PMOA-TTS
收藏arXiv2025-05-24 更新2025-05-29 收录
下载链接:
https://huggingface.co/datasets/snoroozi/pmoa-tts
下载链接
链接失效反馈官方服务:
资源简介:
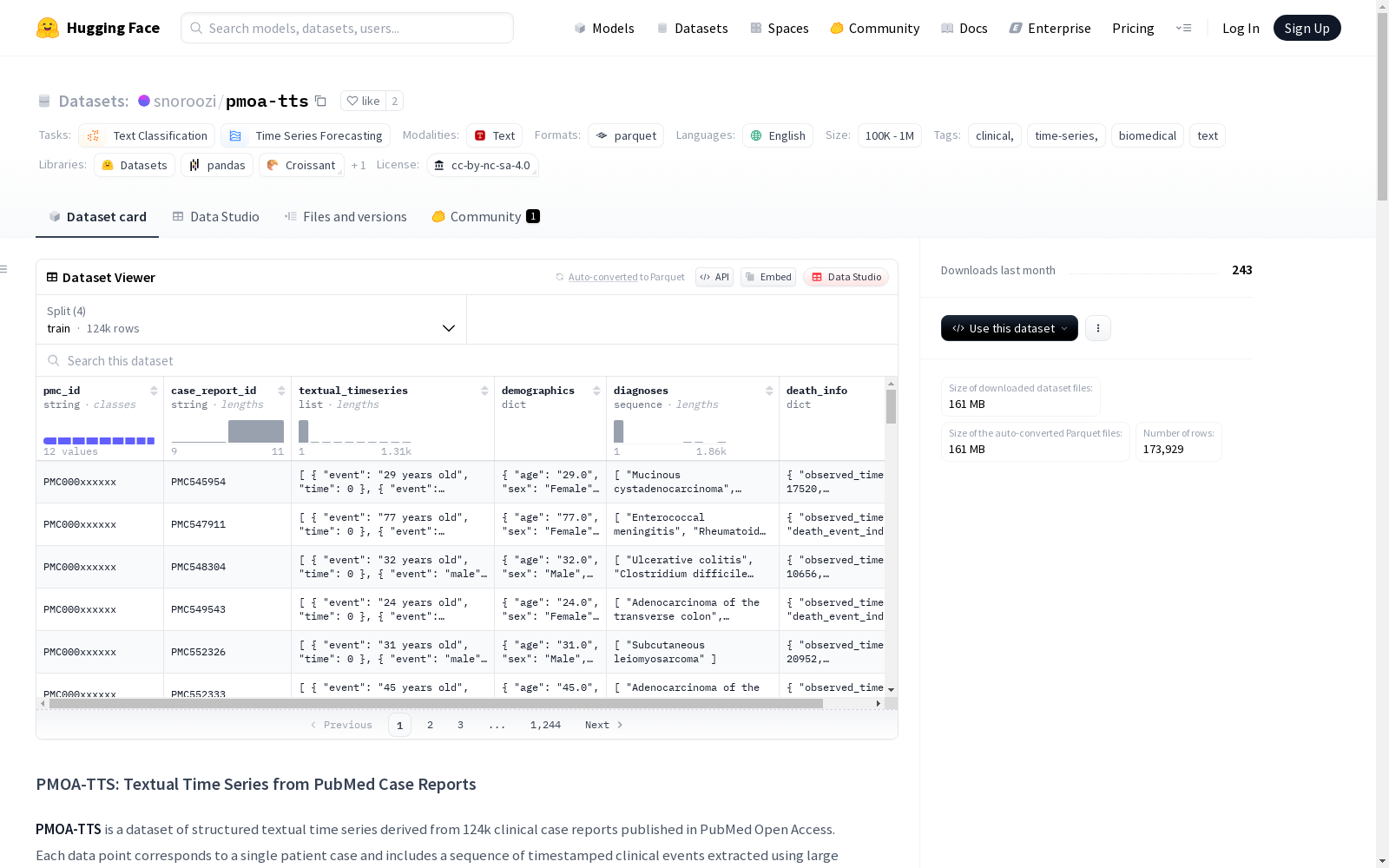
PMOA-TTS数据集由卡内基梅隆大学机器学习系、信息系統与公共政策学院、美国国立卫生研究院国家医学图书馆的研究人员创建,包含124,699份来自PubMed Open Access的病例报告,每份报告都通过可扩展的基于大型语言模型(LLM)的管道转换为结构化的(事件,时间)时间序列。该数据集通过启发式过滤和Llama 3.3识别单个患者的病例报告,并使用Llama 3.3和DeepSeek R1进行提示驱动提取,最终生成了超过560万个带时间戳的临床事件。该数据集在临床和人口统计覆盖范围广泛,并在下游生存预测任务中表现出色,嵌入从提取的时间序列中获得的预测性能可达0.82 ± 0.01。PMOA–TTS为时间线提取、时间推理和纵向建模提供了可扩展的基础,可用于生物医学自然语言处理。数据集可在Hugging Face平台上获取。
PMOA-TTS was developed by researchers from the Department of Machine Learning, Heinz College of Information Systems and Public Policy, Carnegie Mellon University, and the National Library of Medicine, National Institutes of Health. It contains 124,699 case reports sourced from PubMed Open Access. Each report was converted into a structured (event, time) time series via a scalable large language model (LLM)-based pipeline. This dataset identifies single-patient case reports through heuristic filtering and Llama 3.3, and uses Llama 3.3 and DeepSeek R1 for prompt-driven extraction, ultimately generating over 5.6 million timestamped clinical events. The dataset features broad clinical and demographic coverage, and performs excellently on downstream survival prediction tasks: the predictive performance derived