算与知识工程实验室(ICALK)于2024年发布,旨在评估和提升大型多模态模型(LMMs)在数学推理任务中的表现。该数据集包含超过28,000个高质量样本,涵盖从小学到高中的12个年级,问题类型多样,包括选择题、填空题等,并附有详细解答。CMM-Math的独特之处在于其多模态特性,问题中可能包含视觉上下文,这为模型的理解和推理能力提出了更高要求。该数据集的发布填补了中文多模态数学数据集的空白,为相关领域的研究提供了重要资源。
当前挑战
CMM-Math数据集在解决数学推理问题时面临多重挑战。首先,多模态数据的融合要求模型能够同时处理文本和视觉信息,这对模型的跨模态理解能力提出了较高要求。其次,数据集涵盖的年级跨度较大,问题难度差异显著,模型需要在不同难度级别上保持一致的推理能力。此外,数据集中包含的视觉上下文可能以多种形式出现,如图表、公式或几何图形,这进一步增加了问题的复杂性。在数据构建过程中,确保样本的高质量和多样性也是一大挑战,尤其是在标注和验证过程中需要兼顾准确性和一致性。这些挑战凸显了当前多模态模型在数学推理任务中的局限性,也为未来的研究指明了方向。
常用场景
经典使用场景
CMM-Math数据集主要用于评估和增强大型多模态模型(LMMs)在数学推理任务中的表现。该数据集包含超过28,000个高质量样本,涵盖从小学到高中的12个年级,问题类型多样,包括选择题、填空题等,且每个问题都附有详细的解答。通过引入视觉上下文,该数据集进一步提升了任务的挑战性,使其成为研究多模态数学推理的理想工具。
解决学术问题
CMM-Math数据集解决了当前多模态数学推理研究中缺乏高质量中文数据集的问题。通过提供丰富的视觉和文本信息,该数据集为研究者提供了一个标准化的评估平台,能够有效衡量LMMs在复杂数学问题上的表现。此外,该数据集还揭示了现有模型在处理多模态数学问题时的局限性,为未来的模型改进指明了方向。
实际应用
CMM-Math数据集在实际应用中具有广泛的前景,尤其是在教育技术领域。通过利用该数据集,开发者可以训练和优化智能教育系统,使其能够更好地理解和解答学生的数学问题。此外,该数据集还可用于开发个性化学习工具,帮助学生根据自身的学习进度和理解能力进行针对性练习。
数据集最近研究
最新研究方向
随着大语言模型(LLMs)在数学推理领域的显著进展,研究者们逐渐将目光转向多模态数学数据集,以评估和提升大模型在复杂情境下的推理能力。CMM-Math数据集的发布填补了中文多模态数学数据领域的空白,其包含超过28,000个高质量样本,涵盖从小学到高中的12个年级,题型多样且附带详细解答。这一数据集不仅包含文本信息,还融入了视觉上下文,使得问题更具挑战性。近期研究表明,当前最先进的多模态模型在CMM-Math数据集上仍面临显著困难,凸显了进一步优化模型在跨模态推理和复杂问题解决能力上的迫切需求。CMM-Math的发布为中文数学教育智能化提供了重要支持,同时也推动了多模态模型在数学推理领域的研究与应用。
以上内容由AI搜集并总结生成