from embeddings of the extracted time series reaches 0.82 ± 0.01. PMOA-TTS provides a scalable foundation for timeline extraction, temporal reasoning, and longitudinal modeling for biomedical natural language processing, and is available on the Hugging Face platform.
提供机构:
卡内基梅隆大学机器学习系、信息系統与公共政策学院、美国国立卫生研究院国家医学图书馆
创建时间:
2025-05-24
搜集汇总
数据集介绍
构建方式
PMOA-TTS数据集的构建采用了基于大型语言模型(LLM)的可扩展流程,从PubMed开放获取的临床病例报告中提取结构化时间序列。首先通过启发式过滤和Llama 3.3模型识别单病例报告,随后利用Llama 3.3和DeepSeek R1模型进行提示驱动的时序事件提取,最终形成包含560万条时间戳临床事件的语料库。为确保时间线质量,研究团队采用三项指标与临床专家标注的参考集进行比对:事件级匹配(余弦相似度阈值0.1时匹配率达80%)、时序一致性(c-index>0.90)以及时间戳对齐的对数时间累积分布函数面积(AULTC)。
特点
该数据集的核心特点体现在其规模性与时序结构化深度。作为目前最大的公开临床叙事时间序列资源,PMOA-TTS涵盖124,699例病例报告,覆盖广泛的诊断类别与人口统计学特征。其创新性在于将自由文本临床描述转化为(事件,时间)元组序列,保留了原始临床表述的语义细微差异。语料库分析显示,高血压谱系疾病、糖尿病及其亚型构成高频诊断,且疾病共现模式与临床实践高度吻合。时序嵌入在生存预测任务中展现出显著价值,时间依赖性一致性指数最高达0.82±0.01。
使用方法
使用PMOA-TTS需遵循三步范式:首先通过HuggingFace平台获取预处理后的结构化时间序列数据;其次可利用诊断标签或人口统计学元数据构建特定疾病队列;最终应用于时序建模任务时,建议采用两阶段框架——先通过预训练语言模型(如LLaMA 3.3或DeepSeek)生成事件嵌入,再输入至生存分析模型(DeepSurv/DeepHit)。研究证明,解码器架构模型在时序预测任务中表现优异,70B参数规模的LLaMA 3.3模型在事件排序任务中c-index达0.96。对于时间敏感型研究,推荐使用AULTC指标评估模型的时间戳预测精度。
背景与挑战
背景概述
PMOA-TTS数据集由卡内基梅隆大学机器学习系与美国国立卫生研究院国家医学图书馆的研究团队于2025年联合发布,是首个基于PubMed开放获取病例报告构建的大规模临床时间序列语料库。该数据集包含124,699份单病例报告,通过Llama 3.3和DeepSeek R1等大语言模型构建的自动化流程,提取了超过560万条带时间戳的临床事件。其核心研究目标是解决临床叙事中时间动态建模的数据稀缺问题,为患者轨迹建模、过程挖掘和结果预测等任务提供结构化时间序列数据。相较于MIMIC-III等传统电子健康记录数据集,PMOA-TTS通过转化病例报告的相对时间表达为标准化时间戳,显著扩展了时序临床NLP研究的可能性。
当前挑战
PMOA-TTS面临双重挑战:在领域问题层面,需解决临床文本中非结构化时间表达(如'入院第3天')到标准化时间戳的转换难题,这对时序推理模型的细粒度理解能力提出极高要求;在构建过程层面,挑战包括从海量文献中精准识别单病例报告(需区分病例报告与病例系列),处理临床事件描述的语义变体(如'胸痛放射至胸骨下'的复杂表述),以及验证LLM生成时间戳的可靠性(通过事件级匹配、时序一致性指数等创新指标)。此外,病例报告固有的叙述风格差异与时间表达模糊性,进一步增加了时序标注的复杂性。
常用场景
经典使用场景
PMOA-TTS数据集在临床自然语言处理领域具有广泛的应用价值,特别是在患者轨迹建模和时间序列分析方面。该数据集通过将PubMed开放获取的病例报告转化为结构化的(事件,时间)时间线,为研究人员提供了一个大规模、高质量的资源。其经典使用场景包括临床事件的时间关系提取、患者病程的预测建模以及医疗决策支持系统的开发。通过利用大型语言模型(如Llama 3.3和DeepSeek R1)进行时间线提取,PMOA-TTS能够捕捉到丰富的临床事件及其时间顺序,为时间推理任务提供了坚实的基础。
衍生相关工作
PMOA-TTS数据集已经衍生出多项相关研究工作。例如,基于该数据集的生存分析任务展示了时间结构化叙事在预测患者结局中的有效性。此外,相关工作还探索了临床事件预测任务,如使用LLM生成的文本时间序列进行未来事件的时间和顺序预测。这些研究不仅验证了PMOA-TTS的实用价值,还为进一步的时间推理模型开发提供了基准。数据集的开源特性也促进了更多跨学科合作,推动了临床NLP与机器学习、时间序列分析等领域的融合。
数据集最近研究
最新研究方向
在临床自然语言处理领域,PMOA-TTS数据集的推出为患者轨迹建模和时序推理研究开辟了新方向。该数据集通过大规模语言模型(LLMs)从PubMed开放获取的病例报告中提取结构化时间序列,解决了临床叙事中显性时间标注资源稀缺的核心挑战。当前研究热点集中在三个方向:一是开发基于LLM的可扩展时序标注管道,通过启发式过滤与提示驱动提取相结合的方法,实现超过560万时间戳临床事件的高效标注;二是在生存预测等下游任务中验证时序结构的预测价值,嵌入提取的时间线在时间依赖性一致性指数上达到0.82±0.01的优异表现;三是探索跨诊断和人口统计学群体的时序模式分析,数据集覆盖广泛的临床专业领域和人口特征,为疾病进展建模提供丰富资源。该数据集的出现显著推进了生物医学NLP中时间线提取、时序推理和纵向建模的研究边界,并为临床过程挖掘、结果预测和因果推断等关键任务提供了新的基准平台。
相关研究论文
- 1PMOA-TTS: Introducing the PubMed Open Access Textual Times Series Corpus卡内基梅隆大学机器学习系、信息系統与公共政策学院、美国国立卫生研究院国家医学图书馆 · 2025年
以上内容由遇见数据集搜集并总结生成


